 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLove Me, Love Me, Say that You Love Me: Enriching the WASABI Song Corpus with Lyrics Annotations
Dec 05, 2019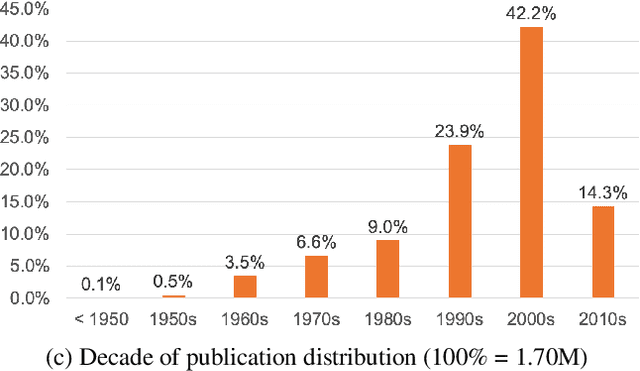
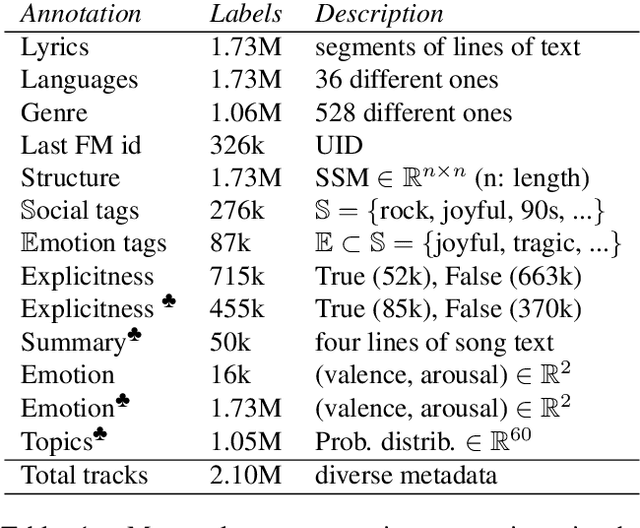

We present the WASABI Song Corpus, a large corpus of songs enriched with metadata extracted from music databases on the Web, and resulting from the processing of song lyrics and from audio analysis. More specifically, given that lyrics encode an important part of the semantics of a song, we focus here on the description of the methods we proposed to extract relevant information from the lyrics, such as their structure segmentation, their topics, the explicitness of the lyrics content, the salient passages of a song and the emotions conveyed. The creation of the resource is still ongoing: so far, the corpus contains 1.73M songs with lyrics (1.41M unique lyrics) annotated at different levels with the output of the above mentioned methods. Such corpus labels and the provided methods can be exploited by music search engines and music professionals (e.g. journalists, radio presenters) to better handle large collections of lyrics, allowing an intelligent browsing, categorization and segmentation recommendation of songs.
Graph Data on the Web: extend the pivot, don't reinvent the wheel
Mar 11, 2019This article is a collective position paper from the Wimmics research team, expressing our vision of how Web graph data technologies should evolve in the future in order to ensure a high-level of interoperability between the many types of applications that produce and consume graph data. Wimmics stands for Web-Instrumented Man-Machine Interactions, Communities, and Semantics. We are a joint research team between INRIA Sophia Antipolis-M{\'e}diterran{\'e}e and I3S (CNRS and Universit{\'e} C{\^o}te d'Azur). Our challenge is to bridge formal semantics and social semantics on the web. Our research areas are graph-oriented knowledge representation, reasoning and operationalization to model and support actors, actions and interactions in web-based epistemic communities. The application of our research is supporting and fostering interactions in online communities and management of their resources. In this position paper, we emphasize the need to extend the semantic Web standard stack to address and fulfill new graph data needs, as well as the importance of remaining compatible with existing recommendations, in particular the RDF stack, to avoid the painful duplication of models, languages, frameworks, etc. The following sections group motivations for different directions of work and collect reasons for the creation of a working group on RDF 2.0 and other recommendations of the RDF family.
Challenges in Bridging Social Semantics and Formal Semantics on the Web
Aug 29, 2014This paper describes several results of Wimmics, a research lab which names stands for: web-instrumented man-machine interactions, communities, and semantics. The approaches introduced here rely on graph-oriented knowledge representation, reasoning and operationalization to model and support actors, actions and interactions in web-based epistemic communities. The re-search results are applied to support and foster interactions in online communities and manage their resources.
Semantic Social Network Analysis
Apr 23, 2009
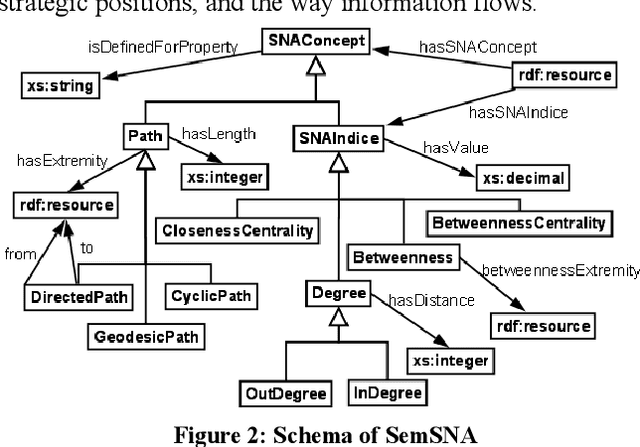
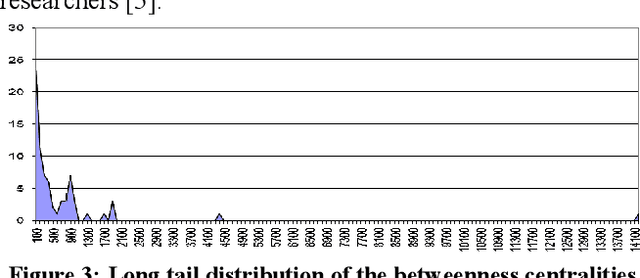
Social Network Analysis (SNA) tries to understand and exploit the key features of social networks in order to manage their life cycle and predict their evolution. Increasingly popular web 2.0 sites are forming huge social network. Classical methods from social network analysis (SNA) have been applied to such online networks. In this paper, we propose leveraging semantic web technologies to merge and exploit the best features of each domain. We present how to facilitate and enhance the analysis of online social networks, exploiting the power of semantic social network analysis.