 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Meta-Learning Approach to One-Step Active Learning
Jul 17, 2017
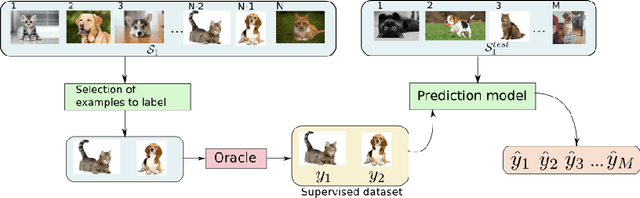
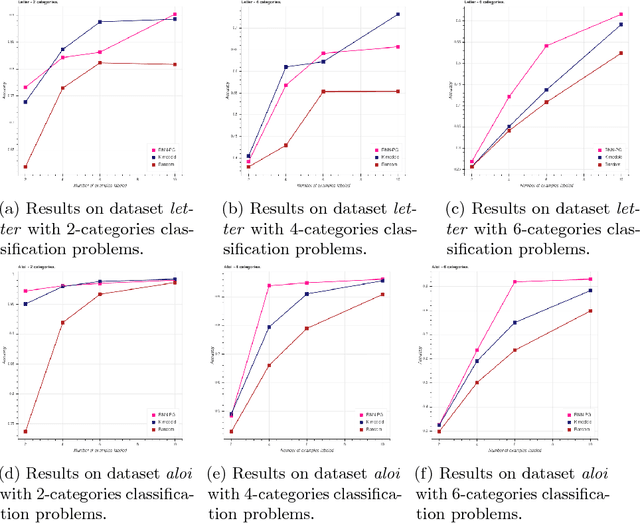
We consider the problem of learning when obtaining the training labels is costly, which is usually tackled in the literature using active-learning techniques. These approaches provide strategies to choose the examples to label before or during training. These strategies are usually based on heuristics or even theoretical measures, but are not learned as they are directly used during training. We design a model which aims at \textit{learning active-learning strategies} using a meta-learning setting. More specifically, we consider a pool-based setting, where the system observes all the examples of the dataset of a problem and has to choose the subset of examples to label in a single shot. Experiments show encouraging results.
Representation Learning for cold-start recommendation
Jun 22, 2015
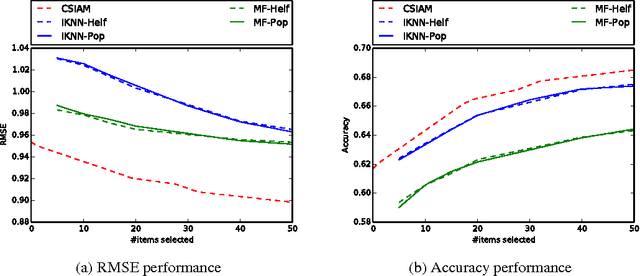
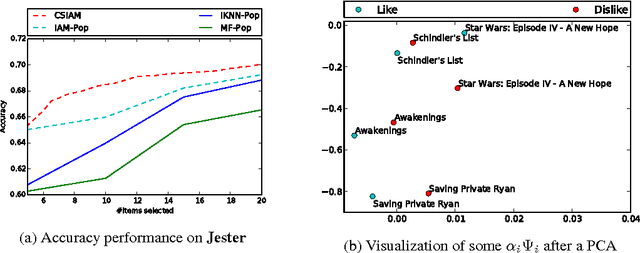
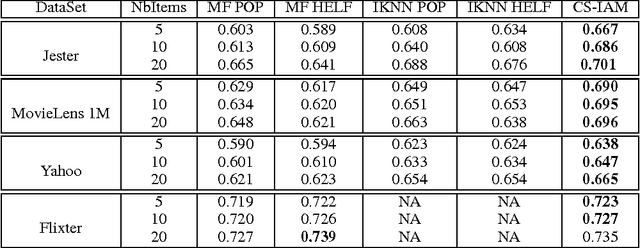
A standard approach to Collaborative Filtering (CF), i.e. prediction of user ratings on items, relies on Matrix Factorization techniques. Representations for both users and items are computed from the observed ratings and used for prediction. Unfortunatly, these transductive approaches cannot handle the case of new users arriving in the system, with no known rating, a problem known as user cold-start. A common approach in this context is to ask these incoming users for a few initialization ratings. This paper presents a model to tackle this twofold problem of (i) finding good questions to ask, (ii) building efficient representations from this small amount of information. The model can also be used in a more standard (warm) context. Our approach is evaluated on the classical CF problem and on the cold-start problem on four different datasets showing its ability to improve baseline performance in both cases.
LSHTC: A Benchmark for Large-Scale Text Classification
Mar 30, 2015
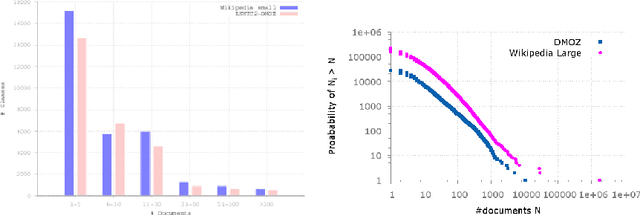
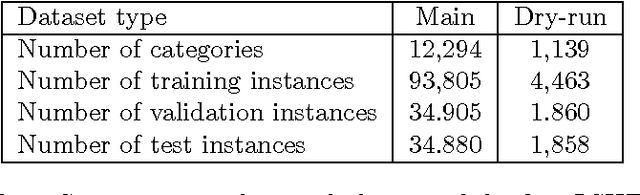
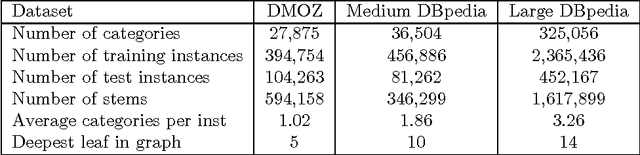
LSHTC is a series of challenges which aims to assess the performance of classification systems in large-scale classification in a a large number of classes (up to hundreds of thousands). This paper describes the dataset that have been released along the LSHTC series. The paper details the construction of the datsets and the design of the tracks as well as the evaluation measures that we implemented and a quick overview of the results. All of these datasets are available online and runs may still be submitted on the online server of the challenges.
Learning States Representations in POMDP
Jun 17, 2014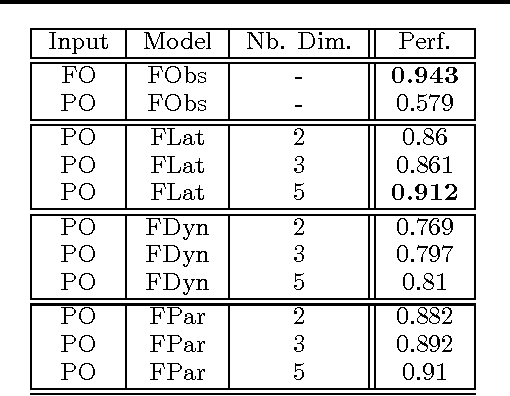
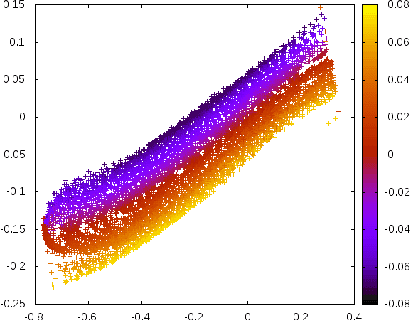
We propose to deal with sequential processes where only partial observations are available by learning a latent representation space on which policies may be accurately learned.