 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Cascading for Large Scale Hierarchical Classification
May 09, 2015
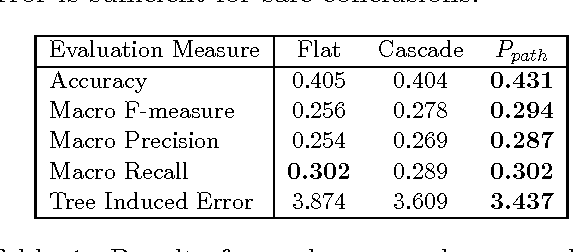
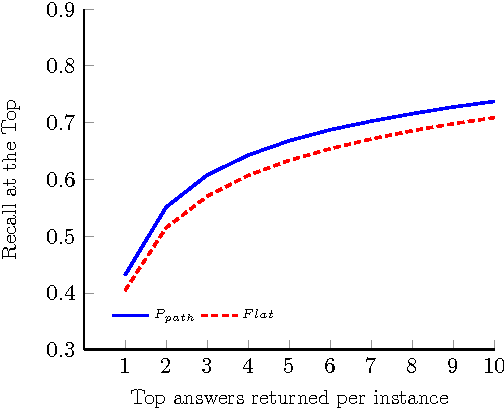
Hierarchies are frequently used for the organization of objects. Given a hierarchy of classes, two main approaches are used, to automatically classify new instances: flat classification and cascade classification. Flat classification ignores the hierarchy, while cascade classification greedily traverses the hierarchy from the root to the predicted leaf. In this paper we propose a new approach, which extends cascade classification to predict the right leaf by estimating the probability of each root-to-leaf path. We provide experimental results which indicate that, using the same classification algorithm, one can achieve better results with our approach, compared to the traditional flat and cascade classifications.
LSHTC: A Benchmark for Large-Scale Text Classification
Mar 30, 2015
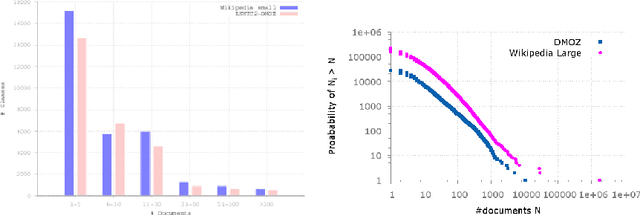
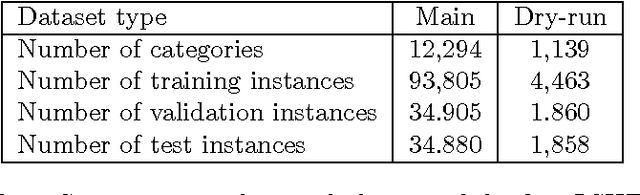
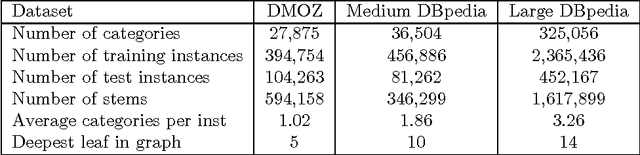
LSHTC is a series of challenges which aims to assess the performance of classification systems in large-scale classification in a a large number of classes (up to hundreds of thousands). This paper describes the dataset that have been released along the LSHTC series. The paper details the construction of the datsets and the design of the tracks as well as the evaluation measures that we implemented and a quick overview of the results. All of these datasets are available online and runs may still be submitted on the online server of the challenges.
Evaluation Measures for Hierarchical Classification: a unified view and novel approaches
Jul 01, 2013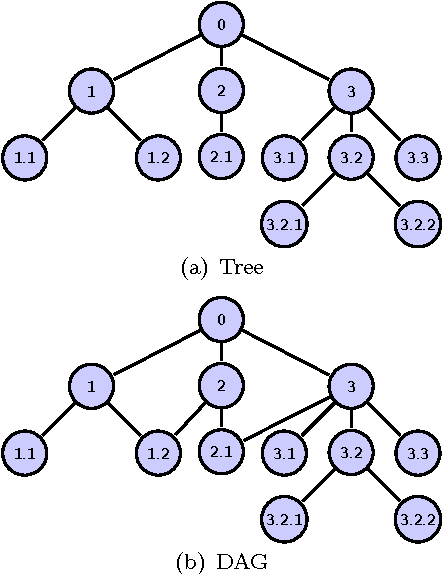

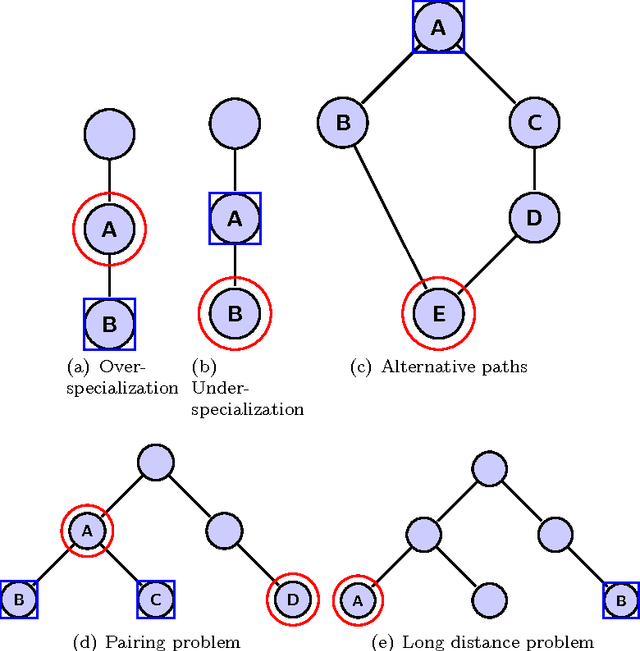
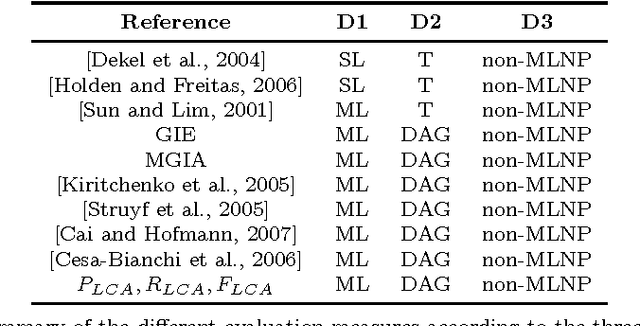
Hierarchical classification addresses the problem of classifying items into a hierarchy of classes. An important issue in hierarchical classification is the evaluation of different classification algorithms, which is complicated by the hierarchical relations among the classes. Several evaluation measures have been proposed for hierarchical classification using the hierarchy in different ways. This paper studies the problem of evaluation in hierarchical classification by analyzing and abstracting the key components of the existing performance measures. It also proposes two alternative generic views of hierarchical evaluation and introduces two corresponding novel measures. The proposed measures, along with the state-of-the art ones, are empirically tested on three large datasets from the domain of text classification. The empirical results illustrate the undesirable behavior of existing approaches and how the proposed methods overcome most of these methods across a range of cases.