 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Spatial-Temporal and Appearance Modeling with Transformer for Multiple Object Tracking
May 31, 2022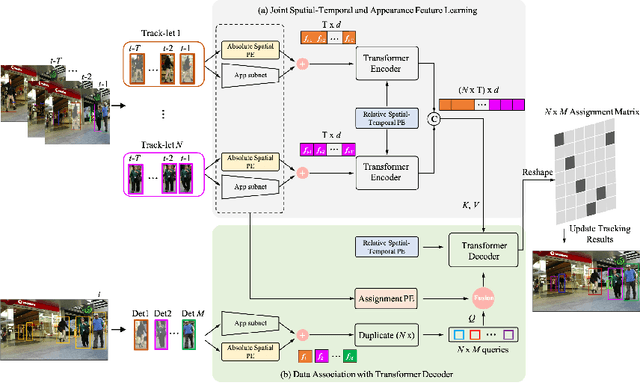

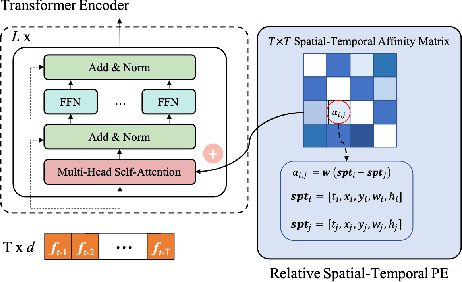
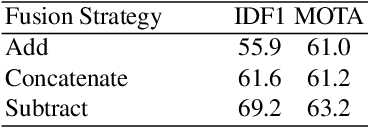
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. In this paper, we propose a novel solution named TransSTAM, which leverages Transformer to effectively model both the appearance features of each object and the spatial-temporal relationships among objects. TransSTAM consists of two major parts: (1) The encoder utilizes the powerful self-attention mechanism of Transformer to learn discriminative features for each tracklet; (2) The decoder adopts the standard cross-attention mechanism to model the affinities between the tracklets and the detections by taking both spatial-temporal and appearance features into account. TransSTAM has two major advantages: (1) It is solely based on the encoder-decoder architecture and enjoys a compact network design, hence being computationally efficient; (2) It can effectively learn spatial-temporal and appearance features within one model, hence achieving better tracking accuracy. The proposed method is evaluated on multiple public benchmarks including MOT16, MOT17, and MOT20, and it achieves a clear performance improvement in both IDF1 and HOTA with respect to previous state-of-the-art approaches on all the benchmarks. Our code is available at \url{https://github.com/icicle4/TranSTAM}.
Ray3D: ray-based 3D human pose estimation for monocular absolute 3D localization
Mar 30, 2022

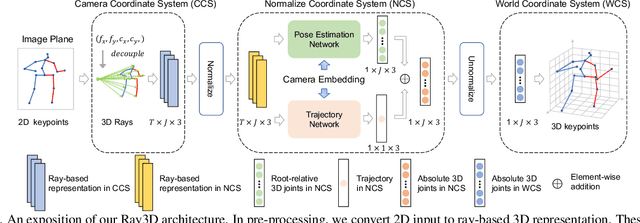

In this paper, we propose a novel monocular ray-based 3D (Ray3D) absolute human pose estimation with calibrated camera. Accurate and generalizable absolute 3D human pose estimation from monocular 2D pose input is an ill-posed problem. To address this challenge, we convert the input from pixel space to 3D normalized rays. This conversion makes our approach robust to camera intrinsic parameter changes. To deal with the in-the-wild camera extrinsic parameter variations, Ray3D explicitly takes the camera extrinsic parameters as an input and jointly models the distribution between the 3D pose rays and camera extrinsic parameters. This novel network design is the key to the outstanding generalizability of Ray3D approach. To have a comprehensive understanding of how the camera intrinsic and extrinsic parameter variations affect the accuracy of absolute 3D key-point localization, we conduct in-depth systematic experiments on three single person 3D benchmarks as well as one synthetic benchmark. These experiments demonstrate that our method significantly outperforms existing state-of-the-art models. Our code and the synthetic dataset are available at https://github.com/YxZhxn/Ray3D .
3SD: Self-Supervised Saliency Detection With No Labels
Mar 09, 2022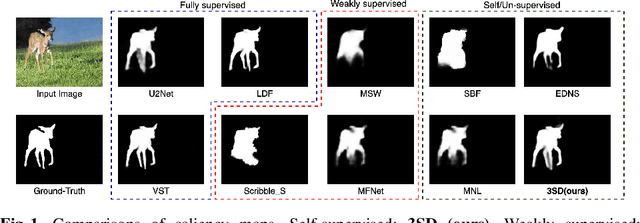
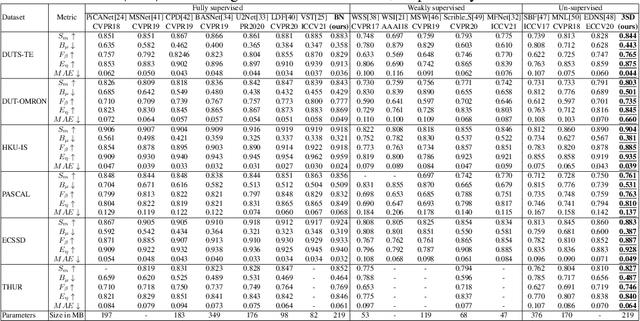

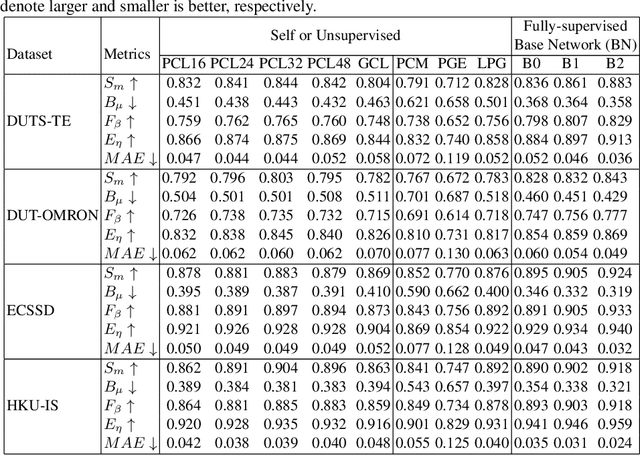
We present a conceptually simple self-supervised method for saliency detection. Our method generates and uses pseudo-ground truth labels for training. The generated pseudo-GT labels don't require any kind of human annotations (e.g., pixel-wise labels or weak labels like scribbles). Recent works show that features extracted from classification tasks provide important saliency cues like structure and semantic information of salient objects in the image. Our method, called 3SD, exploits this idea by adding a branch for a self-supervised classification task in parallel with salient object detection, to obtain class activation maps (CAM maps). These CAM maps along with the edges of the input image are used to generate the pseudo-GT saliency maps to train our 3SD network. Specifically, we propose a contrastive learning-based training on multiple image patches for the classification task. We show the multi-patch classification with contrastive loss improves the quality of the CAM maps compared to naive classification on the entire image. Experiments on six benchmark datasets demonstrate that without any labels, our 3SD method outperforms all existing weakly supervised and unsupervised methods, and its performance is on par with the fully-supervised methods. Code is available at :https://github.com/rajeevyasarla/3SD
IIP-Transformer: Intra-Inter-Part Transformer for Skeleton-Based Action Recognition
Oct 26, 2021

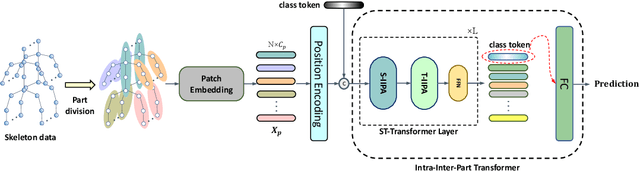

Recently, Transformer-based networks have shown great promise on skeleton-based action recognition tasks. The ability to capture global and local dependencies is the key to success while it also brings quadratic computation and memory cost. Another problem is that previous studies mainly focus on the relationships among individual joints, which often suffers from the noisy skeleton joints introduced by the noisy inputs of sensors or inaccurate estimations. To address the above issues, we propose a novel Transformer-based network (IIP-Transformer). Instead of exploiting interactions among individual joints, our IIP-Transformer incorporates body joints and parts interactions simultaneously and thus can capture both joint-level (intra-part) and part-level (inter-part) dependencies efficiently and effectively. From the data aspect, we introduce a part-level skeleton data encoding that significantly reduces the computational complexity and is more robust to joint-level skeleton noise. Besides, a new part-level data augmentation is proposed to improve the performance of the model. On two large-scale datasets, NTU-RGB+D 60 and NTU RGB+D 120, the proposed IIP-Transformer achieves the-state-of-art performance with more than 8x less computational complexity than DSTA-Net, which is the SOTA Transformer-based method.
Learning a Proposal Classifier for Multiple Object Tracking
Mar 26, 2021
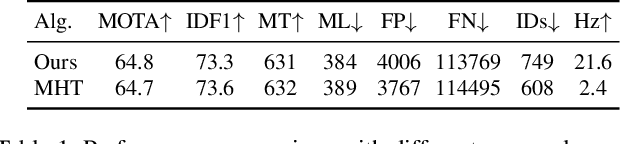
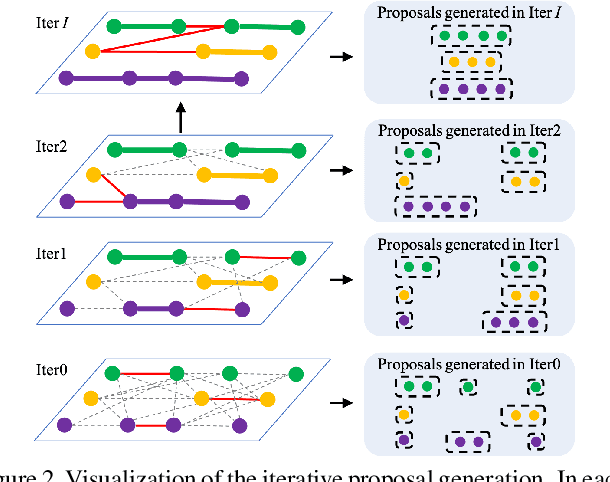
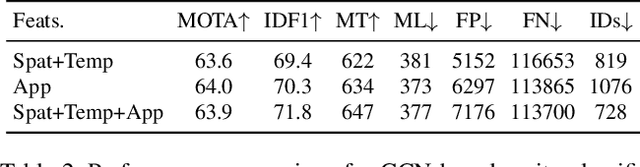
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. However, it is not trivial to solve the data-association problem in an end-to-end fashion. In this paper, we propose a novel proposal-based learnable framework, which models MOT as a proposal generation, proposal scoring and trajectory inference paradigm on an affinity graph. This framework is similar to the two-stage object detector Faster RCNN, and can solve the MOT problem in a data-driven way. For proposal generation, we propose an iterative graph clustering method to reduce the computational cost while maintaining the quality of the generated proposals. For proposal scoring, we deploy a trainable graph-convolutional-network (GCN) to learn the structural patterns of the generated proposals and rank them according to the estimated quality scores. For trajectory inference, a simple deoverlapping strategy is adopted to generate tracking output while complying with the constraints that no detection can be assigned to more than one track. We experimentally demonstrate that the proposed method achieves a clear performance improvement in both MOTA and IDF1 with respect to previous state-of-the-art on two public benchmarks. Our code is available at https://github.com/daip13/LPC_MOT.git.