 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulX-FlashTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Jan 06, 2026Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-FlashTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-FlashTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
SoulX-LiveTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Dec 31, 2025Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-LiveTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-LiveTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
TPT-Bench: A Large-Scale, Long-Term and Robot-Egocentric Dataset for Benchmarking Target Person Tracking
May 12, 2025Tracking a target person from robot-egocentric views is crucial for developing autonomous robots that provide continuous personalized assistance or collaboration in Human-Robot Interaction (HRI) and Embodied AI. However, most existing target person tracking (TPT) benchmarks are limited to controlled laboratory environments with few distractions, clean backgrounds, and short-term occlusions. In this paper, we introduce a large-scale dataset designed for TPT in crowded and unstructured environments, demonstrated through a robot-person following task. The dataset is collected by a human pushing a sensor-equipped cart while following a target person, capturing human-like following behavior and emphasizing long-term tracking challenges, including frequent occlusions and the need for re-identification from numerous pedestrians. It includes multi-modal data streams, including odometry, 3D LiDAR, IMU, panoptic, and RGB-D images, along with exhaustively annotated 2D bounding boxes of the target person across 35 sequences, both indoors and outdoors. Using this dataset and visual annotations, we perform extensive experiments with existing TPT methods, offering a thorough analysis of their limitations and suggesting future research directions.
Monocular Person Localization under Camera Ego-motion
Mar 04, 2025Localizing a person from a moving monocular camera is critical for Human-Robot Interaction (HRI). To estimate the 3D human position from a 2D image, existing methods either depend on the geometric assumption of a fixed camera or use a position regression model trained on datasets containing little camera ego-motion. These methods are vulnerable to fierce camera ego-motion, resulting in inaccurate person localization. We consider person localization as a part of a pose estimation problem. By representing a human with a four-point model, our method jointly estimates the 2D camera attitude and the person's 3D location through optimization. Evaluations on both public datasets and real robot experiments demonstrate our method outperforms baselines in person localization accuracy. Our method is further implemented into a person-following system and deployed on an agile quadruped robot.
RPF-Search: Field-based Search for Robot Person Following in Unknown Dynamic Environments
Mar 04, 2025Autonomous robot person-following (RPF) systems are crucial for personal assistance and security but suffer from target loss due to occlusions in dynamic, unknown environments. Current methods rely on pre-built maps and assume static environments, limiting their effectiveness in real-world settings. There is a critical gap in re-finding targets under topographic (e.g., walls, corners) and dynamic (e.g., moving pedestrians) occlusions. In this paper, we propose a novel heuristic-guided search framework that dynamically builds environmental maps while following the target and resolves various occlusions by prioritizing high-probability areas for locating the target. For topographic occlusions, a belief-guided search field is constructed and used to evaluate the likelihood of the target's presence, while for dynamic occlusions, a fluid-field approach allows the robot to adaptively follow or overtake moving occluders. Past motion cues and environmental observations refine the search decision over time. Our results demonstrate that the proposed method outperforms existing approaches in terms of search efficiency and success rates, both in simulations and real-world tests. Our target search method enhances the adaptability and reliability of RPF systems in unknown and dynamic environments to support their use in real-world applications. Our code, video, experimental results and appendix are available at https://medlartea.github.io/rpf-search/.
Human Orientation Estimation under Partial Observation
Apr 22, 2024Reliable human orientation estimation (HOE) is critical for autonomous agents to understand human intention and perform human-robot interaction (HRI) tasks. Great progress has been made in HOE under full observation. However, the existing methods easily make a wrong prediction under partial observation and give it an unexpectedly high probability. To solve the above problems, this study first develops a method that estimates orientation from the visible joints of a target person so that it is able to handle partial observation. Subsequently, we introduce a confidence-aware orientation estimation method, enabling more accurate orientation estimation and reasonable confidence estimation under partial observation. The effectiveness of our method is validated on both public and custom-built datasets, and it showed great accuracy and reliability improvement in partial observation scenarios. In particular, we show in real experiments that our method can benefit the robustness and consistency of the robot person following (RPF) task.
Person Re-Identification for Robot Person Following with Online Continual Learning
Sep 21, 2023Robot person following (RPF) is a crucial capability in human-robot interaction (HRI) applications, allowing a robot to persistently follow a designated person. In practical RPF scenarios, the person often be occluded by other objects or people. Consequently, it is necessary to re-identify the person when he/she re-appears within the robot's field of view. Previous person re-identification (ReID) approaches to person following rely on offline-trained features and short-term experiences. Such an approach i) has a limited capacity to generalize across scenarios; and ii) often fails to re-identify the person when his re-appearance is out of the learned domain represented by the short-term experiences. Based on this observation, in this work, we propose a ReID framework for RPF that leverages long-term experiences. The experiences are maintained by a loss-guided keyframe selection strategy, to enable online continual learning of the appearance model. Our experiments demonstrate that even in the presence of severe appearance changes and distractions from visually similar people, the proposed method can still re-identify the person more accurately than the state-of-the-art methods.
HyperAttack: Multi-Gradient-Guided White-box Adversarial Structure Attack of Hypergraph Neural Networks
Feb 24, 2023

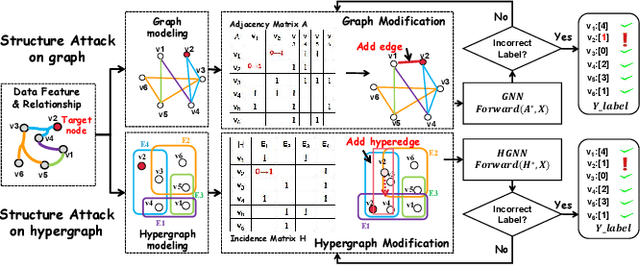

Hypergraph neural networks (HGNN) have shown superior performance in various deep learning tasks, leveraging the high-order representation ability to formulate complex correlations among data by connecting two or more nodes through hyperedge modeling. Despite the well-studied adversarial attacks on Graph Neural Networks (GNN), there is few study on adversarial attacks against HGNN, which leads to a threat to the safety of HGNN applications. In this paper, we introduce HyperAttack, the first white-box adversarial attack framework against hypergraph neural networks. HyperAttack conducts a white-box structure attack by perturbing hyperedge link status towards the target node with the guidance of both gradients and integrated gradients. We evaluate HyperAttack on the widely-used Cora and PubMed datasets and three hypergraph neural networks with typical hypergraph modeling techniques. Compared to state-of-the-art white-box structural attack methods for GNN, HyperAttack achieves a 10-20X improvement in time efficiency while also increasing attack success rates by 1.3%-3.7%. The results show that HyperAttack can achieve efficient adversarial attacks that balance effectiveness and time costs.
Ray3D: ray-based 3D human pose estimation for monocular absolute 3D localization
Mar 30, 2022

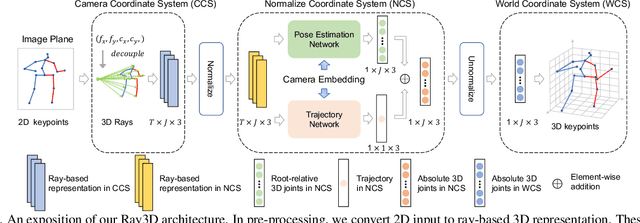

In this paper, we propose a novel monocular ray-based 3D (Ray3D) absolute human pose estimation with calibrated camera. Accurate and generalizable absolute 3D human pose estimation from monocular 2D pose input is an ill-posed problem. To address this challenge, we convert the input from pixel space to 3D normalized rays. This conversion makes our approach robust to camera intrinsic parameter changes. To deal with the in-the-wild camera extrinsic parameter variations, Ray3D explicitly takes the camera extrinsic parameters as an input and jointly models the distribution between the 3D pose rays and camera extrinsic parameters. This novel network design is the key to the outstanding generalizability of Ray3D approach. To have a comprehensive understanding of how the camera intrinsic and extrinsic parameter variations affect the accuracy of absolute 3D key-point localization, we conduct in-depth systematic experiments on three single person 3D benchmarks as well as one synthetic benchmark. These experiments demonstrate that our method significantly outperforms existing state-of-the-art models. Our code and the synthetic dataset are available at https://github.com/YxZhxn/Ray3D .
Instance Search via Instance Level Segmentation and Feature Representation
Jun 10, 2018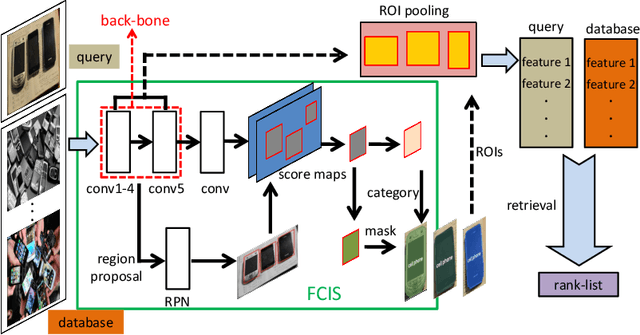
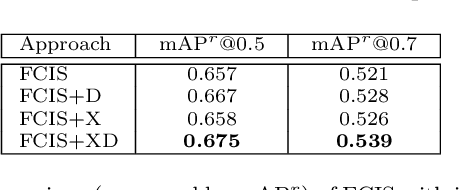


Instance search is an interesting task as well as a challenging issue due to the lack of effective feature representation. In this paper, an instance level feature representation built upon recent fully convolutional instance-aware segmentation is proposed. The feature is ROI-pooled based on the segmented instance region. So that instances in different sizes and layouts are represented by deep feature in uniform length. This representation is further enhanced by the use of deformable ResNeXt blocks. Superior performance in terms of its distinctiveness and scalability is observed on a challenging evaluation dataset built by ourselves.