 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAF: Focal Line and Feature-constrained Active View Planning for Visual Teach and Repeat
Sep 05, 2024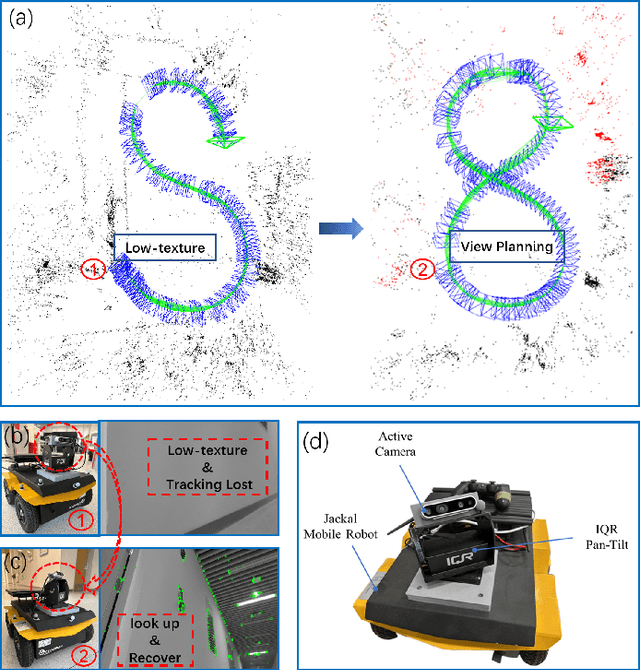
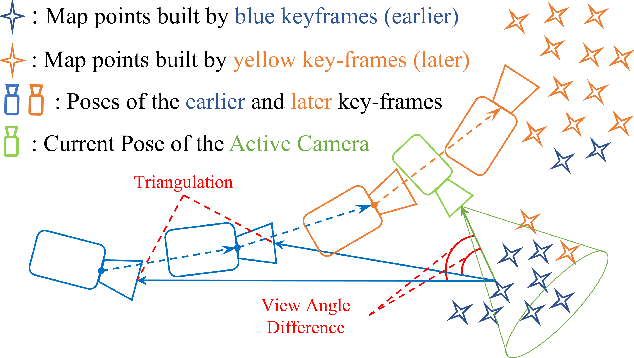
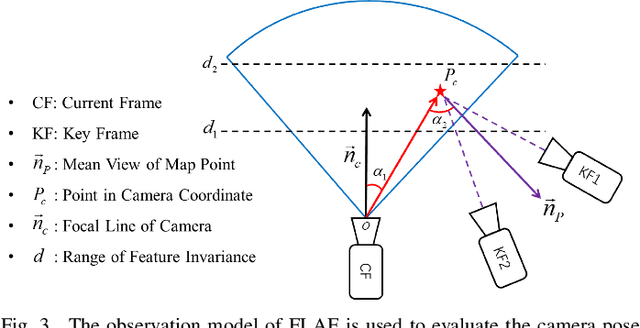
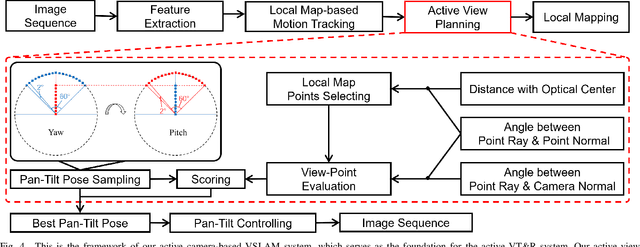
This paper presents FLAF, a focal line and feature-constrained active view planning method for tracking failure avoidance in feature-based visual navigation of mobile robots. Our FLAF-based visual navigation is built upon a feature-based visual teach and repeat (VT\&R) framework, which supports many robotic applications by teaching a robot to navigate on various paths that cover a significant portion of daily autonomous navigation requirements. However, tracking failure in feature-based visual simultaneous localization and mapping (VSLAM) caused by textureless regions in human-made environments is still limiting VT\&R to be adopted in the real world. To address this problem, the proposed view planner is integrated into a feature-based visual SLAM system to build up an active VT\&R system that avoids tracking failure. In our system, a pan-tilt unit (PTU)-based active camera is mounted on the mobile robot. Using FLAF, the active camera-based VSLAM operates during the teaching phase to construct a complete path map and in the repeat phase to maintain stable localization. FLAF orients the robot toward more map points to avoid mapping failures during path learning and toward more feature-identifiable map points beneficial for localization while following the learned trajectory. Experiments in real scenarios demonstrate that FLAF outperforms the methods that do not consider feature-identifiability, and our active VT\&R system performs well in complex environments by effectively dealing with low-texture regions.
SWCF-Net: Similarity-weighted Convolution and Local-global Fusion for Efficient Large-scale Point Cloud Semantic Segmentation
Jun 17, 2024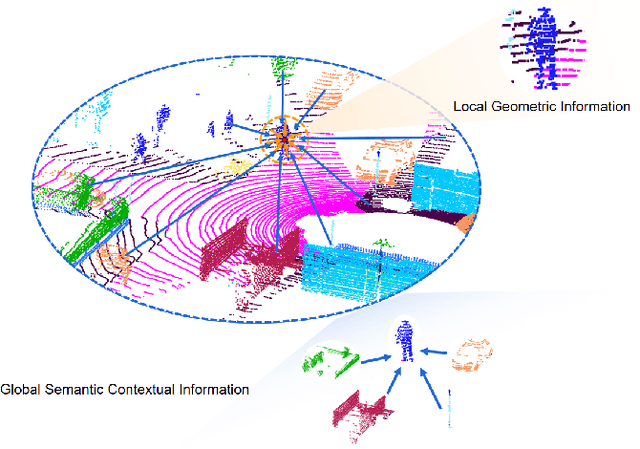
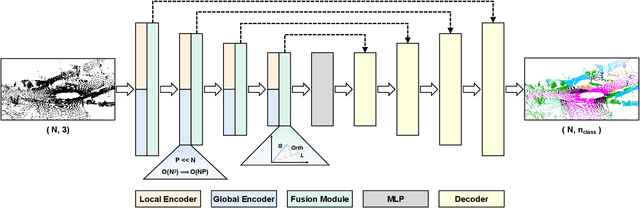
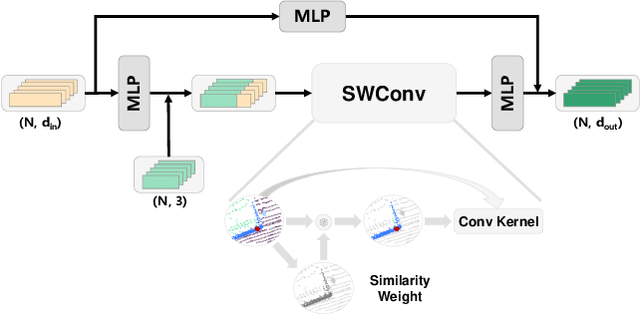
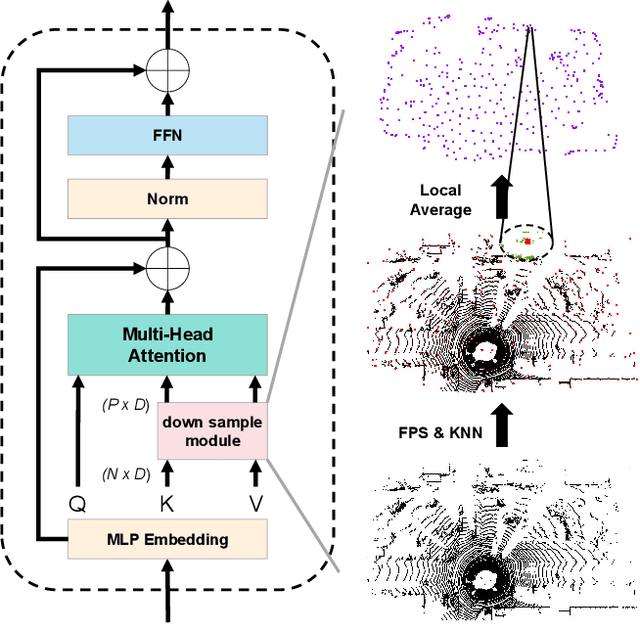
Large-scale point cloud consists of a multitude of individual objects, thereby encompassing rich structural and underlying semantic contextual information, resulting in a challenging problem in efficiently segmenting a point cloud. Most existing researches mainly focus on capturing intricate local features without giving due consideration to global ones, thus failing to leverage semantic context. In this paper, we propose a Similarity-Weighted Convolution and local-global Fusion Network, named SWCF-Net, which takes into account both local and global features. We propose a Similarity-Weighted Convolution (SWConv) to effectively extract local features, where similarity weights are incorporated into the convolution operation to enhance the generalization capabilities. Then, we employ a downsampling operation on the K and V channels within the attention module, thereby reducing the quadratic complexity to linear, enabling the Transformer to deal with large-scale point clouds. At last, orthogonal components are extracted in the global features and then aggregated with local features, thereby eliminating redundant information between local and global features and consequently promoting efficiency. We evaluate SWCF-Net on large-scale outdoor datasets SemanticKITTI and Toronto3D. Our experimental results demonstrate the effectiveness of the proposed network. Our method achieves a competitive result with less computational cost, and is able to handle large-scale point clouds efficiently.
Person Re-Identification for Robot Person Following with Online Continual Learning
Sep 21, 2023Robot person following (RPF) is a crucial capability in human-robot interaction (HRI) applications, allowing a robot to persistently follow a designated person. In practical RPF scenarios, the person often be occluded by other objects or people. Consequently, it is necessary to re-identify the person when he/she re-appears within the robot's field of view. Previous person re-identification (ReID) approaches to person following rely on offline-trained features and short-term experiences. Such an approach i) has a limited capacity to generalize across scenarios; and ii) often fails to re-identify the person when his re-appearance is out of the learned domain represented by the short-term experiences. Based on this observation, in this work, we propose a ReID framework for RPF that leverages long-term experiences. The experiences are maintained by a loss-guided keyframe selection strategy, to enable online continual learning of the appearance model. Our experiments demonstrate that even in the presence of severe appearance changes and distractions from visually similar people, the proposed method can still re-identify the person more accurately than the state-of-the-art methods.
A Systematic Evaluation of Different Indoor Localization Methods in Robotic Autonomous Luggage Trolley Collection at Airports
Mar 12, 2023This article addresses the localization problem in robotic autonomous luggage trolley collection at airports and provides a systematic evaluation of different methods to solve it. The robotic autonomous luggage trolley collection is a complex system that involves object detection, localization, motion planning and control, manipulation, etc. Among these components, effective localization is essential for the robot to employ subsequent motion planning and end-effector manipulation because it can provide a correct goal position. In this article, we survey four popular and representative localization methods to achieve object localization in the luggage collection process, including radio frequency identification (RFID), Keypoints, ultrawideband (UWB), and Reflectors. To test their performance, we construct a qualitative evaluation framework with Localization Accuracy, Mobile Power Supplies, Coverage Area, Cost, and Scalability. Besides, we conduct a series of quantitative experiments regarding Localization Accuracy and Success Rate on a real-world robotic autonomous luggage trolley collection system. We further analyze the performance of different localization methods based on experiment results, revealing that the Keypoints method is most suitable for indoor environments to achieve the luggage trolley collection.
Robot Person Following Under Partial Occlusion
Feb 27, 2023



Robot person following (RPF) is a capability that supports many useful human-robot-interaction (HRI) applications. However, existing solutions to person following often assume full observation of the tracked person. As a consequence, they cannot track the person reliably under partial occlusion where the assumption of full observation is not satisfied. In this paper, we focus on the problem of robot person following under partial occlusion caused by a limited field of view of a monocular camera. Based on the key insight that it is possible to locate the target person when one or more of his/her joints are visible, we propose a method in which each visible joint contributes a location estimate of the followed person. Experiments on a public person-following dataset show that, even under partial occlusion, the proposed method can still locate the person more reliably than the existing SOTA methods. As well, the application of our method is demonstrated in real experiments on a mobile robot.
Following Closely: A Robust Monocular Person Following System for Mobile Robot
Apr 25, 2022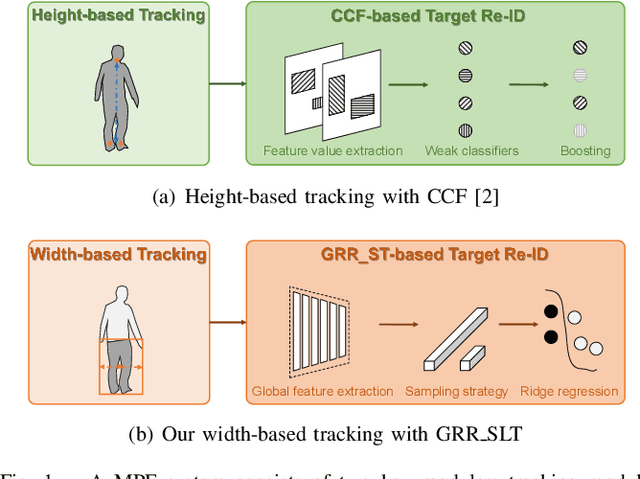
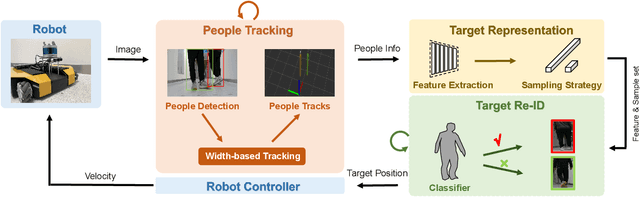

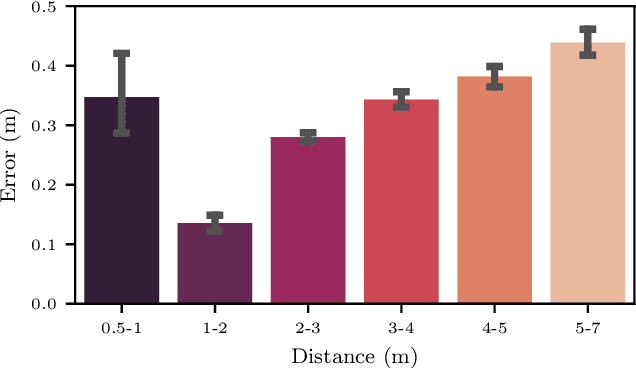
Monocular person following (MPF) is a capability that supports many useful applications of a mobile robot. However, existing MPF solutions are not completely satisfactory. Firstly, they often fail to track the target at a close distance either because they are based on a visual servo or they need the observation of the full body by the robot. Secondly, their target Re-IDentification (Re-ID) abilities are weak in cases of target appearance change and highly similar appearance of distracting people. To remove the assumption of full-body observation, we propose a width-based tracking module, which relies on the target width, which can be observed even at a close distance. For handling issues related to appearance variation, we use a global CNN (convolutional neural network) descriptor to represent the target and a ridge regression model to learn a target appearance model online. We adopt a sampling strategy for online classifier learning, in which both long-term and short-term samples are involved. We evaluate our method in two datasets including a public person following dataset and a custom-built one with challenging target appearance and target distance. Our method achieves state-of-the-art (SOTA) results on both datasets. For the benefit of the community, we make public the dataset and the source code.
Mapping While Following: 2D LiDAR SLAM in Indoor Dynamic Environments with a Person Tracker
Apr 18, 2022
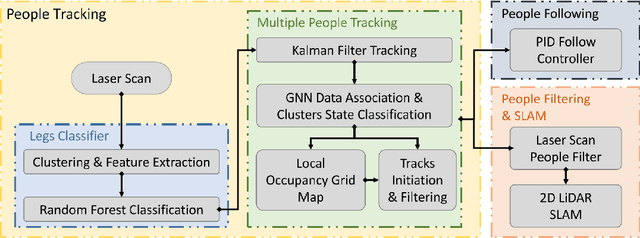

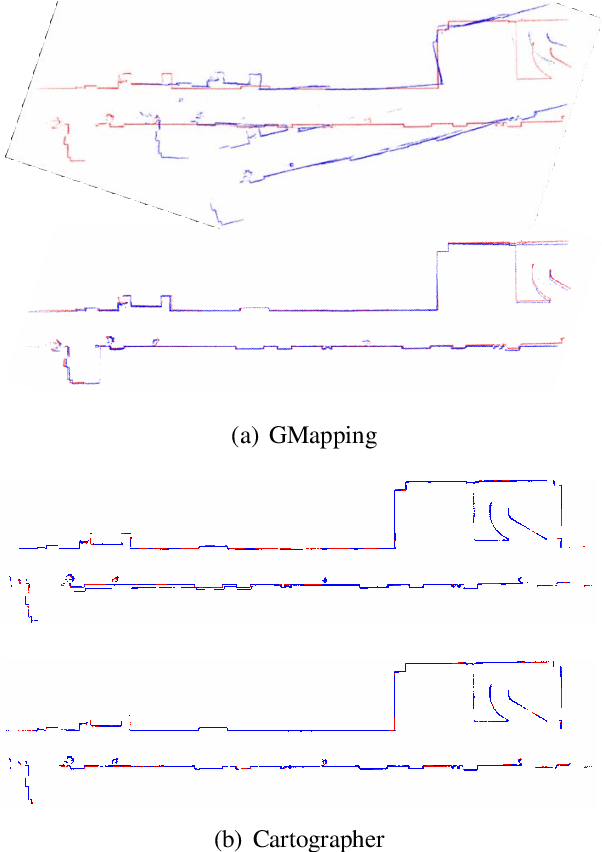
2D LiDAR SLAM (Simultaneous Localization and Mapping) is widely used in indoor environments due to its stability and flexibility. However, its mapping procedure is usually operated by a joystick in static environments, while indoor environments often are dynamic with moving objects such as people. The generated map with noisy points due to the dynamic objects is usually incomplete and distorted. To address this problem, we propose a framework of 2D-LiDAR-based SLAM without manual control that effectively excludes dynamic objects (people) and simplify the process for a robot to map an environment. The framework, which includes three parts: people tracking, filtering and following. We verify our proposed framework in experiments with two classic 2D-LiDAR-based SLAM algorithms in indoor environments. The results show that this framework is effective in handling dynamic objects and reducing the mapping error.
* Presented at 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO)
Condition-Invariant and Compact Visual Place Description by Convolutional Autoencoder
Apr 15, 2022

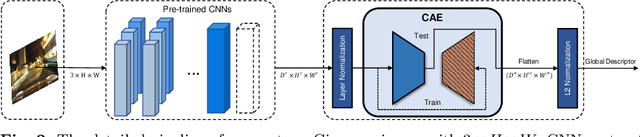
Visual place recognition (VPR) in condition-varying environments is still an open problem. Popular solutions are CNN-based image descriptors, which have been shown to outperform traditional image descriptors based on hand-crafted visual features. However, there are two drawbacks of current CNN-based descriptors: a) their high dimension and b) lack of generalization, leading to low efficiency and poor performance in applications. In this paper, we propose to use a convolutional autoencoder (CAE) to tackle this problem. We employ a high-level layer of a pre-trained CNN to generate features, and train a CAE to map the features to a low-dimensional space to improve the condition invariance property of the descriptor and reduce its dimension at the same time. We verify our method in three challenging datasets involving significant illumination changes, and our method is shown to be superior to the state-of-the-art. For the benefit of the community, we make public the source code.
Relationship Oriented Affordance Learning through Manipulation Graph Construction
Nov 01, 2021
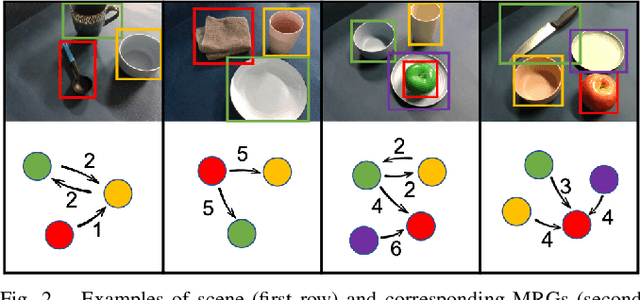
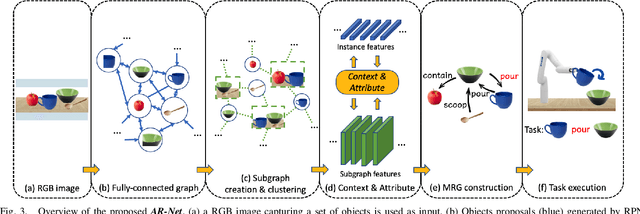
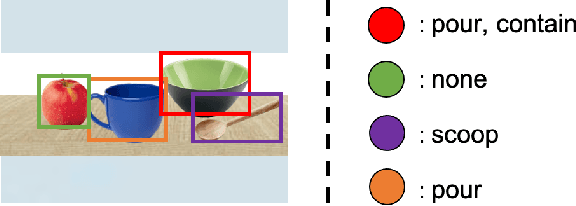
In this paper, we propose Manipulation Relationship Graph (MRG), a novel affordance representation which captures the underlying manipulation relationships of an arbitrary scene. To construct such a graph from raw visual observations, a deep nerual network named AR-Net is introduced. It consists of an Attribute module and a Context module, which guide the relationship learning at object and subgraph level respectively. We quantitatively validate our method on a novel manipulation relationship dataset named SMRD. To evaluate the performance of the proposed model and representation, both visual perception and physical manipulation experiments are conducted. Overall, AR-Net along with MRG outperforms all baselines, achieving the success rate of 88.89% on task relationship recognition (TRR) and 73.33% on task completion (TC)
Curiosity-based Robot Navigation under Uncertainty in Crowded Environments
Jun 10, 2021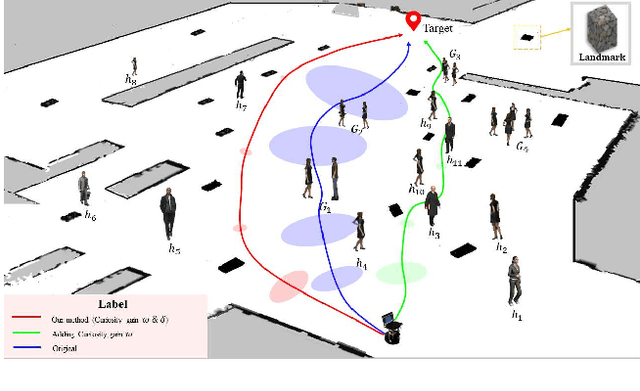
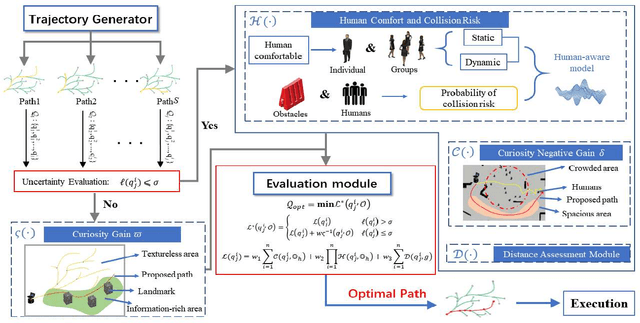
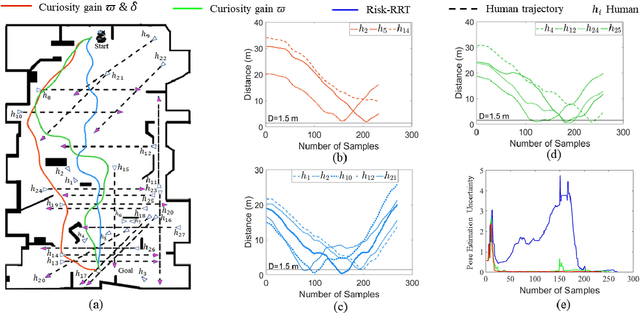

Mobile robots have become more and more popular in our daily life. In large-scale and crowded environments, how to navigate safely with localization precision is a critical problem. To solve this problem, we proposed a curiosity-based framework that can find an effective path with the consideration of human comfort, localization uncertainty, crowds, and the cost-to-go to the target. Three parts are involved in the proposed framework: the distance assessment module, the curiosity gain of the information-rich area, and the curiosity negative gain of crowded areas. The curiosity gain of the information-rich area was proposed to provoke the robot to approach localization referenced landmarks. To guarantee human comfort while coexisting with robots, we propose curiosity gain of the spacious area to bypass the crowd and maintain an appropriate distance between robots and humans. The evaluation is conducted in an unstructured environment. The results show that our method can find a feasible path, which can consider the localization uncertainty while simultaneously avoiding the crowded area. Curiosity-based Robot Navigation under Uncertainty in Crowded Environments