 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniteWorld: A Unified Scalable Simulation Framework for General Visual-Language Robot Interaction
Dec 08, 2024Realizing scaling laws in embodied AI has become a focus. However, previous work has been scattered across diverse simulation platforms, with assets and models lacking unified interfaces, which has led to inefficiencies in research. To address this, we introduce InfiniteWorld, a unified and scalable simulator for general vision-language robot interaction built on Nvidia Isaac Sim. InfiniteWorld encompasses a comprehensive set of physics asset construction methods and generalized free robot interaction benchmarks. Specifically, we first built a unified and scalable simulation framework for embodied learning that integrates a series of improvements in generation-driven 3D asset construction, Real2Sim, automated annotation framework, and unified 3D asset processing. This framework provides a unified and scalable platform for robot interaction and learning. In addition, to simulate realistic robot interaction, we build four new general benchmarks, including scene graph collaborative exploration and open-world social mobile manipulation. The former is often overlooked as an important task for robots to explore the environment and build scene knowledge, while the latter simulates robot interaction tasks with different levels of knowledge agents based on the former. They can more comprehensively evaluate the embodied agent's capabilities in environmental understanding, task planning and execution, and intelligent interaction. We hope that this work can provide the community with a systematic asset interface, alleviate the dilemma of the lack of high-quality assets, and provide a more comprehensive evaluation of robot interactions.
FLAF: Focal Line and Feature-constrained Active View Planning for Visual Teach and Repeat
Sep 05, 2024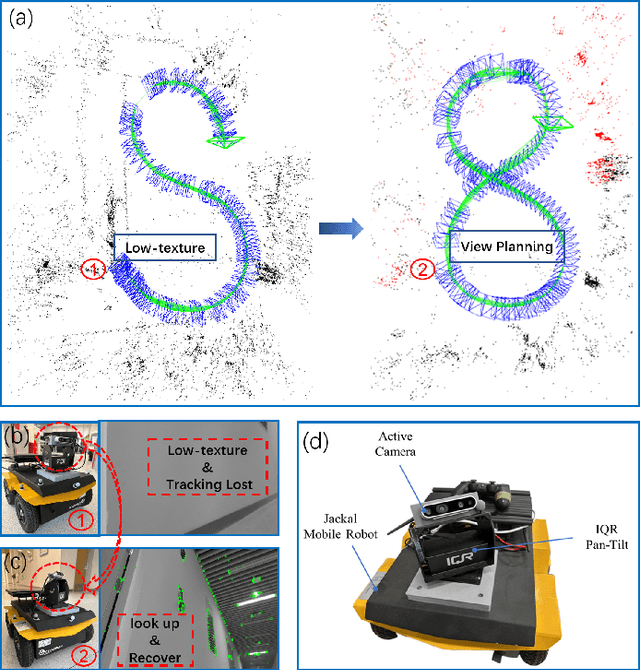
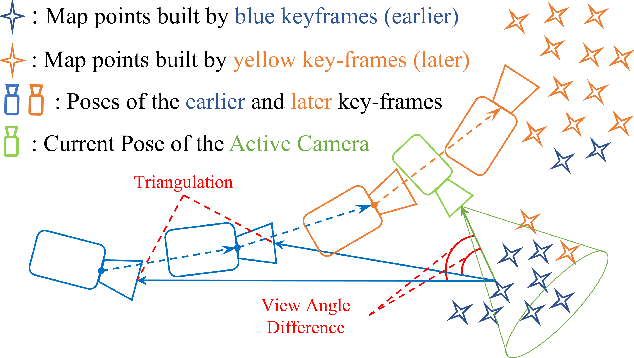
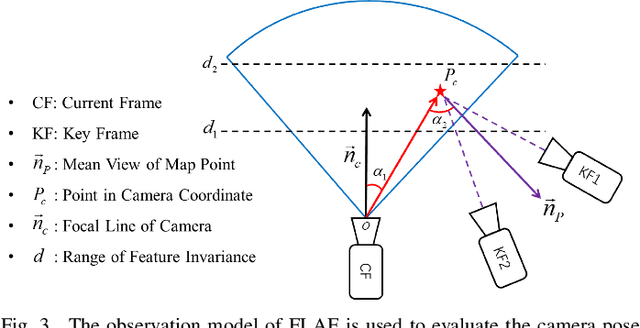
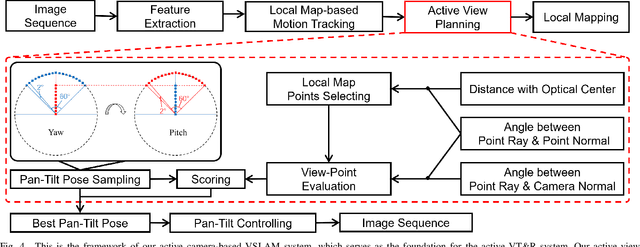
This paper presents FLAF, a focal line and feature-constrained active view planning method for tracking failure avoidance in feature-based visual navigation of mobile robots. Our FLAF-based visual navigation is built upon a feature-based visual teach and repeat (VT\&R) framework, which supports many robotic applications by teaching a robot to navigate on various paths that cover a significant portion of daily autonomous navigation requirements. However, tracking failure in feature-based visual simultaneous localization and mapping (VSLAM) caused by textureless regions in human-made environments is still limiting VT\&R to be adopted in the real world. To address this problem, the proposed view planner is integrated into a feature-based visual SLAM system to build up an active VT\&R system that avoids tracking failure. In our system, a pan-tilt unit (PTU)-based active camera is mounted on the mobile robot. Using FLAF, the active camera-based VSLAM operates during the teaching phase to construct a complete path map and in the repeat phase to maintain stable localization. FLAF orients the robot toward more map points to avoid mapping failures during path learning and toward more feature-identifiable map points beneficial for localization while following the learned trajectory. Experiments in real scenarios demonstrate that FLAF outperforms the methods that do not consider feature-identifiability, and our active VT\&R system performs well in complex environments by effectively dealing with low-texture regions.