 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape-Aware Monocular 3D Object Detection
Apr 24, 2022


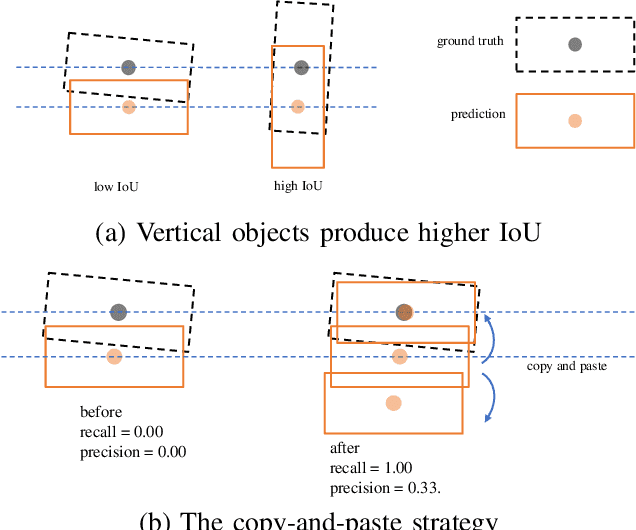
The detection of 3D objects through a single perspective camera is a challenging issue. The anchor-free and keypoint-based models receive increasing attention recently due to their effectiveness and simplicity. However, most of these methods are vulnerable to occluded and truncated objects. In this paper, a single-stage monocular 3D object detection model is proposed. An instance-segmentation head is integrated into the model training, which allows the model to be aware of the visible shape of a target object. The detection largely avoids interference from irrelevant regions surrounding the target objects. In addition, we also reveal that the popular IoU-based evaluation metrics, which were originally designed for evaluating stereo or LiDAR-based detection methods, are insensitive to the improvement of monocular 3D object detection algorithms. A novel evaluation metric, namely average depth similarity (ADS) is proposed for the monocular 3D object detection models. Our method outperforms the baseline on both the popular and the proposed evaluation metrics while maintaining real-time efficiency.
Graph-based Approximate NN Search: A Revisit
Apr 02, 2022
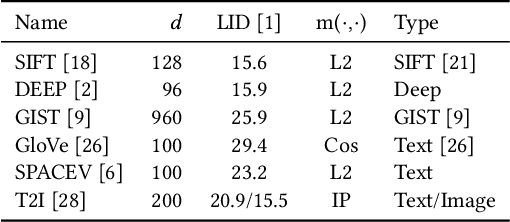

Nearest neighbor search plays a fundamental role in many disciplines such as multimedia information retrieval, data-mining, and machine learning. The graph-based search approaches show superior performance over other types of approaches in recent studies. In this paper, the graph-based NN search is revisited. We optimize two key components in the approach, namely the search procedure and the graph that supports the search. For the graph construction, a two-stage graph diversification scheme is proposed, which makes a good trade-off between the efficiency and reachability for the search procedure that builds upon it. Moreover, the proposed diversification scheme allows the search procedure to decide dynamically how many nodes should be visited in one node's neighborhood. By this way, the computing power of the devices is fully utilized when the search is carried out under different circumstances. Furthermore, two NN search procedures are designed respectively for small and large batch queries on the GPU. The optimized NN search, when being supported by the two-stage diversified graph, outperforms all the state-of-the-art approaches on both the CPU and the GPU across all the considered large-scale datasets.
Online Deep Metric Learning via Mutual Distillation
Mar 10, 2022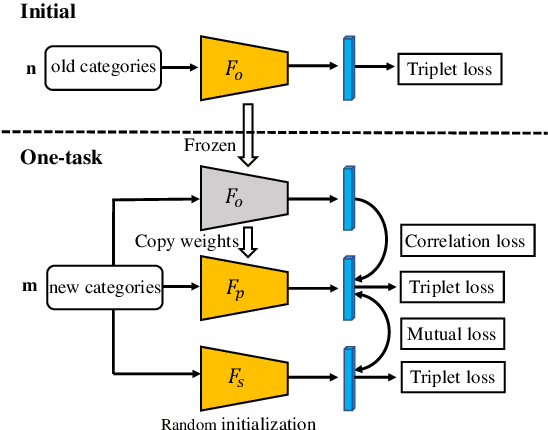

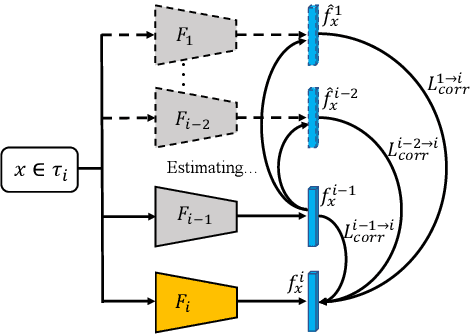
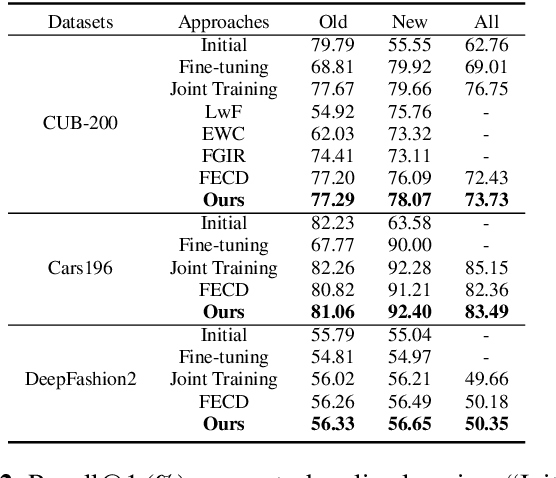
Deep metric learning aims to transform input data into an embedding space, where similar samples are close while dissimilar samples are far apart from each other. In practice, samples of new categories arrive incrementally, which requires the periodical augmentation of the learned model. The fine-tuning on the new categories usually leads to poor performance on the old, which is known as "catastrophic forgetting". Existing solutions either retrain the model from scratch or require the replay of old samples during the training. In this paper, a complete online deep metric learning framework is proposed based on mutual distillation for both one-task and multi-task scenarios. Different from the teacher-student framework, the proposed approach treats the old and new learning tasks with equal importance. No preference over the old or new knowledge is caused. In addition, a novel virtual feature estimation approach is proposed to recover the features assumed to be extracted by the old models. It allows the distillation between the new and the old models without the replay of old training samples or the holding of old models during the training. A comprehensive study shows the superior performance of our approach with the support of different backbones.
Anomaly Detection on IT Operation Series via Online Matrix Profile
Sep 06, 2021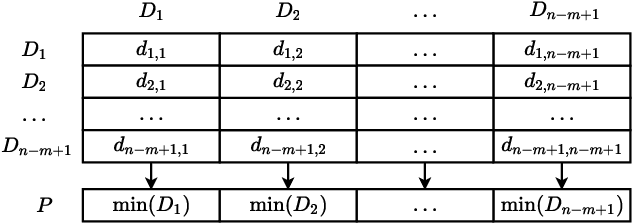

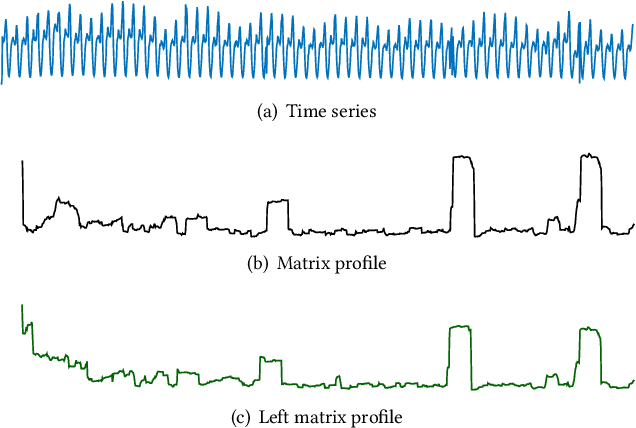
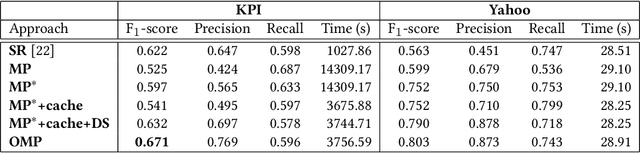
Anomaly detection on time series is a fundamental task in monitoring the Key Performance Indicators (KPIs) of IT systems. Many of the existing approaches in the literature show good performance while requiring a lot of training resources. In this paper, the online matrix profile, which requires no training, is proposed to address this issue. The anomalies are detected by referring to the past subsequence that is the closest to the current one. The distance significance is introduced based on the online matrix profile, which demonstrates a prominent pattern when an anomaly occurs. Another training-free approach spectral residual is integrated into our approach to further enhance the detection accuracy. Moreover, the proposed approach is sped up by at least four times for long time series by the introduced cache strategy. In comparison to the existing approaches, the online matrix profile makes a good trade-off between accuracy and efficiency. More importantly, it is generic to various types of time series in the sense that it works without the constraint from any trained model.
Towards Accurate Localization by Instance Search
Aug 07, 2021
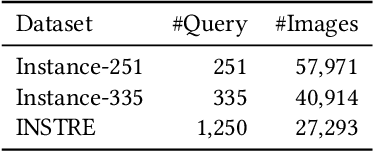
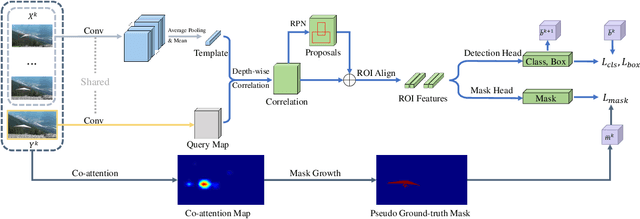
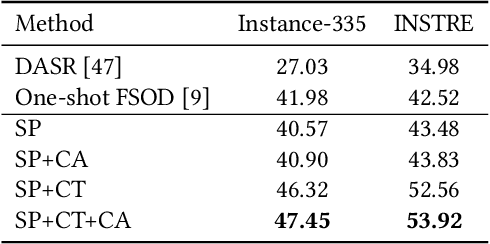
Visual object localization is the key step in a series of object detection tasks. In the literature, high localization accuracy is achieved with the mainstream strongly supervised frameworks. However, such methods require object-level annotations and are unable to detect objects of unknown categories. Weakly supervised methods face similar difficulties. In this paper, a self-paced learning framework is proposed to achieve accurate object localization on the rank list returned by instance search. The proposed framework mines the target instance gradually from the queries and their corresponding top-ranked search results. Since a common instance is shared between the query and the images in the rank list, the target visual instance can be accurately localized even without knowing what the object category is. In addition to performing localization on instance search, the issue of few-shot object detection is also addressed under the same framework. Superior performance over state-of-the-art methods is observed on both tasks.
Large-Scale Approximate k-NN Graph Construction on GPU
Mar 29, 2021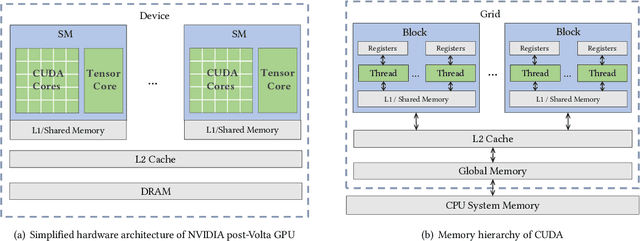

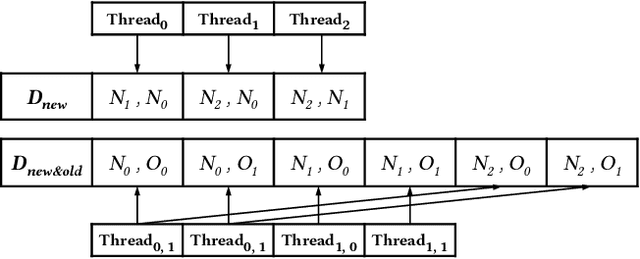
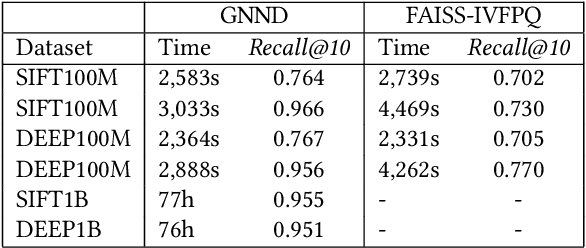
k-nearest neighbor graph is a key data structure in many disciplines such as manifold learning, machine learning and information retrieval, etc. NN-Descent was proposed as an effective solution for the graph construction problem. However, it cannot be directly transplanted to GPU due to the intensive memory accesses required in the approach. In this paper, NN-Descent has been redesigned to adapt to the GPU architecture. In particular, the number of memory accesses has been reduced significantly. The redesign fully exploits the parallelism of the GPU hardware. In the meantime, the genericness as well as the simplicity of NN-Descent are well-preserved. In addition, a simple but effective k-NN graph merge approach is presented. It allows two graphs to be merged efficiently on GPUs. More importantly, it makes the construction of high-quality k-NN graphs for out-of-GPU-memory datasets tractable. The results show that our approach is 100-250x faster than single-thread NN-Descent and is 2.5-5x faster than existing GPU-based approaches.
k-sums: another side of k-means
May 19, 2020
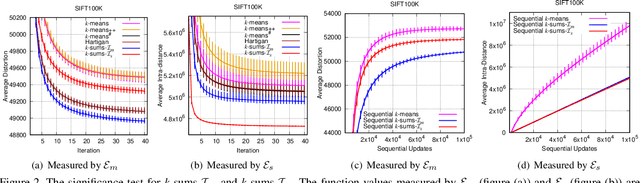

In this paper, the decades-old clustering method k-means is revisited. The original distortion minimization model of k-means is addressed by a pure stochastic minimization procedure. In each step of the iteration, one sample is tentatively reallocated from one cluster to another. It is moved to another cluster as long as the reallocation allows the sample to be closer to the new centroid. This optimization procedure converges faster to a better local minimum over k-means and many of its variants. This fundamental modification over the k-means loop leads to the redefinition of a family of k-means variants. Moreover, a new target function that minimizes the summation of pairwise distances within clusters is presented. We show that it could be solved under the same stochastic optimization procedure. This minimization procedure built upon two minimization models outperforms k-means and its variants considerably with different settings and on different datasets.
Dynamic Sampling for Deep Metric Learning
Apr 24, 2020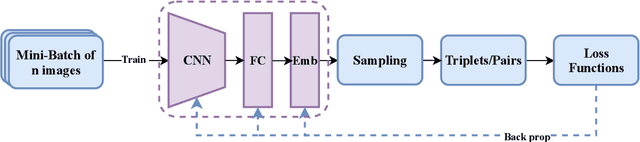
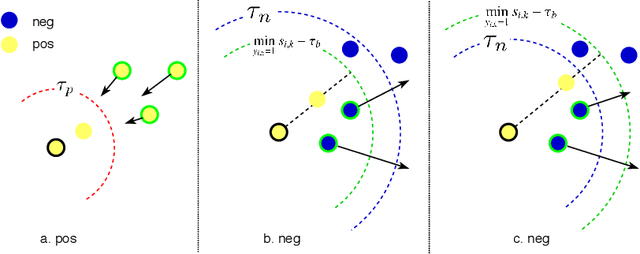
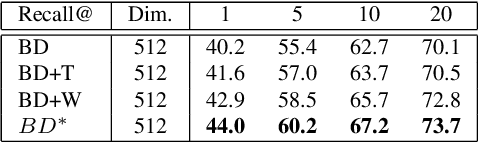
Deep metric learning maps visually similar images onto nearby locations and visually dissimilar images apart from each other in an embedding manifold. The learning process is mainly based on the supplied image negative and positive training pairs. In this paper, a dynamic sampling strategy is proposed to organize the training pairs in an easy-to-hard order to feed into the network. It allows the network to learn general boundaries between categories from the easy training pairs at its early stages and finalize the details of the model mainly relying on the hard training samples in the later. Compared to the existing training sample mining approaches, the hard samples are mined with little harm to the learned general model. This dynamic sampling strategy is formularized as two simple terms that are compatible with various loss functions. Consistent performance boost is observed when it is integrated with several popular loss functions on fashion search, fine-grained classification, and person re-identification tasks.
Deeply Activated Salient Region for Instance Search
Feb 22, 2020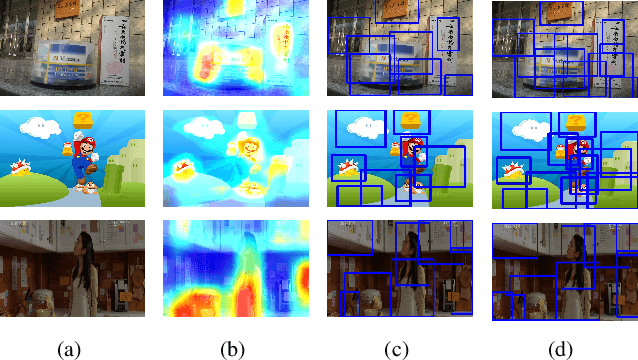
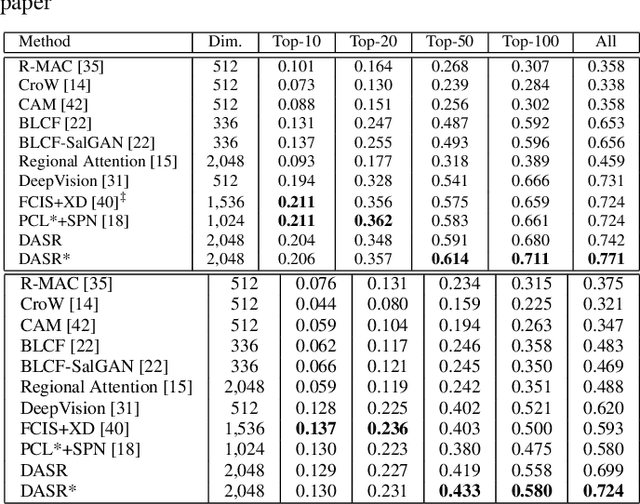
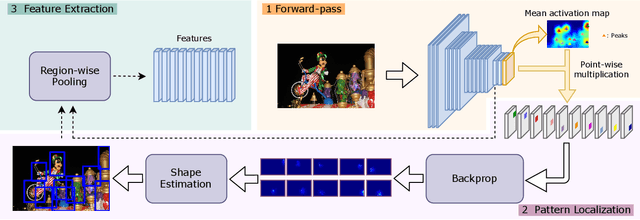

Due to the lack of suitable feature representation, effective solution to the instance search is still slow to occur. In this paper, a simple but effective instance-level feature representation is presented. Both the instance localization and distinctive feature representation are carefully considered in our design. On the first hand, the salient instance regions from images are detected by a layer-wise back-propagation process. The back-propagation starts from the last convolution layer of a pre-trained CNN that is originally used for classification. The back-propagation proceeds layer-by-layer until it reaches the input layer. This allows the salient regions in the input image from both known and unknown categories to be activated. Each activated salient region covers the full or more usually a major range of an instance. Secondly, distinctive feature representation is produced by average-pooling on the feature map of certain layer with the detected instance region. Experiment shows that such kind of feature representation demonstrates considerably better performance over fully-supervised approaches. In addition, we show that it is also suitable for content-based image search tasks.
Sequential VAE-LSTM for Anomaly Detection on Time Series
Oct 10, 2019In order to support stable web-based applications and services, anomalies on the IT performance status have to be detected timely. Moreover, the performance trend across the time series should be predicted. In this paper, we propose SeqVL (Sequential VAE-LSTM), a neural network model based on both VAE (Variational Auto-Encoder) and LSTM (Long Short-Term Memory). This work is the first attempt to integrate unsupervised anomaly detection and trend prediction under one framework. Moreover, this model performs considerably better on detection and prediction than VAE and LSTM work alone. On unsupervised anomaly detection, SeqVL achieves competitive experimental results compared with other state-of-the-art methods on public datasets. On trend prediction, SeqVL outperforms several classic time series prediction models in the experiments of the public dataset.