 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Deep Metric Learning via Mutual Distillation
Paper and Code
Mar 10, 2022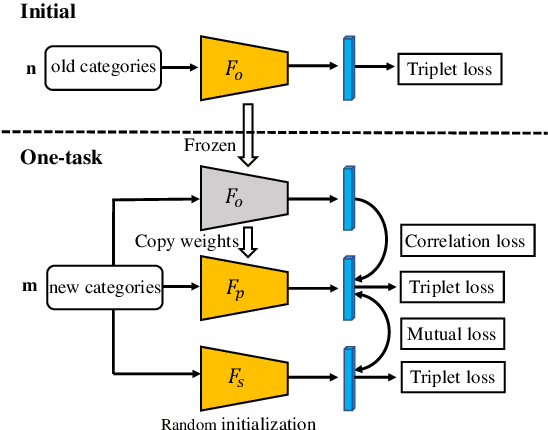

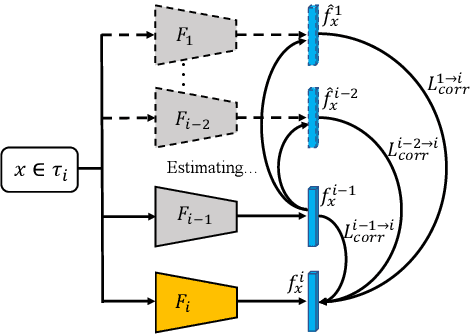
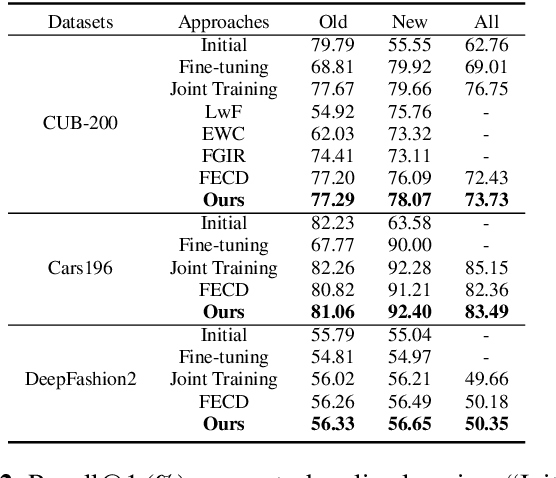
Deep metric learning aims to transform input data into an embedding space, where similar samples are close while dissimilar samples are far apart from each other. In practice, samples of new categories arrive incrementally, which requires the periodical augmentation of the learned model. The fine-tuning on the new categories usually leads to poor performance on the old, which is known as "catastrophic forgetting". Existing solutions either retrain the model from scratch or require the replay of old samples during the training. In this paper, a complete online deep metric learning framework is proposed based on mutual distillation for both one-task and multi-task scenarios. Different from the teacher-student framework, the proposed approach treats the old and new learning tasks with equal importance. No preference over the old or new knowledge is caused. In addition, a novel virtual feature estimation approach is proposed to recover the features assumed to be extracted by the old models. It allows the distillation between the new and the old models without the replay of old training samples or the holding of old models during the training. A comprehensive study shows the superior performance of our approach with the support of different backbones.