 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection on IT Operation Series via Online Matrix Profile
Sep 06, 2021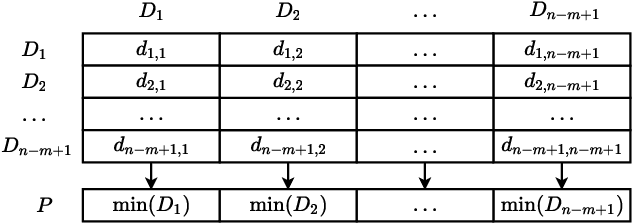

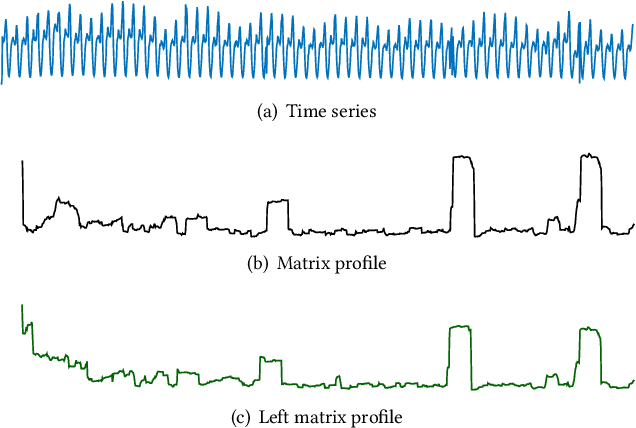
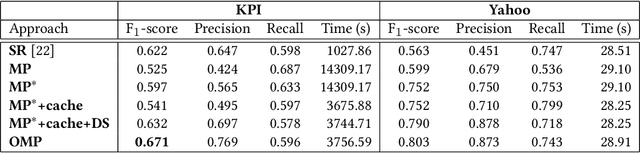
Anomaly detection on time series is a fundamental task in monitoring the Key Performance Indicators (KPIs) of IT systems. Many of the existing approaches in the literature show good performance while requiring a lot of training resources. In this paper, the online matrix profile, which requires no training, is proposed to address this issue. The anomalies are detected by referring to the past subsequence that is the closest to the current one. The distance significance is introduced based on the online matrix profile, which demonstrates a prominent pattern when an anomaly occurs. Another training-free approach spectral residual is integrated into our approach to further enhance the detection accuracy. Moreover, the proposed approach is sped up by at least four times for long time series by the introduced cache strategy. In comparison to the existing approaches, the online matrix profile makes a good trade-off between accuracy and efficiency. More importantly, it is generic to various types of time series in the sense that it works without the constraint from any trained model.
k-sums: another side of k-means
May 19, 2020
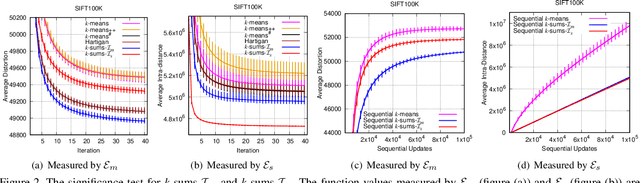

In this paper, the decades-old clustering method k-means is revisited. The original distortion minimization model of k-means is addressed by a pure stochastic minimization procedure. In each step of the iteration, one sample is tentatively reallocated from one cluster to another. It is moved to another cluster as long as the reallocation allows the sample to be closer to the new centroid. This optimization procedure converges faster to a better local minimum over k-means and many of its variants. This fundamental modification over the k-means loop leads to the redefinition of a family of k-means variants. Moreover, a new target function that minimizes the summation of pairwise distances within clusters is presented. We show that it could be solved under the same stochastic optimization procedure. This minimization procedure built upon two minimization models outperforms k-means and its variants considerably with different settings and on different datasets.
Dynamic Sampling for Deep Metric Learning
Apr 24, 2020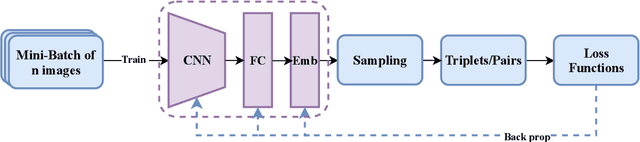
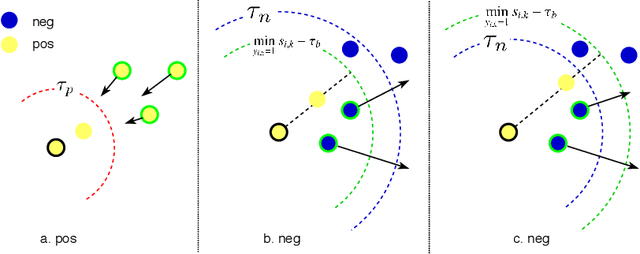
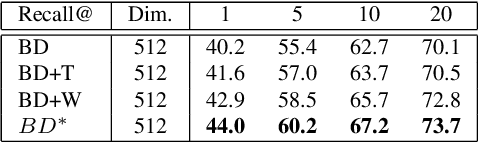
Deep metric learning maps visually similar images onto nearby locations and visually dissimilar images apart from each other in an embedding manifold. The learning process is mainly based on the supplied image negative and positive training pairs. In this paper, a dynamic sampling strategy is proposed to organize the training pairs in an easy-to-hard order to feed into the network. It allows the network to learn general boundaries between categories from the easy training pairs at its early stages and finalize the details of the model mainly relying on the hard training samples in the later. Compared to the existing training sample mining approaches, the hard samples are mined with little harm to the learned general model. This dynamic sampling strategy is formularized as two simple terms that are compatible with various loss functions. Consistent performance boost is observed when it is integrated with several popular loss functions on fashion search, fine-grained classification, and person re-identification tasks.
Sequential VAE-LSTM for Anomaly Detection on Time Series
Oct 10, 2019In order to support stable web-based applications and services, anomalies on the IT performance status have to be detected timely. Moreover, the performance trend across the time series should be predicted. In this paper, we propose SeqVL (Sequential VAE-LSTM), a neural network model based on both VAE (Variational Auto-Encoder) and LSTM (Long Short-Term Memory). This work is the first attempt to integrate unsupervised anomaly detection and trend prediction under one framework. Moreover, this model performs considerably better on detection and prediction than VAE and LSTM work alone. On unsupervised anomaly detection, SeqVL achieves competitive experimental results compared with other state-of-the-art methods on public datasets. On trend prediction, SeqVL outperforms several classic time series prediction models in the experiments of the public dataset.