 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Localization by Instance Search
Aug 07, 2021
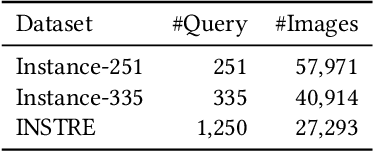
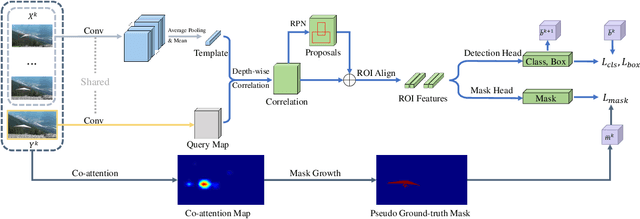
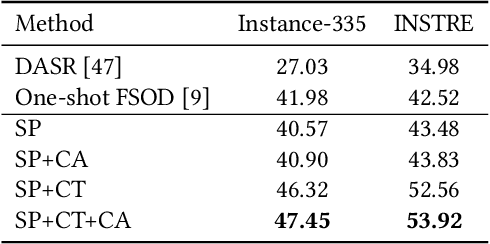
Visual object localization is the key step in a series of object detection tasks. In the literature, high localization accuracy is achieved with the mainstream strongly supervised frameworks. However, such methods require object-level annotations and are unable to detect objects of unknown categories. Weakly supervised methods face similar difficulties. In this paper, a self-paced learning framework is proposed to achieve accurate object localization on the rank list returned by instance search. The proposed framework mines the target instance gradually from the queries and their corresponding top-ranked search results. Since a common instance is shared between the query and the images in the rank list, the target visual instance can be accurately localized even without knowing what the object category is. In addition to performing localization on instance search, the issue of few-shot object detection is also addressed under the same framework. Superior performance over state-of-the-art methods is observed on both tasks.
Deeply Activated Salient Region for Instance Search
Feb 22, 2020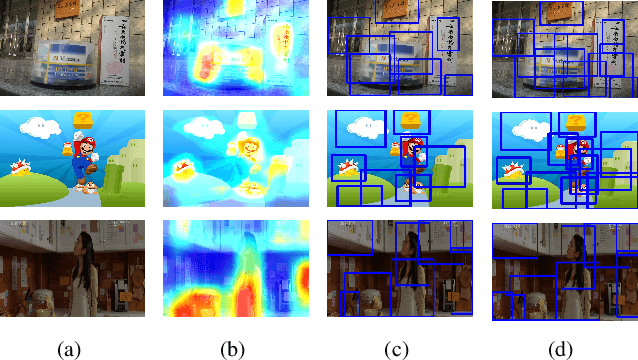
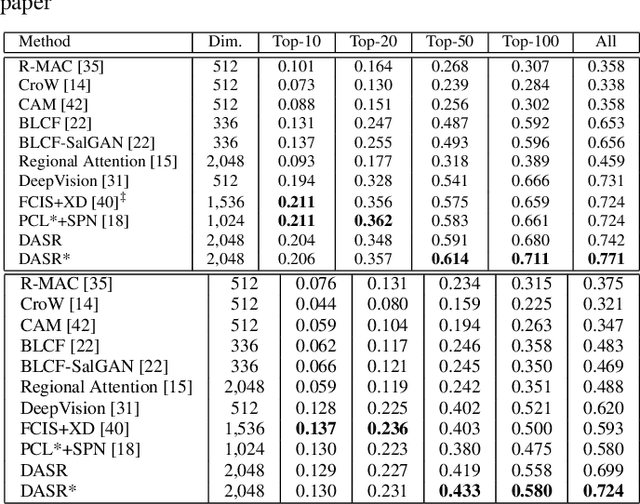
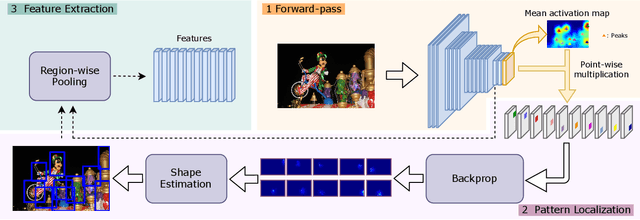

Due to the lack of suitable feature representation, effective solution to the instance search is still slow to occur. In this paper, a simple but effective instance-level feature representation is presented. Both the instance localization and distinctive feature representation are carefully considered in our design. On the first hand, the salient instance regions from images are detected by a layer-wise back-propagation process. The back-propagation starts from the last convolution layer of a pre-trained CNN that is originally used for classification. The back-propagation proceeds layer-by-layer until it reaches the input layer. This allows the salient regions in the input image from both known and unknown categories to be activated. Each activated salient region covers the full or more usually a major range of an instance. Secondly, distinctive feature representation is produced by average-pooling on the feature map of certain layer with the detected instance region. Experiment shows that such kind of feature representation demonstrates considerably better performance over fully-supervised approaches. In addition, we show that it is also suitable for content-based image search tasks.