 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study of animal action segmentation algorithms across supervised, unsupervised, and semi-supervised learning paradigms
Jul 23, 2024



Action segmentation of behavioral videos is the process of labeling each frame as belonging to one or more discrete classes, and is a crucial component of many studies that investigate animal behavior. A wide range of algorithms exist to automatically parse discrete animal behavior, encompassing supervised, unsupervised, and semi-supervised learning paradigms. These algorithms -- which include tree-based models, deep neural networks, and graphical models -- differ widely in their structure and assumptions on the data. Using four datasets spanning multiple species -- fly, mouse, and human -- we systematically study how the outputs of these various algorithms align with manually annotated behaviors of interest. Along the way, we introduce a semi-supervised action segmentation model that bridges the gap between supervised deep neural networks and unsupervised graphical models. We find that fully supervised temporal convolutional networks with the addition of temporal information in the observations perform the best on our supervised metrics across all datasets.
Understanding the Logit Distributions of Adversarially-Trained Deep Neural Networks
Aug 26, 2021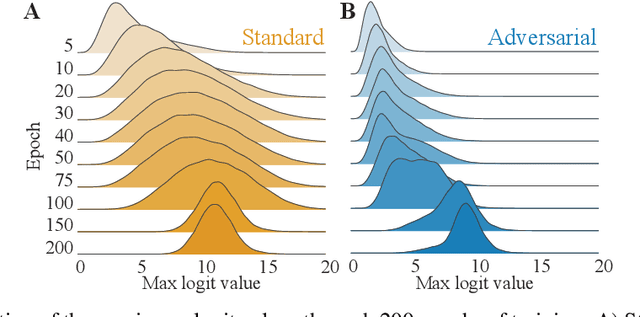

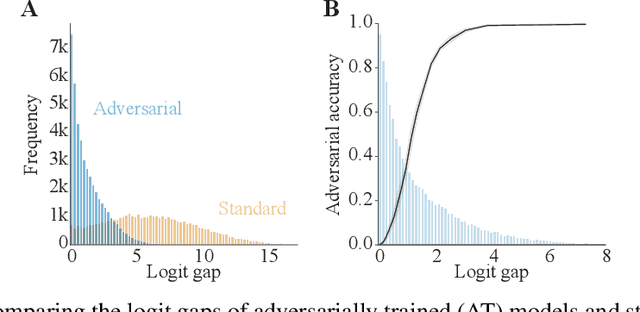

Adversarial defenses train deep neural networks to be invariant to the input perturbations from adversarial attacks. Almost all defense strategies achieve this invariance through adversarial training i.e. training on inputs with adversarial perturbations. Although adversarial training is successful at mitigating adversarial attacks, the behavioral differences between adversarially-trained (AT) models and standard models are still poorly understood. Motivated by a recent study on learning robustness without input perturbations by distilling an AT model, we explore what is learned during adversarial training by analyzing the distribution of logits in AT models. We identify three logit characteristics essential to learning adversarial robustness. First, we provide a theoretical justification for the finding that adversarial training shrinks two important characteristics of the logit distribution: the max logit values and the "logit gaps" (difference between the logit max and next largest values) are on average lower for AT models. Second, we show that AT and standard models differ significantly on which samples are high or low confidence, then illustrate clear qualitative differences by visualizing samples with the largest confidence difference. Finally, we find learning information about incorrect classes to be essential to learning robustness by manipulating the non-max logit information during distillation and measuring the impact on the student's robustness. Our results indicate that learning some adversarial robustness without input perturbations requires a model to learn specific sample-wise confidences and incorrect class orderings that follow complex distributions.