 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"So There's a Catch-22 Here": How Early Adopters Who Build Multi-Agent LLM Systems Conceptualize Transparency
Jun 06, 2026Multi-agent large language model (LLM) systems are rapidly emerging, yet transparency, a cornerstone of responsible AI, remains under-defined in these distributed architectures, which have complexities of inter-agent coordination and orchestration. In this paper, we present one of the first empirical study of how early adopters of multi-agent LLM systems, who are both the builders and users, understand and practice transparency. We conducted semi-structured interviews with 13 early adopters in [Large Technology Organization] and applied thematic analysis to identify recurring patterns. Participants articulated divergent yet complementary framings of transparency, including reproducibility, debugging, boundary-setting, visualization, and auditing. These perspectives spanned questions of what transparency entails, why it matters, and how it is achieved. We synthesize these into a multidimensional framework, which is developer, user, and governance-focused positioning transparency as a situated socio-technical practice that informs future HCI and AI design and research around aligning expectations and capacities of their intended audiences.
Human oversight of agentic systems in practice: Examining the oversight work, challenges, and heuristics of developers using software agents
Jun 03, 2026Autonomous software agents hold promise to increase developer productivity but make mistakes and exhibit novel failure modes, making human oversight central to successful human-agent collaboration. Existing research on agent oversight is largely conceptual; normative frameworks exist, but how users actually oversee agents is less known. In this paper, we bridge this gap by providing early empirical anchors for the theoretical discourse on agent oversight. Drawing on interviews with 17 experienced developers, we conduct an exploratory inquiry examining what forms of emergent oversight work developers perform, when, and how. We also document the oversight challenges developers face and the strategies they have started using to address them. We found at least four forms of emergent oversight work: a priori control, co-planning, real-time monitoring, and post hoc review. We show that oversight work is not only reactive and retrospective, as portrayed in existing research, but also preventative and proactive. We describe situated oversight challenges (e.g., difficulty reviewing agent-generated code) and outline heuristics developers adopt to address such challenges (e.g., using test results as guarantees for code correctness). We conclude with high-level takeaways, future research directions, implications for the human-centered design of software agents and for software engineering practice, and limitations of our research.
"I'm Not Sure, But": Examining the Impact of Large Language Models' Uncertainty Expression on User Reliance and Trust
May 01, 2024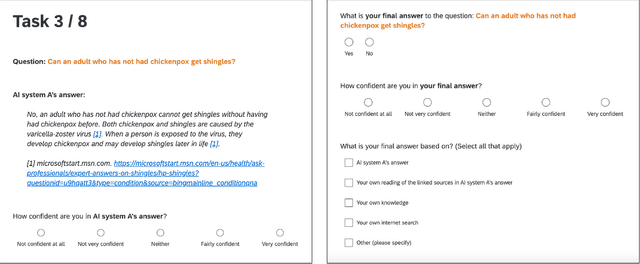
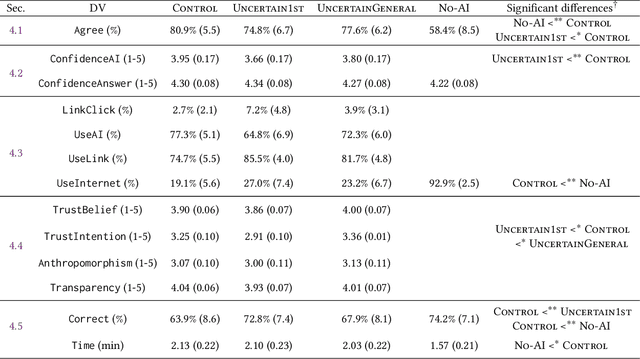
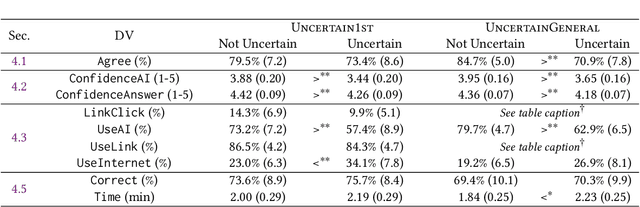
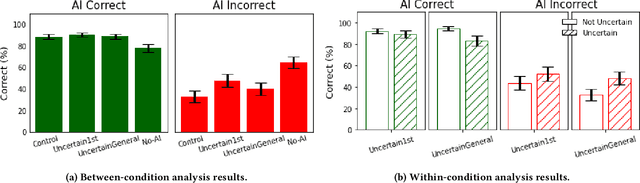
Widely deployed large language models (LLMs) can produce convincing yet incorrect outputs, potentially misleading users who may rely on them as if they were correct. To reduce such overreliance, there have been calls for LLMs to communicate their uncertainty to end users. However, there has been little empirical work examining how users perceive and act upon LLMs' expressions of uncertainty. We explore this question through a large-scale, pre-registered, human-subject experiment (N=404) in which participants answer medical questions with or without access to responses from a fictional LLM-infused search engine. Using both behavioral and self-reported measures, we examine how different natural language expressions of uncertainty impact participants' reliance, trust, and overall task performance. We find that first-person expressions (e.g., "I'm not sure, but...") decrease participants' confidence in the system and tendency to agree with the system's answers, while increasing participants' accuracy. An exploratory analysis suggests that this increase can be attributed to reduced (but not fully eliminated) overreliance on incorrect answers. While we observe similar effects for uncertainty expressed from a general perspective (e.g., "It's not clear, but..."), these effects are weaker and not statistically significant. Our findings suggest that using natural language expressions of uncertainty may be an effective approach for reducing overreliance on LLMs, but that the precise language used matters. This highlights the importance of user testing before deploying LLMs at scale.
Interpretability, Then What? Editing Machine Learning Models to Reflect Human Knowledge and Values
Jun 30, 2022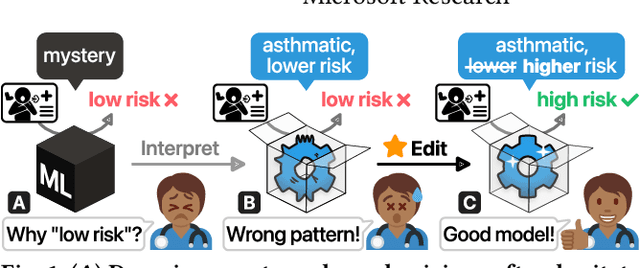
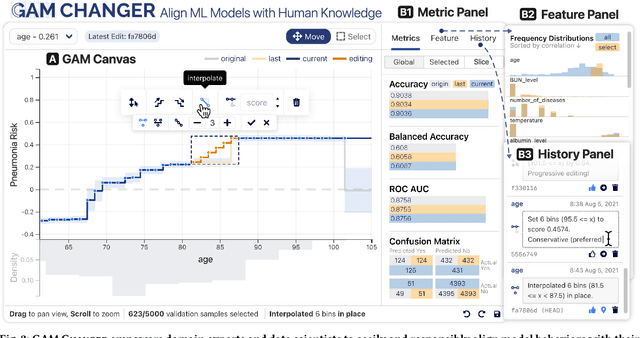
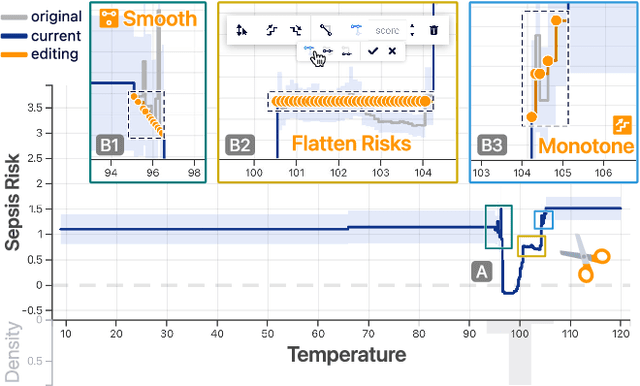
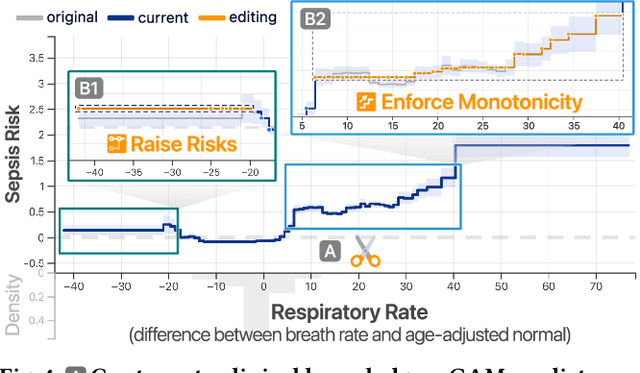
Machine learning (ML) interpretability techniques can reveal undesirable patterns in data that models exploit to make predictions--potentially causing harms once deployed. However, how to take action to address these patterns is not always clear. In a collaboration between ML and human-computer interaction researchers, physicians, and data scientists, we develop GAM Changer, the first interactive system to help domain experts and data scientists easily and responsibly edit Generalized Additive Models (GAMs) and fix problematic patterns. With novel interaction techniques, our tool puts interpretability into action--empowering users to analyze, validate, and align model behaviors with their knowledge and values. Physicians have started to use our tool to investigate and fix pneumonia and sepsis risk prediction models, and an evaluation with 7 data scientists working in diverse domains highlights that our tool is easy to use, meets their model editing needs, and fits into their current workflows. Built with modern web technologies, our tool runs locally in users' web browsers or computational notebooks, lowering the barrier to use. GAM Changer is available at the following public demo link: https://interpret.ml/gam-changer.
Understanding Machine Learning Practitioners' Data Documentation Perceptions, Needs, Challenges, and Desiderata
Jun 06, 2022

Data is central to the development and evaluation of machine learning (ML) models. However, the use of problematic or inappropriate datasets can result in harms when the resulting models are deployed. To encourage responsible AI practice through more deliberate reflection on datasets and transparency around the processes by which they are created, researchers and practitioners have begun to advocate for increased data documentation and have proposed several data documentation frameworks. However, there is little research on whether these data documentation frameworks meet the needs of ML practitioners, who both create and consume datasets. To address this gap, we set out to understand ML practitioners' data documentation perceptions, needs, challenges, and desiderata, with the goal of deriving design requirements that can inform future data documentation frameworks. We conducted a series of semi-structured interviews with 14 ML practitioners at a single large, international technology company. We had them answer a list of questions taken from datasheets for datasets (Gebru, 2021). Our findings show that current approaches to data documentation are largely ad hoc and myopic in nature. Participants expressed needs for data documentation frameworks to be adaptable to their contexts, integrated into their existing tools and workflows, and automated wherever possible. Despite the fact that data documentation frameworks are often motivated from the perspective of responsible AI, participants did not make the connection between the questions that they were asked to answer and their responsible AI implications. In addition, participants often had difficulties prioritizing the needs of dataset consumers and providing information that someone unfamiliar with their datasets might need to know. Based on these findings, we derive seven design requirements for future data documentation frameworks.
GAM Changer: Editing Generalized Additive Models with Interactive Visualization
Dec 06, 2021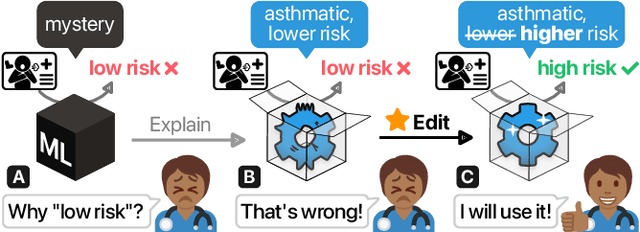

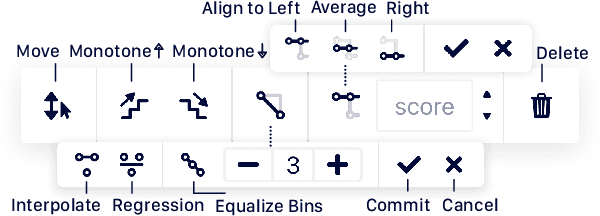

Recent strides in interpretable machine learning (ML) research reveal that models exploit undesirable patterns in the data to make predictions, which potentially causes harms in deployment. However, it is unclear how we can fix these models. We present our ongoing work, GAM Changer, an open-source interactive system to help data scientists and domain experts easily and responsibly edit their Generalized Additive Models (GAMs). With novel visualization techniques, our tool puts interpretability into action -- empowering human users to analyze, validate, and align model behaviors with their knowledge and values. Built using modern web technologies, our tool runs locally in users' computational notebooks or web browsers without requiring extra compute resources, lowering the barrier to creating more responsible ML models. GAM Changer is available at https://interpret.ml/gam-changer.