 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews
Mar 11, 2024



We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leverages expert-written and AI-generated reference texts to accurately and efficiently examine real-world LLM-use at the corpus level. We apply this approach to a case study of scientific peer review in AI conferences that took place after the release of ChatGPT: ICLR 2024, NeurIPS 2023, CoRL 2023 and EMNLP 2023. Our results suggest that between 6.5% and 16.9% of text submitted as peer reviews to these conferences could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates. The circumstances in which generated text occurs offer insight into user behavior: the estimated fraction of LLM-generated text is higher in reviews which report lower confidence, were submitted close to the deadline, and from reviewers who are less likely to respond to author rebuttals. We also observe corpus-level trends in generated text which may be too subtle to detect at the individual level, and discuss the implications of such trends on peer review. We call for future interdisciplinary work to examine how LLM use is changing our information and knowledge practices.
The Rise of Open Science: Tracking the Evolution and Perceived Value of Data and Methods Link-Sharing Practices
Oct 04, 2023



In recent years, funding agencies and journals increasingly advocate for open science practices (e.g. data and method sharing) to improve the transparency, access, and reproducibility of science. However, quantifying these practices at scale has proven difficult. In this work, we leverage a large-scale dataset of 1.1M papers from arXiv that are representative of the fields of physics, math, and computer science to analyze the adoption of data and method link-sharing practices over time and their impact on article reception. To identify links to data and methods, we train a neural text classification model to automatically classify URL types based on contextual mentions in papers. We find evidence that the practice of link-sharing to methods and data is spreading as more papers include such URLs over time. Reproducibility efforts may also be spreading because the same links are being increasingly reused across papers (especially in computer science); and these links are increasingly concentrated within fewer web domains (e.g. Github) over time. Lastly, articles that share data and method links receive increased recognition in terms of citation count, with a stronger effect when the shared links are active (rather than defunct). Together, these findings demonstrate the increased spread and perceived value of data and method sharing practices in open science.
Will This Idea Spread Beyond Academia? Understanding Knowledge Transfer of Scientific Concepts across Text Corpora
Oct 13, 2020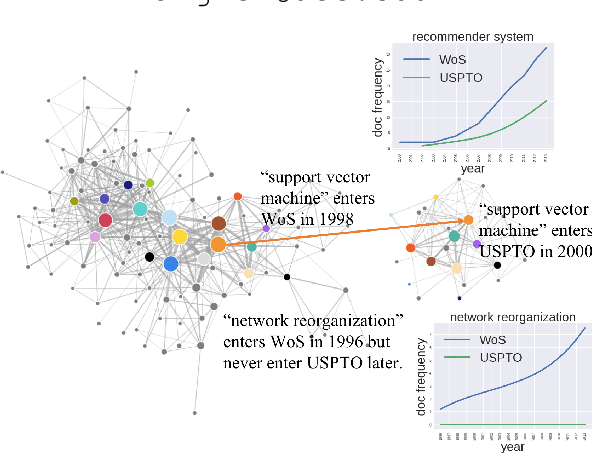
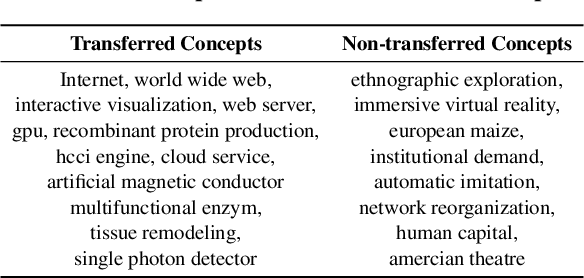
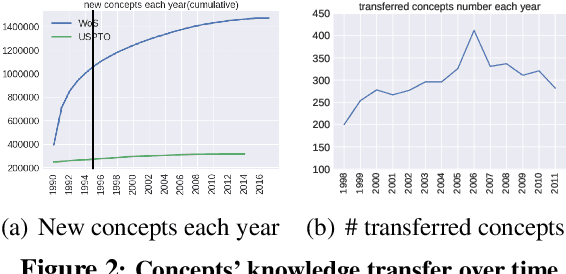

What kind of basic research ideas are more likely to get applied in practice? There is a long line of research investigating patterns of knowledge transfer, but it generally focuses on documents as the unit of analysis and follow their transfer into practice for a specific scientific domain. Here we study translational research at the level of scientific concepts for all scientific fields. We do this through text mining and predictive modeling using three corpora: 38.6 million paper abstracts, 4 million patent documents, and 0.28 million clinical trials. We extract scientific concepts (i.e., phrases) from corpora as instantiations of "research ideas", create concept-level features as motivated by literature, and then follow the trajectories of over 450,000 new concepts (emerged from 1995-2014) to identify factors that lead only a small proportion of these ideas to be used in inventions and drug trials. Results from our analysis suggest several mechanisms that distinguish which scientific concept will be adopted in practice, and which will not. We also demonstrate that our derived features can be used to explain and predict knowledge transfer with high accuracy. Our work provides greater understanding of knowledge transfer for researchers, practitioners, and government agencies interested in encouraging translational research.
Diversity Breeds Innovation With Discounted Impact and Recognition
Sep 04, 2019
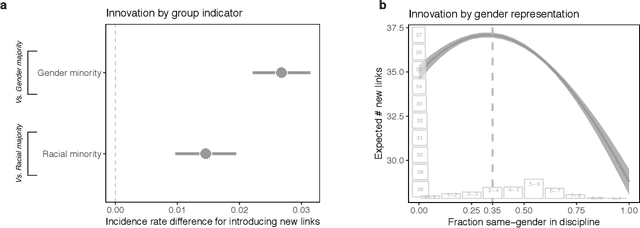

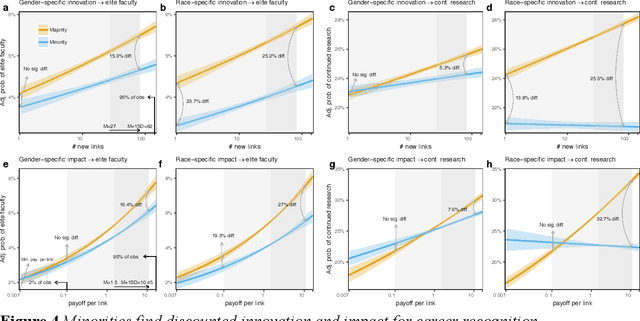
Prior work poses a diversity paradox for science. Diversity breeds scientific innovation, and yet, diverse individuals have less successful scientific careers. But if diversity is good for innovation, why is science not rewarding diversity? We answer this question by utilizing a near-population of ~1.03 million US doctoral recipients from 1980-2015 and their careers into publishing and faculty roles. The article uses text analysis and machine learning techniques to answer a series of questions: How can we detect scientific innovation? Does diversity breed innovation? And are the innovations of diverse individuals adopted and rewarded? Our analyses show that underrepresented groups produce higher rates of scientific novelty. However, their novel contributions are discounted: e.g., innovations by gender minorities are taken up by other scholars at lower rates than innovations by gender majorities, and innovations by gender and racial minorities result in fewer academic positions. This suggests an unfair system in which diverse individuals innovate, but their innovations are disproportionately ignored and fail to convert into career success at the same rate as majority groups. In sum, there may be an unwarranted reproduction of stratification in academic careers that discounts diversity's role in innovation and partly explains the underrepresentation of some groups in academia.