 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStomataSeg: Semi-Supervised Instance Segmentation for Sorghum Stomatal Components
Jan 31, 2026Sorghum is a globally important cereal grown widely in water-limited and stress-prone regions. Its strong drought tolerance makes it a priority crop for climate-resilient agriculture. Improving water-use efficiency in sorghum requires precise characterisation of stomatal traits, as stomata control of gas exchange, transpiration and photosynthesis have a major influence on crop performance. Automated analysis of sorghum stomata is difficult because the stomata are small (often less than 40 $μ$m in length in grasses such as sorghum) and vary in shape across genotypes and leaf surfaces. Automated segmentation contributes to high-throughput stomatal phenotyping, yet current methods still face challenges related to nested small structures and annotation bottlenecks. In this paper, we propose a semi-supervised instance segmentation framework tailored for analysis of sorghum stomatal components. We collect and annotate a sorghum leaf imagery dataset containing 11,060 human-annotated patches, covering the three stomatal components (pore, guard cell and complex area) across multiple genotypes and leaf surfaces. To improve the detection of tiny structures, we split high-resolution microscopy images into overlapping small patches. We then apply a pseudo-labelling strategy to unannotated images, producing an additional 56,428 pseudo-labelled patches. Benchmarking across semantic and instance segmentation models shows substantial performance gains: for semantic models the top mIoU increases from 65.93% to 70.35%, whereas for instance models the top AP rises from 28.30% to 46.10%. These results demonstrate that combining patch-based preprocessing with semi-supervised learning significantly improves the segmentation of fine stomatal structures. The proposed framework supports scalable extraction of stomatal traits and facilitates broader adoption of AI-driven phenotyping in crop science.
Can large language models provide useful feedback on research papers? A large-scale empirical analysis
Oct 03, 2023



Expert feedback lays the foundation of rigorous research. However, the rapid growth of scholarly production and intricate knowledge specialization challenge the conventional scientific feedback mechanisms. High-quality peer reviews are increasingly difficult to obtain. Researchers who are more junior or from under-resourced settings have especially hard times getting timely feedback. With the breakthrough of large language models (LLM) such as GPT-4, there is growing interest in using LLMs to generate scientific feedback on research manuscripts. However, the utility of LLM-generated feedback has not been systematically studied. To address this gap, we created an automated pipeline using GPT-4 to provide comments on the full PDFs of scientific papers. We evaluated the quality of GPT-4's feedback through two large-scale studies. We first quantitatively compared GPT-4's generated feedback with human peer reviewer feedback in 15 Nature family journals (3,096 papers in total) and the ICLR machine learning conference (1,709 papers). The overlap in the points raised by GPT-4 and by human reviewers (average overlap 30.85% for Nature journals, 39.23% for ICLR) is comparable to the overlap between two human reviewers (average overlap 28.58% for Nature journals, 35.25% for ICLR). The overlap between GPT-4 and human reviewers is larger for the weaker papers. We then conducted a prospective user study with 308 researchers from 110 US institutions in the field of AI and computational biology to understand how researchers perceive feedback generated by our GPT-4 system on their own papers. Overall, more than half (57.4%) of the users found GPT-4 generated feedback helpful/very helpful and 82.4% found it more beneficial than feedback from at least some human reviewers. While our findings show that LLM-generated feedback can help researchers, we also identify several limitations.
A Semi-supervised Approach for Activity Recognition from Indoor Trajectory Data
Jan 11, 2023The increasingly wide usage of location aware sensors has made it possible to collect large volume of trajectory data in diverse application domains. Machine learning allows to study the activities or behaviours of moving objects (e.g., people, vehicles, robot) using such trajectory data with rich spatiotemporal information to facilitate informed strategic and operational decision making. In this study, we consider the task of classifying the activities of moving objects from their noisy indoor trajectory data in a collaborative manufacturing environment. Activity recognition can help manufacturing companies to develop appropriate management policies, and optimise safety, productivity, and efficiency. We present a semi-supervised machine learning approach that first applies an information theoretic criterion to partition a long trajectory into a set of segments such that the object exhibits homogeneous behaviour within each segment. The segments are then labelled automatically based on a constrained hierarchical clustering method. Finally, a deep learning classification model based on convolutional neural networks is trained on trajectory segments and the generated pseudo labels. The proposed approach has been evaluated on a dataset containing indoor trajectories of multiple workers collected from a tricycle assembly workshop. The proposed approach is shown to achieve high classification accuracy (F-score varies between 0.81 to 0.95 for different trajectories) using only a small proportion of labelled trajectory segments.
Movement Analytics: Current Status, Application to Manufacturing, and Future Prospects from an AI Perspective
Oct 04, 2022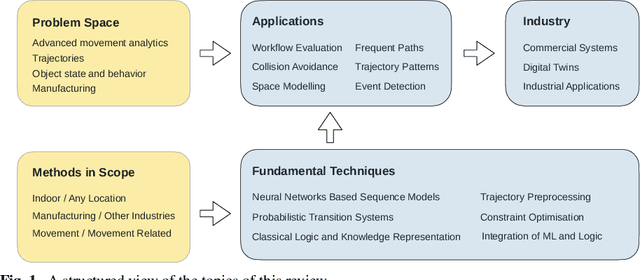
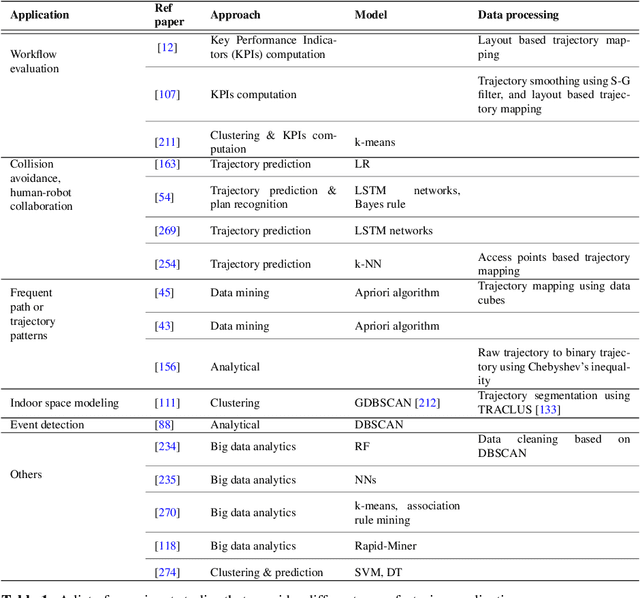
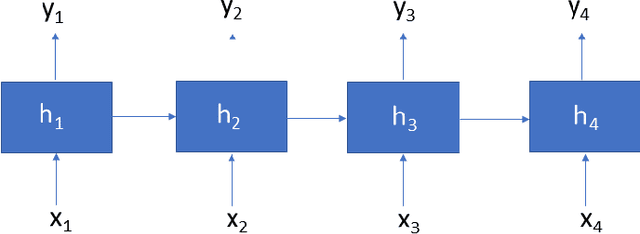
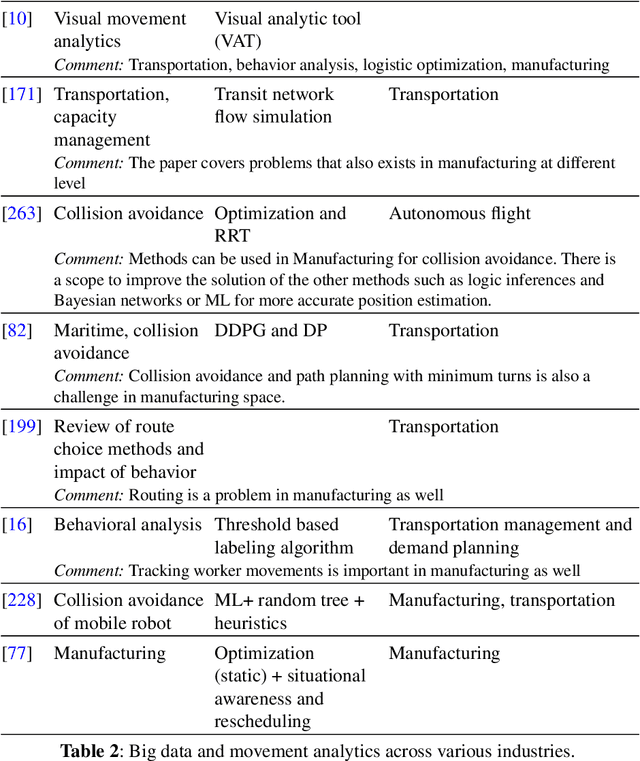
Data-driven decision making is becoming an integral part of manufacturing companies. Data is collected and commonly used to improve efficiency and produce high quality items for the customers. IoT-based and other forms of object tracking are an emerging tool for collecting movement data of objects/entities (e.g. human workers, moving vehicles, trolleys etc.) over space and time. Movement data can provide valuable insights like process bottlenecks, resource utilization, effective working time etc. that can be used for decision making and improving efficiency. Turning movement data into valuable information for industrial management and decision making requires analysis methods. We refer to this process as movement analytics. The purpose of this document is to review the current state of work for movement analytics both in manufacturing and more broadly. We survey relevant work from both a theoretical perspective and an application perspective. From the theoretical perspective, we put an emphasis on useful methods from two research areas: machine learning, and logic-based knowledge representation. We also review their combinations in view of movement analytics, and we discuss promising areas for future development and application. Furthermore, we touch on constraint optimization. From an application perspective, we review applications of these methods to movement analytics in a general sense and across various industries. We also describe currently available commercial off-the-shelf products for tracking in manufacturing, and we overview main concepts of digital twins and their applications.
The CSIRO Crown-of-Thorn Starfish Detection Dataset
Nov 29, 2021
Crown-of-Thorn Starfish (COTS) outbreaks are a major cause of coral loss on the Great Barrier Reef (GBR) and substantial surveillance and control programs are underway in an attempt to manage COTS populations to ecologically sustainable levels. We release a large-scale, annotated underwater image dataset from a COTS outbreak area on the GBR, to encourage research on Machine Learning and AI-driven technologies to improve the detection, monitoring, and management of COTS populations at reef scale. The dataset is released and hosted in a Kaggle competition that challenges the international Machine Learning community with the task of COTS detection from these underwater images.
Florida Wildlife Camera Trap Dataset
Jun 23, 2021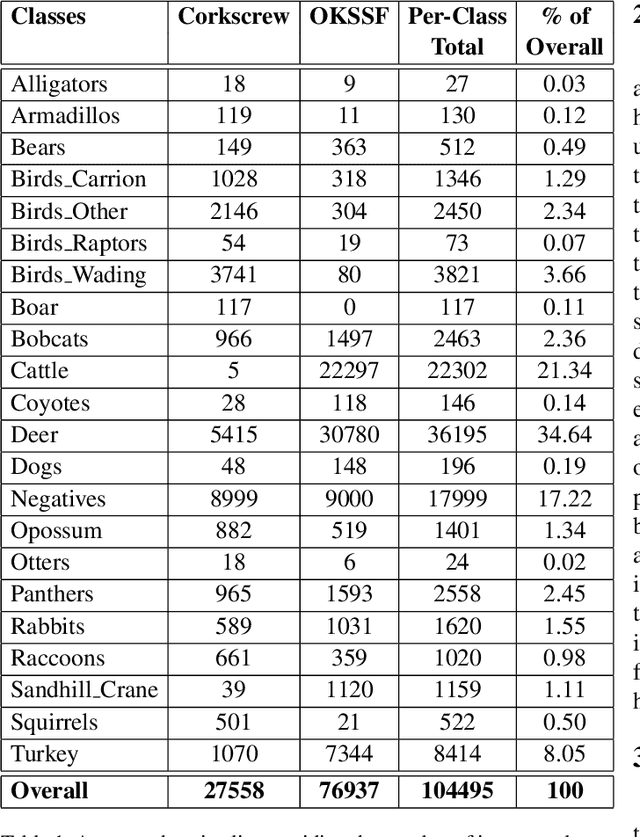

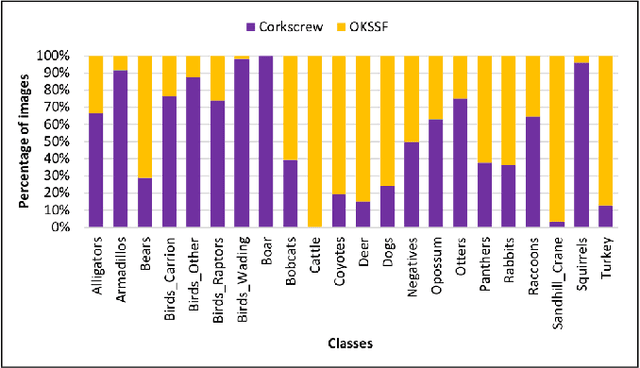

Trail camera imagery has increasingly gained popularity amongst biologists for conservation and ecological research. Minimal human interference required to operate camera traps allows capturing unbiased species activities. Several studies - based on human and wildlife interactions, migratory patterns of various species, risk of extinction in endangered populations - are limited by the lack of rich data and the time-consuming nature of manually annotating trail camera imagery. We introduce a challenging wildlife camera trap classification dataset collected from two different locations in Southwestern Florida, consisting of 104,495 images featuring visually similar species, varying illumination conditions, skewed class distribution, and including samples of endangered species, i.e. Florida panthers. Experimental evaluations with ResNet-50 architecture indicate that this image classification-based dataset can further push the advancements in wildlife statistical modeling. We will make the dataset publicly available.
Global Wheat Head Dataset 2021: more diversity to improve the benchmarking of wheat head localization methods
Jun 03, 2021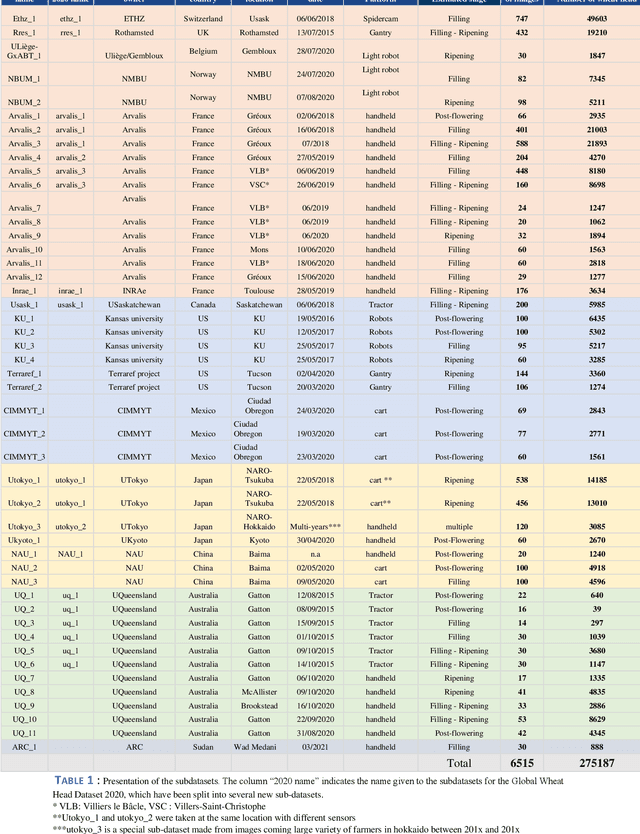
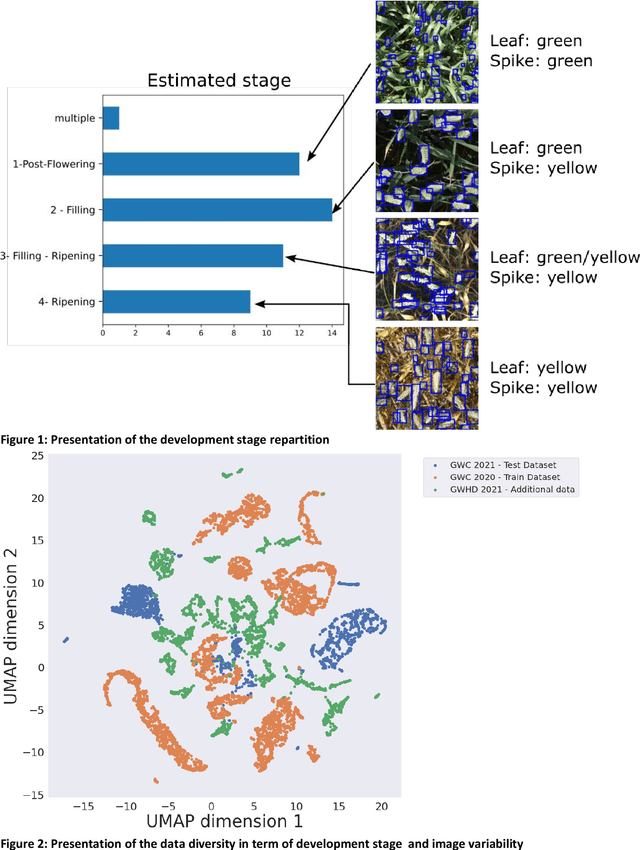
The Global Wheat Head Detection (GWHD) dataset was created in 2020 and has assembled 193,634 labelled wheat heads from 4,700 RGB images acquired from various acquisition platforms and 7 countries/institutions. With an associated competition hosted in Kaggle, GWHD has successfully attracted attention from both the computer vision and agricultural science communities. From this first experience in 2020, a few avenues for improvements have been identified, especially from the perspective of data size, head diversity and label reliability. To address these issues, the 2020 dataset has been reexamined, relabeled, and augmented by adding 1,722 images from 5 additional countries, allowing for 81,553 additional wheat heads to be added. We now release a new version of the Global Wheat Head Detection (GWHD) dataset in 2021, which is bigger, more diverse, and less noisy than the 2020 version. The GWHD 2021 is now publicly available at http://www.global-wheat.com/ and a new data challenge has been organized on AIcrowd to make use of this updated dataset.