 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCell Behavior Video Classification Challenge, a benchmark for computer vision methods in time-lapse microscopy
Jan 15, 2026The classification of microscopy videos capturing complex cellular behaviors is crucial for understanding and quantifying the dynamics of biological processes over time. However, it remains a frontier in computer vision, requiring approaches that effectively model the shape and motion of objects without rigid boundaries, extract hierarchical spatiotemporal features from entire image sequences rather than static frames, and account for multiple objects within the field of view. To this end, we organized the Cell Behavior Video Classification Challenge (CBVCC), benchmarking 35 methods based on three approaches: classification of tracking-derived features, end-to-end deep learning architectures to directly learn spatiotemporal features from the entire video sequence without explicit cell tracking, or ensembling tracking-derived with image-derived features. We discuss the results achieved by the participants and compare the potential and limitations of each approach, serving as a basis to foster the development of computer vision methods for studying cellular dynamics.
Intent3D: 3D Object Detection in RGB-D Scans Based on Human Intention
May 28, 2024



In real-life scenarios, humans seek out objects in the 3D world to fulfill their daily needs or intentions. This inspires us to introduce 3D intention grounding, a new task in 3D object detection employing RGB-D, based on human intention, such as "I want something to support my back". Closely related, 3D visual grounding focuses on understanding human reference. To achieve detection based on human intention, it relies on humans to observe the scene, reason out the target that aligns with their intention ("pillow" in this case), and finally provide a reference to the AI system, such as "A pillow on the couch". Instead, 3D intention grounding challenges AI agents to automatically observe, reason and detect the desired target solely based on human intention. To tackle this challenge, we introduce the new Intent3D dataset, consisting of 44,990 intention texts associated with 209 fine-grained classes from 1,042 scenes of the ScanNet dataset. We also establish several baselines based on different language-based 3D object detection models on our benchmark. Finally, we propose IntentNet, our unique approach, designed to tackle this intention-based detection problem. It focuses on three key aspects: intention understanding, reasoning to identify object candidates, and cascaded adaptive learning that leverages the intrinsic priority logic of different losses for multiple objective optimization.
Egocentric RGB+Depth Action Recognition in Industry-Like Settings
Sep 25, 2023
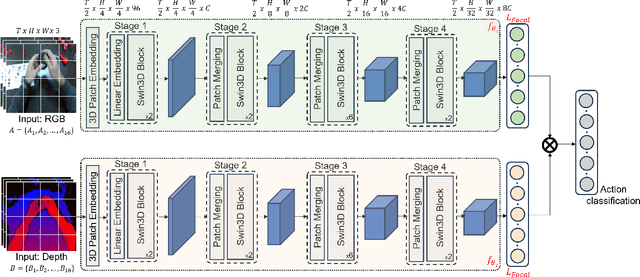
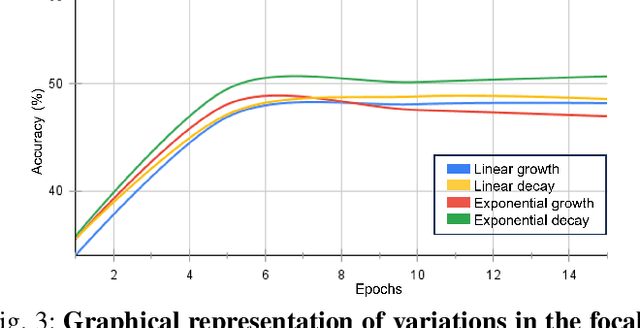
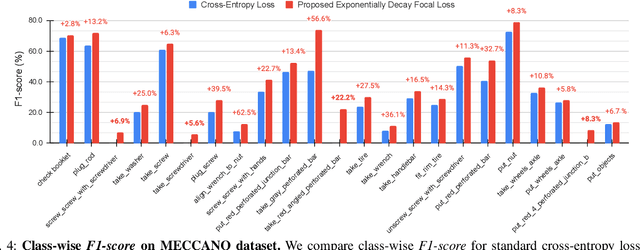
Action recognition from an egocentric viewpoint is a crucial perception task in robotics and enables a wide range of human-robot interactions. While most computer vision approaches prioritize the RGB camera, the Depth modality - which can further amplify the subtleties of actions from an egocentric perspective - remains underexplored. Our work focuses on recognizing actions from egocentric RGB and Depth modalities in an industry-like environment. To study this problem, we consider the recent MECCANO dataset, which provides a wide range of assembling actions. Our framework is based on the 3D Video SWIN Transformer to encode both RGB and Depth modalities effectively. To address the inherent skewness in real-world multimodal action occurrences, we propose a training strategy using an exponentially decaying variant of the focal loss modulating factor. Additionally, to leverage the information in both RGB and Depth modalities, we opt for late fusion to combine the predictions from each modality. We thoroughly evaluate our method on the action recognition task of the MECCANO dataset, and it significantly outperforms the prior work. Notably, our method also secured first place at the multimodal action recognition challenge at ICIAP 2023.
Ensemble Modeling for Multimodal Visual Action Recognition
Aug 10, 2023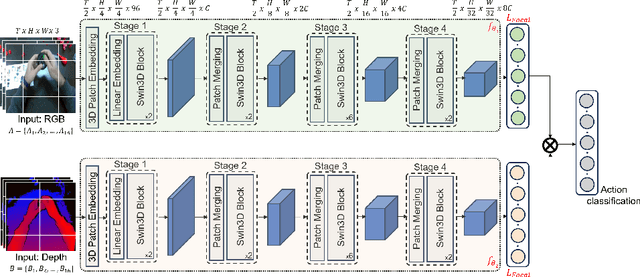
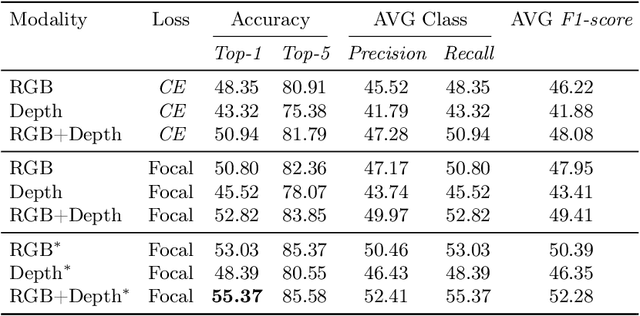
In this work, we propose an ensemble modeling approach for multimodal action recognition. We independently train individual modality models using a variant of focal loss tailored to handle the long-tailed distribution of the MECCANO [21] dataset. Based on the underlying principle of focal loss, which captures the relationship between tail (scarce) classes and their prediction difficulties, we propose an exponentially decaying variant of focal loss for our current task. It initially emphasizes learning from the hard misclassified examples and gradually adapts to the entire range of examples in the dataset. This annealing process encourages the model to strike a balance between focusing on the sparse set of hard samples, while still leveraging the information provided by the easier ones. Additionally, we opt for the late fusion strategy to combine the resultant probability distributions from RGB and Depth modalities for final action prediction. Experimental evaluations on the MECCANO dataset demonstrate the effectiveness of our approach.
3DMODT: Attention-Guided Affinities for Joint Detection & Tracking in 3D Point Clouds
Nov 01, 2022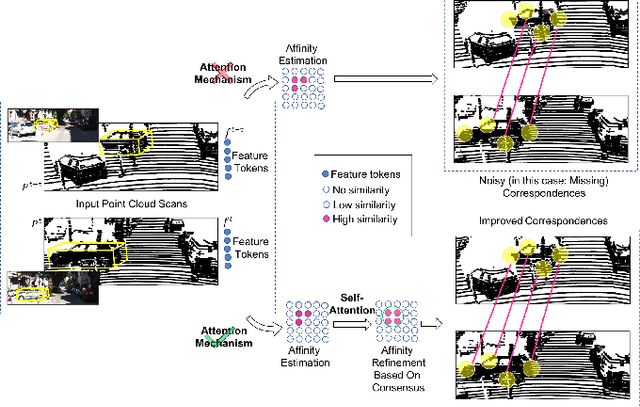
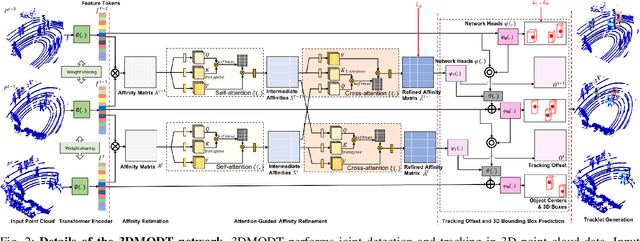

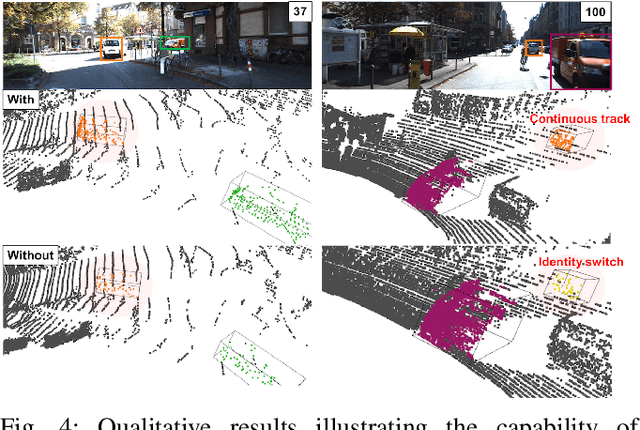
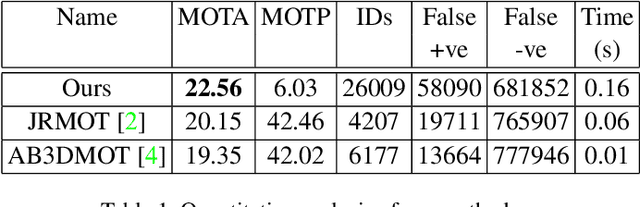
We propose a method for joint detection and tracking of multiple objects in 3D point clouds, a task conventionally treated as a two-step process comprising object detection followed by data association. Our method embeds both steps into a single end-to-end trainable network eliminating the dependency on external object detectors. Our model exploits temporal information employing multiple frames to detect objects and track them in a single network, thereby making it a utilitarian formulation for real-world scenarios. Computing affinity matrix by employing features similarity across consecutive point cloud scans forms an integral part of visual tracking. We propose an attention-based refinement module to refine the affinity matrix by suppressing erroneous correspondences. The module is designed to capture the global context in affinity matrix by employing self-attention within each affinity matrix and cross-attention across a pair of affinity matrices. Unlike competing approaches, our network does not require complex post-processing algorithms, and processes raw LiDAR frames to directly output tracking results. We demonstrate the effectiveness of our method on the three tracking benchmarks: JRDB, Waymo, and KITTI. Experimental evaluations indicate the ability of our model to generalize well across datasets.
Self-Supervised Video Object Segmentation via Cutout Prediction and Tagging
Apr 22, 2022


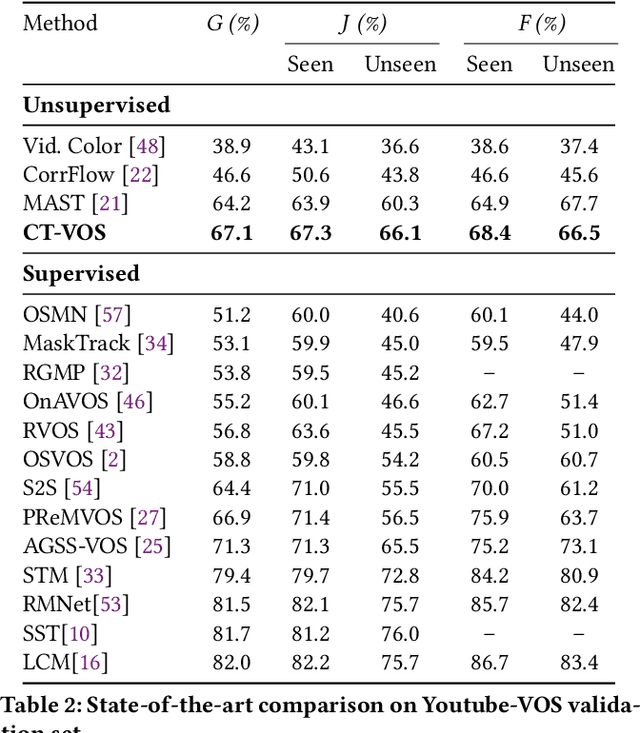
We propose a novel self-supervised Video Object Segmentation (VOS) approach that strives to achieve better object-background discriminability for accurate object segmentation. Distinct from previous self-supervised VOS methods, our approach is based on a discriminative learning loss formulation that takes into account both object and background information to ensure object-background discriminability, rather than using only object appearance. The discriminative learning loss comprises cutout-based reconstruction (cutout region represents part of a frame, whose pixels are replaced with some constant values) and tag prediction loss terms. The cutout-based reconstruction term utilizes a simple cutout scheme to learn the pixel-wise correspondence between the current and previous frames in order to reconstruct the original current frame with added cutout region in it. The introduced cutout patch guides the model to focus as much on the significant features of the object of interest as the less significant ones, thereby implicitly equipping the model to address occlusion-based scenarios. Next, the tag prediction term encourages object-background separability by grouping tags of all pixels in the cutout region that are similar, while separating them from the tags of the rest of the reconstructed frame pixels. Additionally, we introduce a zoom-in scheme that addresses the problem of small object segmentation by capturing fine structural information at multiple scales. Our proposed approach, termed CT-VOS, achieves state-of-the-art results on two challenging benchmarks: DAVIS-2017 and Youtube-VOS. A detailed ablation showcases the importance of the proposed loss formulation to effectively capture object-background discriminability and the impact of our zoom-in scheme to accurately segment small-sized objects.
Tag-Based Attention Guided Bottom-Up Approach for Video Instance Segmentation
Apr 22, 2022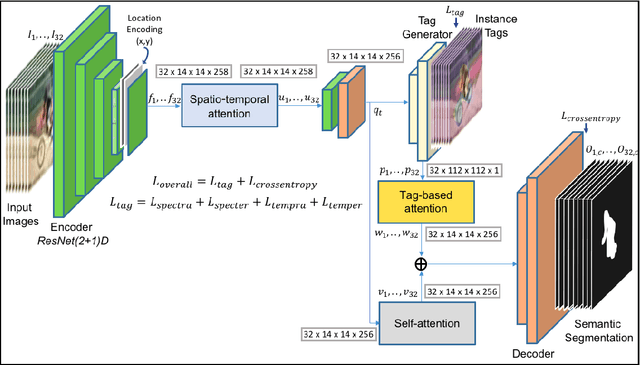



Video Instance Segmentation is a fundamental computer vision task that deals with segmenting and tracking object instances across a video sequence. Most existing methods typically accomplish this task by employing a multi-stage top-down approach that usually involves separate networks to detect and segment objects in each frame, followed by associating these detections in consecutive frames using a learned tracking head. In this work, however, we introduce a simple end-to-end trainable bottom-up approach to achieve instance mask predictions at the pixel-level granularity, instead of the typical region-proposals-based approach. Unlike contemporary frame-based models, our network pipeline processes an input video clip as a single 3D volume to incorporate temporal information. The central idea of our formulation is to solve the video instance segmentation task as a tag assignment problem, such that generating distinct tag values essentially separates individual object instances across the video sequence (here each tag could be any arbitrary value between 0 and 1). To this end, we propose a novel spatio-temporal tagging loss that allows for sufficient separation of different objects as well as necessary identification of different instances of the same object. Furthermore, we present a tag-based attention module that improves instance tags, while concurrently learning instance propagation within a video. Evaluations demonstrate that our method provides competitive results on YouTube-VIS and DAVIS-19 datasets, and has minimum run-time compared to other state-of-the-art performance methods.
Florida Wildlife Camera Trap Dataset
Jun 23, 2021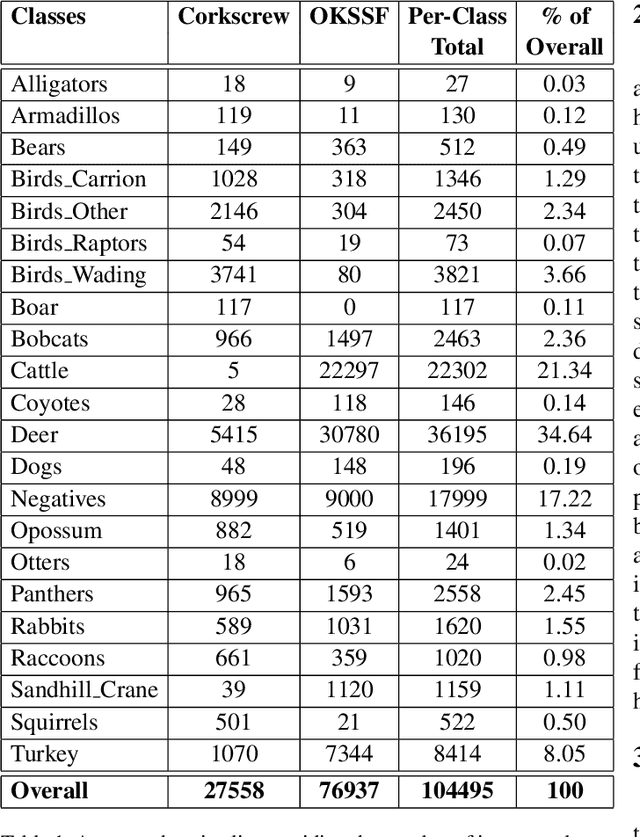

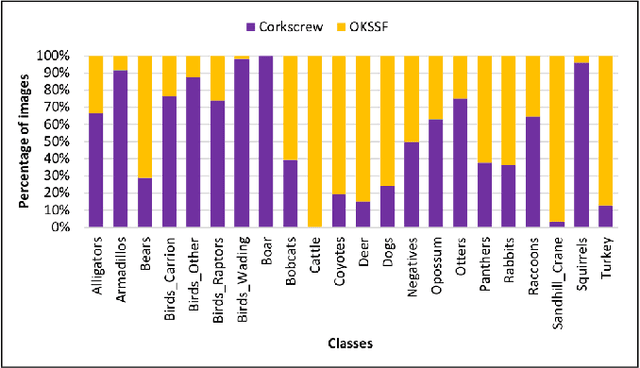

Trail camera imagery has increasingly gained popularity amongst biologists for conservation and ecological research. Minimal human interference required to operate camera traps allows capturing unbiased species activities. Several studies - based on human and wildlife interactions, migratory patterns of various species, risk of extinction in endangered populations - are limited by the lack of rich data and the time-consuming nature of manually annotating trail camera imagery. We introduce a challenging wildlife camera trap classification dataset collected from two different locations in Southwestern Florida, consisting of 104,495 images featuring visually similar species, varying illumination conditions, skewed class distribution, and including samples of endangered species, i.e. Florida panthers. Experimental evaluations with ResNet-50 architecture indicate that this image classification-based dataset can further push the advancements in wildlife statistical modeling. We will make the dataset publicly available.
PC-DAN: Point Cloud based Deep Affinity Network for 3D Multi-Object Tracking
Jun 03, 2021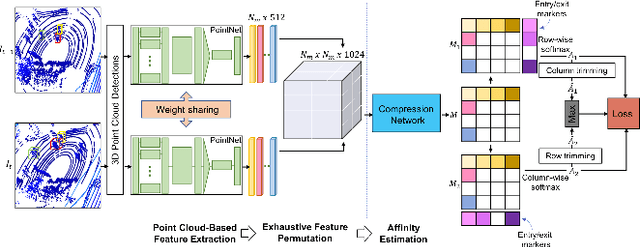
In recent times, the scope of LIDAR (Light Detection and Ranging) sensor-based technology has spread across numerous fields. It is popularly used to map terrain and navigation information into reliable 3D point cloud data, potentially revolutionizing the autonomous vehicles and assistive robotic industry. A point cloud is a dense compilation of spatial data in 3D coordinates. It plays a vital role in modeling complex real-world scenes since it preserves structural information and avoids perspective distortion, unlike image data, which is the projection of a 3D structure on a 2D plane. In order to leverage the intrinsic capabilities of the LIDAR data, we propose a PointNet-based approach for 3D Multi-Object Tracking (MOT).