 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag-Based Attention Guided Bottom-Up Approach for Video Instance Segmentation
Paper and Code
Apr 22, 2022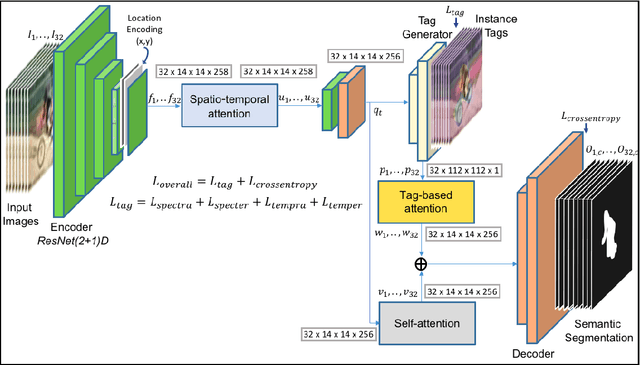



Video Instance Segmentation is a fundamental computer vision task that deals with segmenting and tracking object instances across a video sequence. Most existing methods typically accomplish this task by employing a multi-stage top-down approach that usually involves separate networks to detect and segment objects in each frame, followed by associating these detections in consecutive frames using a learned tracking head. In this work, however, we introduce a simple end-to-end trainable bottom-up approach to achieve instance mask predictions at the pixel-level granularity, instead of the typical region-proposals-based approach. Unlike contemporary frame-based models, our network pipeline processes an input video clip as a single 3D volume to incorporate temporal information. The central idea of our formulation is to solve the video instance segmentation task as a tag assignment problem, such that generating distinct tag values essentially separates individual object instances across the video sequence (here each tag could be any arbitrary value between 0 and 1). To this end, we propose a novel spatio-temporal tagging loss that allows for sufficient separation of different objects as well as necessary identification of different instances of the same object. Furthermore, we present a tag-based attention module that improves instance tags, while concurrently learning instance propagation within a video. Evaluations demonstrate that our method provides competitive results on YouTube-VIS and DAVIS-19 datasets, and has minimum run-time compared to other state-of-the-art performance methods.