 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric RGB+Depth Action Recognition in Industry-Like Settings
Paper and Code
Sep 25, 2023
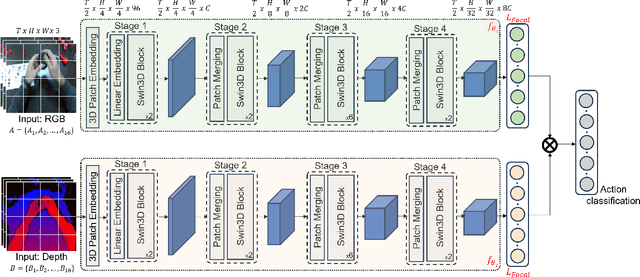
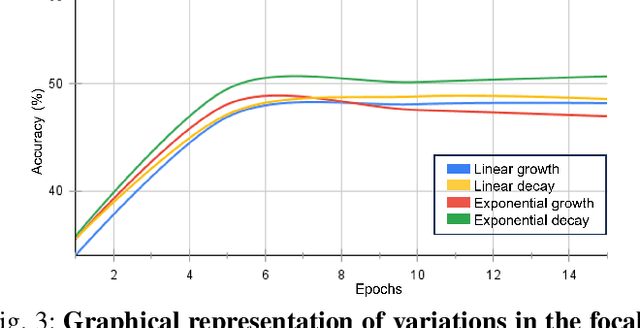
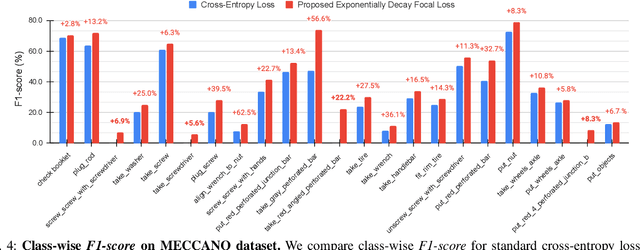
Action recognition from an egocentric viewpoint is a crucial perception task in robotics and enables a wide range of human-robot interactions. While most computer vision approaches prioritize the RGB camera, the Depth modality - which can further amplify the subtleties of actions from an egocentric perspective - remains underexplored. Our work focuses on recognizing actions from egocentric RGB and Depth modalities in an industry-like environment. To study this problem, we consider the recent MECCANO dataset, which provides a wide range of assembling actions. Our framework is based on the 3D Video SWIN Transformer to encode both RGB and Depth modalities effectively. To address the inherent skewness in real-world multimodal action occurrences, we propose a training strategy using an exponentially decaying variant of the focal loss modulating factor. Additionally, to leverage the information in both RGB and Depth modalities, we opt for late fusion to combine the predictions from each modality. We thoroughly evaluate our method on the action recognition task of the MECCANO dataset, and it significantly outperforms the prior work. Notably, our method also secured first place at the multimodal action recognition challenge at ICIAP 2023.