 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DMODT: Attention-Guided Affinities for Joint Detection & Tracking in 3D Point Clouds
Paper and Code
Nov 01, 2022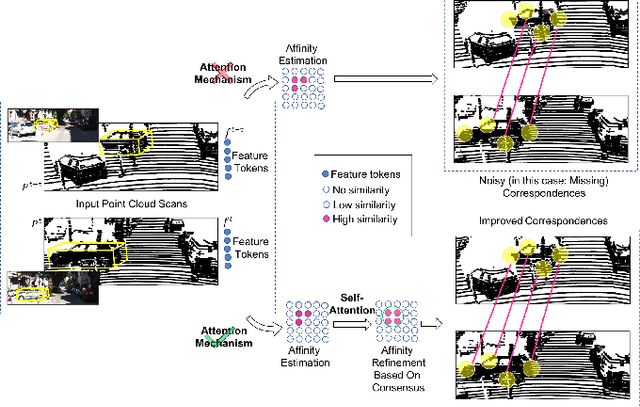
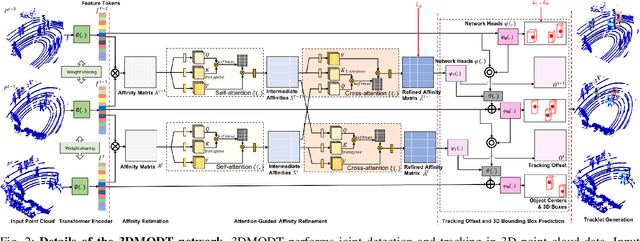

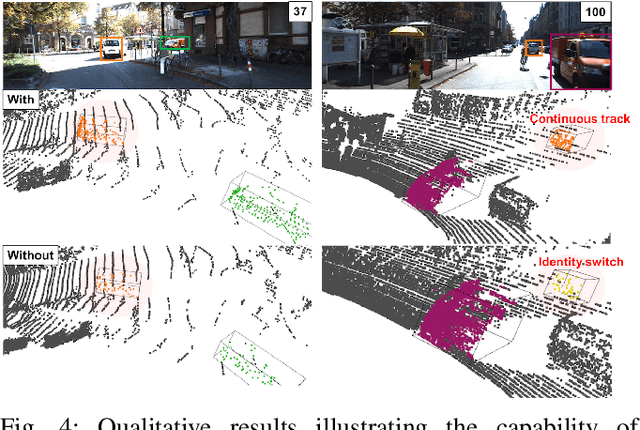
We propose a method for joint detection and tracking of multiple objects in 3D point clouds, a task conventionally treated as a two-step process comprising object detection followed by data association. Our method embeds both steps into a single end-to-end trainable network eliminating the dependency on external object detectors. Our model exploits temporal information employing multiple frames to detect objects and track them in a single network, thereby making it a utilitarian formulation for real-world scenarios. Computing affinity matrix by employing features similarity across consecutive point cloud scans forms an integral part of visual tracking. We propose an attention-based refinement module to refine the affinity matrix by suppressing erroneous correspondences. The module is designed to capture the global context in affinity matrix by employing self-attention within each affinity matrix and cross-attention across a pair of affinity matrices. Unlike competing approaches, our network does not require complex post-processing algorithms, and processes raw LiDAR frames to directly output tracking results. We demonstrate the effectiveness of our method on the three tracking benchmarks: JRDB, Waymo, and KITTI. Experimental evaluations indicate the ability of our model to generalize well across datasets.