 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Imitate Logical Reasoning, but at what Cost?
Sep 16, 2025We present a longitudinal study which evaluates the reasoning capability of frontier Large Language Models over an eighteen month period. We measured the accuracy of three leading models from December 2023, September 2024 and June 2025 on true or false questions from the PrOntoQA dataset and their faithfulness to reasoning strategies provided through in-context learning. The improvement in performance from 2023 to 2024 can be attributed to hidden Chain of Thought prompting. The introduction of thinking models allowed for significant improvement in model performance between 2024 and 2025. We then present a neuro-symbolic architecture which uses LLMs of less than 15 billion parameters to translate the problems into a standardised form. We then parse the standardised forms of the problems into a program to be solved by Z3, an SMT solver, to determine the satisfiability of the query. We report the number of prompt and completion tokens as well as the computational cost in FLOPs for open source models. The neuro-symbolic approach significantly reduces the computational cost while maintaining near perfect performance. The common approximation that the number of inference FLOPs is double the product of the active parameters and total tokens was accurate within 10\% for all experiments.
Large Language Models' Reasoning Stalls: An Investigation into the Capabilities of Frontier Models
May 26, 2025Empirical methods to examine the capability of Large Language Models (LLMs) to use Automated Theorem Prover (ATP) reasoning strategies are studied. We evaluate the performance of State of the Art models from December 2023 and August 2024 on PRONTOQA steamroller reasoning problems. For that, we develop methods for assessing LLM response accuracy and correct answer correlation. Our results show that progress in improving LLM reasoning abilities has stalled over the nine month period. By tracking completion tokens, we show that almost all improvement in reasoning ability since GPT-4 was released can be attributed to either hidden system prompts or the training of models to automatically use generic Chain of Thought prompting strategies. Among the ATP reasoning strategies tried, we found that current frontier LLMs are best able to follow the bottom-up (also known as forward-chaining) strategy. A low positive correlation was found between an LLM response containing correct reasoning and arriving at the correct conclusion.
Highlighting Case Studies in LLM Literature Review of Interdisciplinary System Science
Mar 16, 2025Large Language Models (LLMs) were used to assist four Commonwealth Scientific and Industrial Research Organisation (CSIRO) researchers to perform systematic literature reviews (SLR). We evaluate the performance of LLMs for SLR tasks in these case studies. In each, we explore the impact of changing parameters on the accuracy of LLM responses. The LLM was tasked with extracting evidence from chosen academic papers to answer specific research questions. We evaluate the models' performance in faithfully reproducing quotes from the literature and subject experts were asked to assess the model performance in answering the research questions. We developed a semantic text highlighting tool to facilitate expert review of LLM responses. We found that state of the art LLMs were able to reproduce quotes from texts with greater than 95% accuracy and answer research questions with an accuracy of approximately 83%. We use two methods to determine the correctness of LLM responses; expert review and the cosine similarity of transformer embeddings of LLM and expert answers. The correlation between these methods ranged from 0.48 to 0.77, providing evidence that the latter is a valid metric for measuring semantic similarity.
CON-FOLD -- Explainable Machine Learning with Confidence
Aug 14, 2024FOLD-RM is an explainable machine learning classification algorithm that uses training data to create a set of classification rules. In this paper we introduce CON-FOLD which extends FOLD-RM in several ways. CON-FOLD assigns probability-based confidence scores to rules learned for a classification task. This allows users to know how confident they should be in a prediction made by the model. We present a confidence-based pruning algorithm that uses the unique structure of FOLD-RM rules to efficiently prune rules and prevent overfitting. Furthermore, CON-FOLD enables the user to provide pre-existing knowledge in the form of logic program rules that are either (fixed) background knowledge or (modifiable) initial rule candidates. The paper describes our method in detail and reports on practical experiments. We demonstrate the performance of the algorithm on benchmark datasets from the UCI Machine Learning Repository. For that, we introduce a new metric, Inverse Brier Score, to evaluate the accuracy of the produced confidence scores. Finally we apply this extension to a real world example that requires explainability: marking of student responses to a short answer question from the Australian Physics Olympiad.
Automated Theorem Provers Help Improve Large Language Model Reasoning
Aug 07, 2024In this paper we demonstrate how logic programming systems and Automated first-order logic Theorem Provers (ATPs) can improve the accuracy of Large Language Models (LLMs) for logical reasoning tasks where the baseline performance is given by direct LLM solutions. We first evaluate LLM reasoning on steamroller problems using the PRONTOQA benchmark. We show how accuracy can be improved with a neuro-symbolic architecture where the LLM acts solely as a front-end for translating a given problem into a formal logic language and an automated reasoning engine is called for solving it. However, this approach critically hinges on the correctness of the LLM translation. To assess this translation correctness, we secondly define a framework of syntactic and semantic error categories. We implemented the framework and used it to identify errors that LLMs make in the benchmark domain. Based on these findings, we thirdly extended our method with capabilities for automatically correcting syntactic and semantic errors. For semantic error correction we integrate first-order logic ATPs, which is our main and novel contribution. We demonstrate that this approach reduces semantic errors significantly and further increases the accurracy of LLM logical reasoning.
Bottom-Up Grounding in the Probabilistic Logic Programming System Fusemate
Jun 13, 2023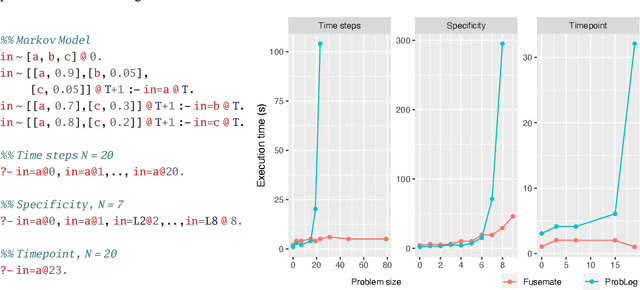

This paper introduces the Fusemate probabilistic logic programming system. Fusemate's inference engine comprises a grounding component and a variable elimination method for probabilistic inference. Fusemate differs from most other systems by grounding the program in a bottom-up way instead of the common top-down way. While bottom-up grounding is attractive for a number of reasons, e.g., for dynamically creating distributions of varying support sizes, it makes it harder to control the amount of ground clauses generated. We address this problem by interleaving grounding with a query-guided relevance test which prunes rules whose bodies are inconsistent with the query. We present our method in detail and demonstrate it with examples that involve "time", such as (hidden) Markov models. Our experiments demonstrate competitive or better performance compared to a state-of-the art probabilistic logic programming system, in particular for high branching problems.
Movement Analytics: Current Status, Application to Manufacturing, and Future Prospects from an AI Perspective
Oct 04, 2022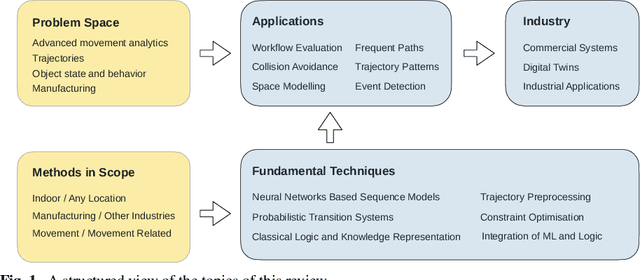
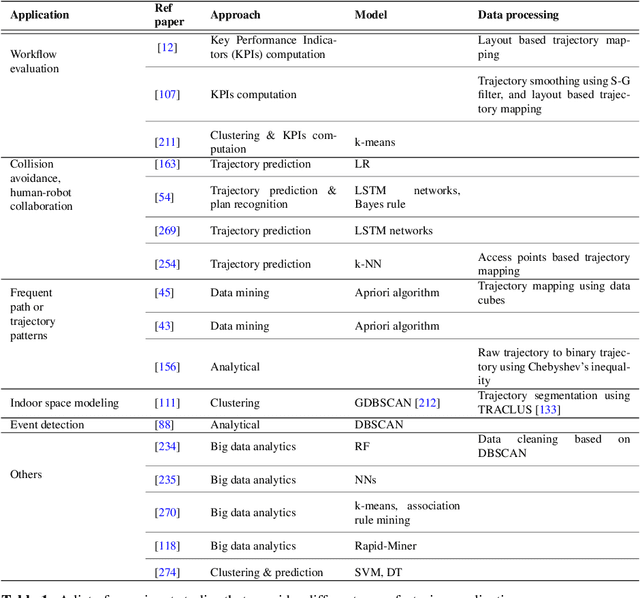
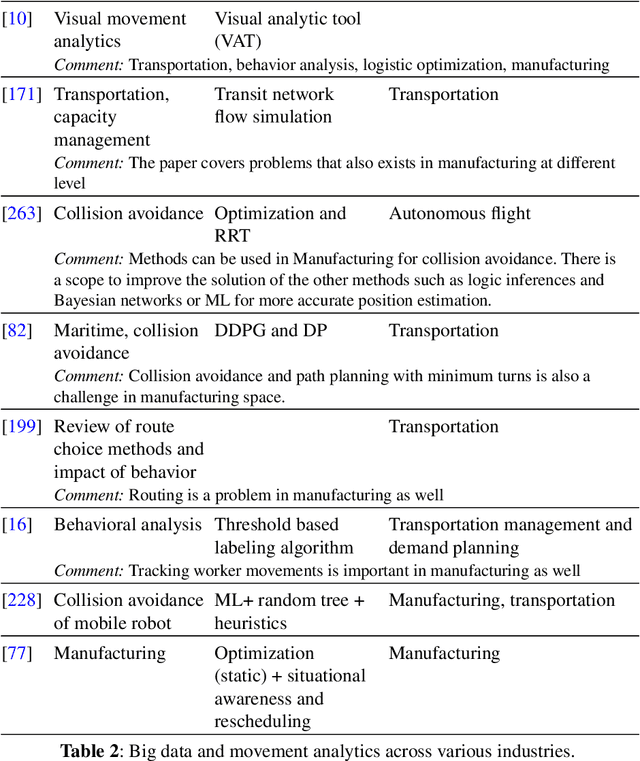
Data-driven decision making is becoming an integral part of manufacturing companies. Data is collected and commonly used to improve efficiency and produce high quality items for the customers. IoT-based and other forms of object tracking are an emerging tool for collecting movement data of objects/entities (e.g. human workers, moving vehicles, trolleys etc.) over space and time. Movement data can provide valuable insights like process bottlenecks, resource utilization, effective working time etc. that can be used for decision making and improving efficiency. Turning movement data into valuable information for industrial management and decision making requires analysis methods. We refer to this process as movement analytics. The purpose of this document is to review the current state of work for movement analytics both in manufacturing and more broadly. We survey relevant work from both a theoretical perspective and an application perspective. From the theoretical perspective, we put an emphasis on useful methods from two research areas: machine learning, and logic-based knowledge representation. We also review their combinations in view of movement analytics, and we discuss promising areas for future development and application. Furthermore, we touch on constraint optimization. From an application perspective, we review applications of these methods to movement analytics in a general sense and across various industries. We also describe currently available commercial off-the-shelf products for tracking in manufacturing, and we overview main concepts of digital twins and their applications.
North Carolina COVID-19 Agent-Based Model Framework for Hospitalization Forecasting Overview, Design Concepts, and Details Protocol
Jun 08, 2021

This Overview, Design Concepts, and Details Protocol (ODD) provides a detailed description of an agent-based model (ABM) that was developed to simulate hospitalizations during the COVID-19 pandemic. Using the descriptions of submodels, provided parameters, and the links to data sources, modelers will be able to replicate the creation and results of this model.
SMART: An Open Source Data Labeling Platform for Supervised Learning
Dec 11, 2018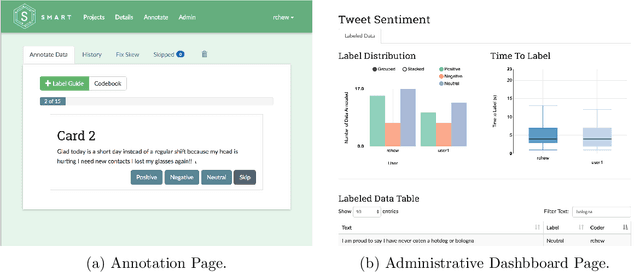
SMART is an open source web application designed to help data scientists and research teams efficiently build labeled training data sets for supervised machine learning tasks. SMART provides users with an intuitive interface for creating labeled data sets, supports active learning to help reduce the required amount of labeled data, and incorporates inter-rater reliability statistics to provide insight into label quality. SMART is designed to be platform agnostic and easily deployable to meet the needs of as many different research teams as possible. The project website contains links to the code repository and extensive user documentation.
Tableaux for Policy Synthesis for MDPs with PCTL* Constraints
Oct 06, 2017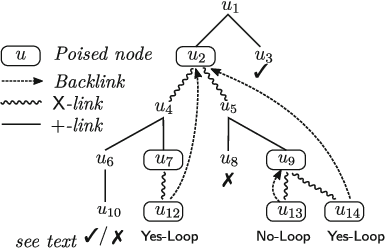
Markov decision processes (MDPs) are the standard formalism for modelling sequential decision making in stochastic environments. Policy synthesis addresses the problem of how to control or limit the decisions an agent makes so that a given specification is met. In this paper we consider PCTL*, the probabilistic counterpart of CTL*, as the specification language. Because in general the policy synthesis problem for PCTL* is undecidable, we restrict to policies whose execution history memory is finitely bounded a priori. Surprisingly, no algorithm for policy synthesis for this natural and expressive framework has been developed so far. We close this gap and describe a tableau-based algorithm that, given an MDP and a PCTL* specification, derives in a non-deterministic way a system of (possibly nonlinear) equalities and inequalities. The solutions of this system, if any, describe the desired (stochastic) policies. Our main result in this paper is the correctness of our method, i.e., soundness, completeness and termination.
* This is a long version of a conference paper published at TABLEAUX 2017. It contains proofs of the main results and fixes a bug. See the footnote on page 1 for details