 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Constrained Stochastic Shortest Path Problems with Scalarisation
Aug 24, 2025Constrained Stochastic Shortest Path Problems (CSSPs) model problems with probabilistic effects, where a primary cost is minimised subject to constraints over secondary costs, e.g., minimise time subject to monetary budget. Current heuristic search algorithms for CSSPs solve a sequence of increasingly larger CSSPs as linear programs until an optimal solution for the original CSSP is found. In this paper, we introduce a novel algorithm CARL, which solves a series of unconstrained Stochastic Shortest Path Problems (SSPs) with efficient heuristic search algorithms. These SSP subproblems are constructed with scalarisations that project the CSSP's vector of primary and secondary costs onto a scalar cost. CARL finds a maximising scalarisation using an optimisation algorithm similar to the subgradient method which, together with the solution to its associated SSP, yields a set of policies that are combined into an optimal policy for the CSSP. Our experiments show that CARL solves 50% more problems than the state-of-the-art on existing benchmarks.
Leveraging Action Relational Structures for Integrated Learning and Planning
Apr 29, 2025Recent advances in planning have explored using learning methods to help planning. However, little attention has been given to adapting search algorithms to work better with learning systems. In this paper, we introduce partial-space search, a new search space for classical planning that leverages the relational structure of actions given by PDDL action schemas -- a structure overlooked by traditional planning approaches. Partial-space search provides a more granular view of the search space and allows earlier pruning of poor actions compared to state-space search. To guide partial-space search, we introduce action set heuristics that evaluate sets of actions in a state. We describe how to automatically convert existing heuristics into action set heuristics. We also train action set heuristics from scratch using large training datasets from partial-space search. Our new planner, LazyLifted, exploits our better integrated search and learning heuristics and outperforms the state-of-the-art ML-based heuristic on IPC 2023 learning track (LT) benchmarks. We also show the efficiency of LazyLifted on high-branching factor tasks and show that it surpasses LAMA in the combined IPC 2023 LT and high-branching factor benchmarks.
Learning Efficiency Meets Symmetry Breaking
Apr 28, 2025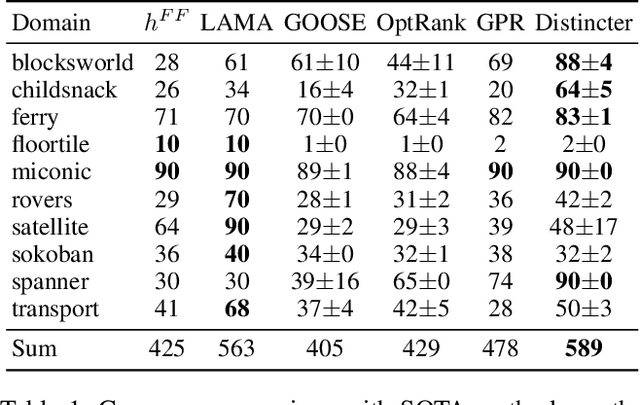
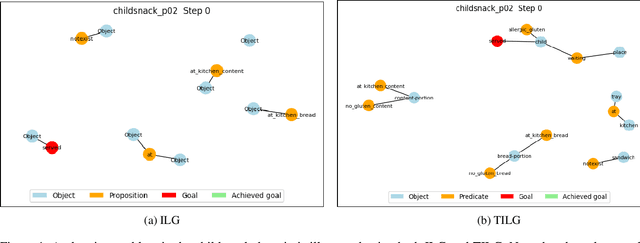
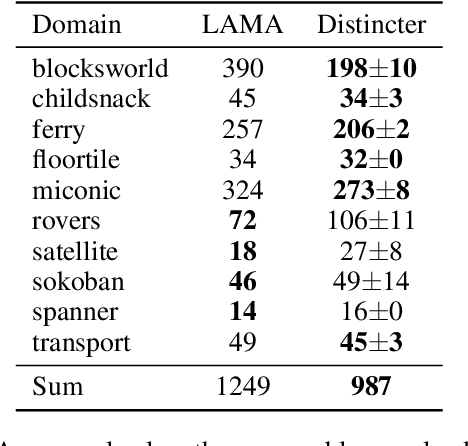
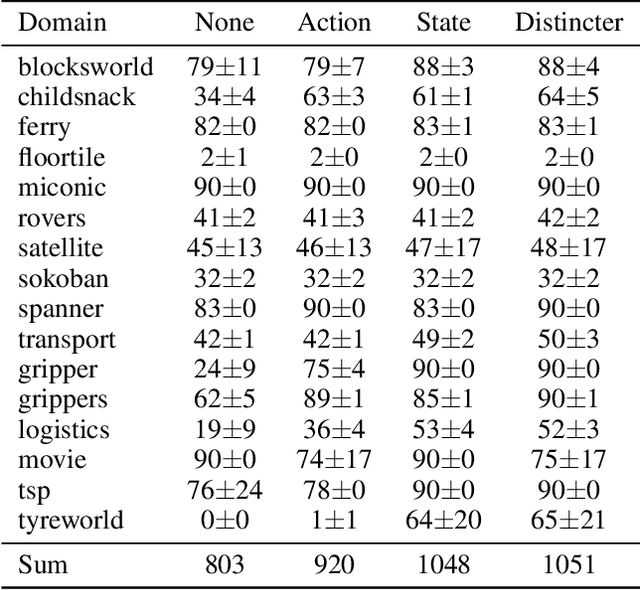
Learning-based planners leveraging Graph Neural Networks can learn search guidance applicable to large search spaces, yet their potential to address symmetries remains largely unexplored. In this paper, we introduce a graph representation of planning problems allying learning efficiency with the ability to detect symmetries, along with two pruning methods, action pruning and state pruning, designed to manage symmetries during search. The integration of these techniques into Fast Downward achieves a first-time success over LAMA on the latest IPC learning track dataset. Code is released at: https://github.com/bybeye/Distincter.
Graph Learning for Planning: The Story Thus Far and Open Challenges
Dec 03, 2024



Graph learning is naturally well suited for use in planning due to its ability to exploit relational structures exhibited in planning domains and to take as input planning instances with arbitrary number of objects. In this paper, we study the usage of graph learning for planning thus far by studying the theoretical and empirical effects on learning and planning performance of (1) graph representations of planning tasks, (2) graph learning architectures, and (3) optimisation formulations for learning. Our studies accumulate in the GOOSE framework which learns domain knowledge from small planning tasks in order to scale up to much larger planning tasks. In this paper, we also highlight and propose the 5 open challenges in the general Learning for Planning field that we believe need to be addressed for advancing the state-of-the-art.
Return to Tradition: Learning Reliable Heuristics with Classical Machine Learning
Mar 25, 2024
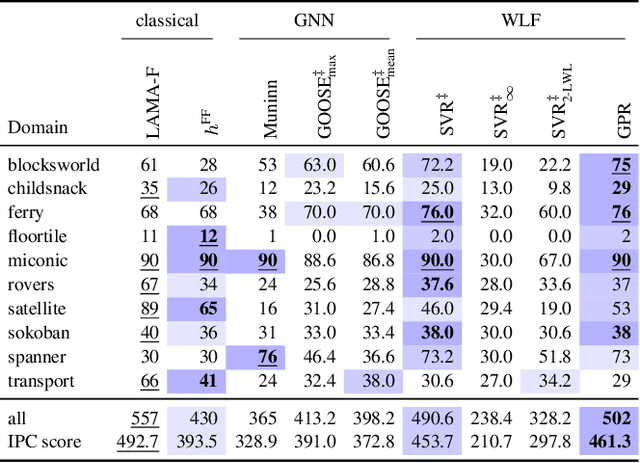
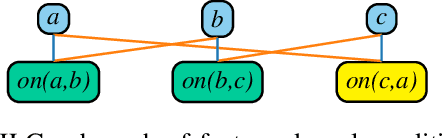
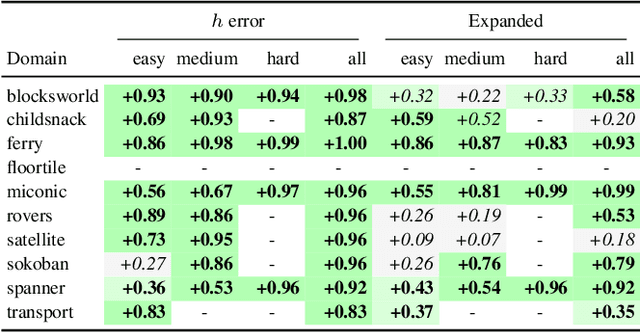
Current approaches for learning for planning have yet to achieve competitive performance against classical planners in several domains, and have poor overall performance. In this work, we construct novel graph representations of lifted planning tasks and use the WL algorithm to generate features from them. These features are used with classical machine learning methods which have up to 2 orders of magnitude fewer parameters and train up to 3 orders of magnitude faster than the state-of-the-art deep learning for planning models. Our novel approach, WL-GOOSE, reliably learns heuristics from scratch and outperforms the $h^{\text{FF}}$ heuristic in a fair competition setting. It also outperforms or ties with LAMA on 4 out of 10 domains on coverage and 7 out of 10 domains on plan quality. WL-GOOSE is the first learning for planning model which achieves these feats. Furthermore, we study the connections between our novel WL feature generation method, previous theoretically flavoured learning architectures, and Description Logic Features for planning.
Efficient Constraint Generation for Stochastic Shortest Path Problems
Jan 26, 2024



Current methods for solving Stochastic Shortest Path Problems (SSPs) find states' costs-to-go by applying Bellman backups, where state-of-the-art methods employ heuristics to select states to back up and prune. A fundamental limitation of these algorithms is their need to compute the cost-to-go for every applicable action during each state backup, leading to unnecessary computation for actions identified as sub-optimal. We present new connections between planning and operations research and, using this framework, we address this issue of unnecessary computation by introducing an efficient version of constraint generation for SSPs. This technique allows algorithms to ignore sub-optimal actions and avoid computing their costs-to-go. We also apply our novel technique to iLAO* resulting in a new algorithm, CG-iLAO*. Our experiments show that CG-iLAO* ignores up to 57% of iLAO*'s actions and it solves problems up to 8x and 3x faster than LRTDP and iLAO*.
Learning Domain-Independent Heuristics for Grounded and Lifted Planning
Dec 20, 2023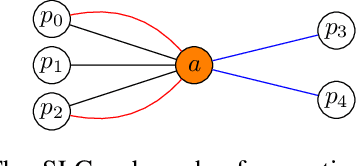
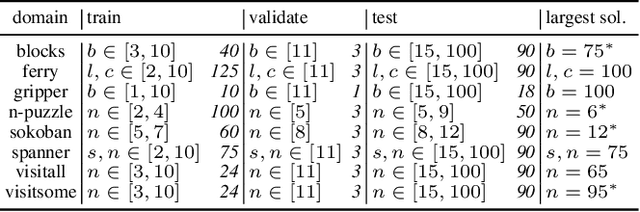
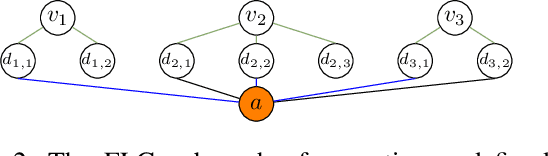
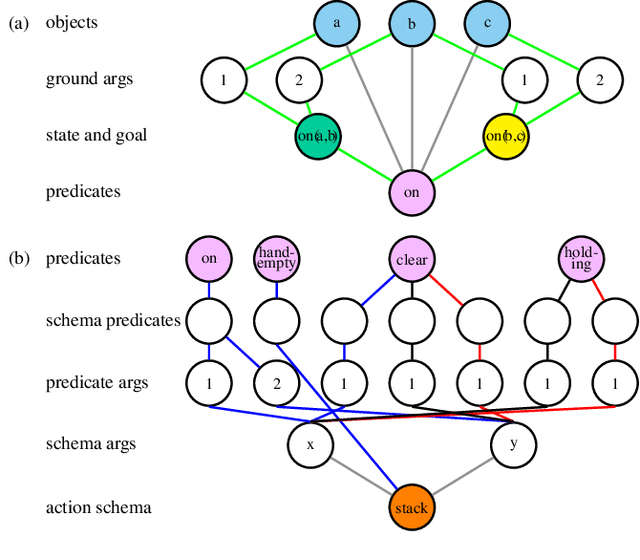
We present three novel graph representations of planning tasks suitable for learning domain-independent heuristics using Graph Neural Networks (GNNs) to guide search. In particular, to mitigate the issues caused by large grounded GNNs we present the first method for learning domain-independent heuristics with only the lifted representation of a planning task. We also provide a theoretical analysis of the expressiveness of our models, showing that some are more powerful than STRIPS-HGN, the only other existing model for learning domain-independent heuristics. Our experiments show that our heuristics generalise to much larger problems than those in the training set, vastly surpassing STRIPS-HGN heuristics.
Heuristic Search for Multi-Objective Probabilistic Planning
Mar 25, 2023Heuristic search is a powerful approach that has successfully been applied to a broad class of planning problems, including classical planning, multi-objective planning, and probabilistic planning modelled as a stochastic shortest path (SSP) problem. Here, we extend the reach of heuristic search to a more expressive class of problems, namely multi-objective stochastic shortest paths (MOSSPs), which require computing a coverage set of non-dominated policies. We design new heuristic search algorithms MOLAO* and MOLRTDP, which extend well-known SSP algorithms to the multi-objective case. We further construct a spectrum of domain-independent heuristic functions differing in their ability to take into account the stochastic and multi-objective features of the problem to guide the search. Our experiments demonstrate the benefits of these algorithms and the relative merits of the heuristics.
Learning Domain-Independent Planning Heuristics with Hypergraph Networks
Nov 29, 2019
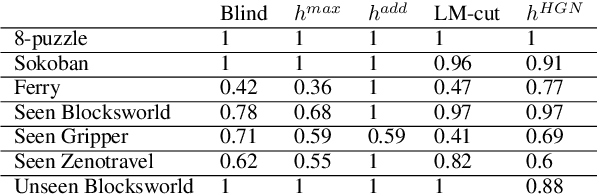
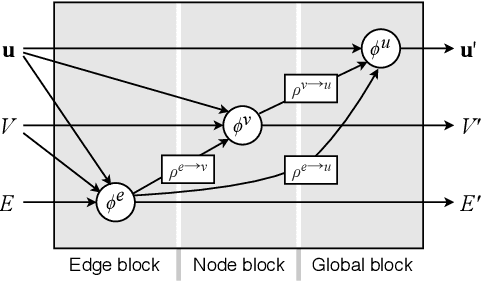

We present the first approach capable of learning domain-independent planning heuristics entirely from scratch. The heuristics we learn map the hypergraph representation of the delete-relaxation of the planning problem at hand, to a cost estimate that approximates that of the least-cost path from the current state to the goal through the hypergraph. We generalise Graph Networks to obtain a new framework for learning over hypergraphs, which we specialise to learn planning heuristics by training over state/value pairs obtained from optimal cost plans. Our experiments show that the resulting architecture, STRIPS-HGNs, is capable of learning heuristics that are competitive with existing delete-relaxation heuristics including LM-cut. We show that the heuristics we learn are able to generalise across different problems and domains, including to domains that were not seen during training.
ASNets: Deep Learning for Generalised Planning
Aug 04, 2019



In this paper, we discuss the learning of generalised policies for probabilistic and classical planning problems using Action Schema Networks (ASNets). The ASNet is a neural network architecture that exploits the relational structure of (P)PDDL planning problems to learn a common set of weights that can be applied to any problem in a domain. By mimicking the actions chosen by a traditional, non-learning planner on a handful of small problems in a domain, ASNets are able to learn a generalised reactive policy that can quickly solve much larger instances from the domain. This work extends the ASNet architecture to make it more expressive, while still remaining invariant to a range of symmetries that exist in PPDDL problems. We also present a thorough experimental evaluation of ASNets, including a comparison with heuristic search planners on seven probabilistic and deterministic domains, an extended evaluation on over 18,000 Blocksworld instances, and an ablation study. Finally, we show that sparsity-inducing regularisation can produce ASNets that are compact enough for humans to understand, yielding insights into how the structure of ASNets allows them to generalise across a domain.