 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication and Validation of Geospatial Foundation Model Data for the Prediction of Health Facility Programmatic Outputs -- A Case Study in Malawi
Oct 29, 2025



The reliability of routine health data in low and middle-income countries (LMICs) is often constrained by reporting delays and incomplete coverage, necessitating the exploration of novel data sources and analytics. Geospatial Foundation Models (GeoFMs) offer a promising avenue by synthesizing diverse spatial, temporal, and behavioral data into mathematical embeddings that can be efficiently used for downstream prediction tasks. This study evaluated the predictive performance of three GeoFM embedding sources - Google Population Dynamics Foundation Model (PDFM), Google AlphaEarth (derived from satellite imagery), and mobile phone call detail records (CDR) - for modeling 15 routine health programmatic outputs in Malawi, and compared their utility to traditional geospatial interpolation methods. We used XGBoost models on data from 552 health catchment areas (January 2021-May 2023), assessing performance with R2, and using an 80/20 training and test data split with 5-fold cross-validation used in training. While predictive performance was mixed, the embedding-based approaches improved upon baseline geostatistical methods in 13 of 15 (87%) indicators tested. A Multi-GeoFM model integrating all three embedding sources produced the most robust predictions, achieving average 5-fold cross validated R2 values for indicators like population density (0.63), new HIV cases (0.57), and child vaccinations (0.47) and test set R2 of 0.64, 0.68, and 0.55, respectively. Prediction was poor for prediction targets with low primary data availability, such as TB and malnutrition cases. These results demonstrate that GeoFM embeddings imbue a modest predictive improvement for select health and demographic outcomes in an LMIC context. We conclude that the integration of multiple GeoFM sources is an efficient and valuable tool for supplementing and strengthening constrained routine health information systems.
General Geospatial Inference with a Population Dynamics Foundation Model
Nov 13, 2024



Supporting the health and well-being of dynamic populations around the world requires governmental agencies, organizations and researchers to understand and reason over complex relationships between human behavior and local contexts in order to identify high-risk groups and strategically allocate limited resources. Traditional approaches to these classes of problems often entail developing manually curated, task-specific features and models to represent human behavior and the natural and built environment, which can be challenging to adapt to new, or even, related tasks. To address this, we introduce a Population Dynamics Foundation Model (PDFM) that aims to capture the relationships between diverse data modalities and is applicable to a broad range of geospatial tasks. We first construct a geo-indexed dataset for postal codes and counties across the United States, capturing rich aggregated information on human behavior from maps, busyness, and aggregated search trends, and environmental factors such as weather and air quality. We then model this data and the complex relationships between locations using a graph neural network, producing embeddings that can be adapted to a wide range of downstream tasks using relatively simple models. We evaluate the effectiveness of our approach by benchmarking it on 27 downstream tasks spanning three distinct domains: health indicators, socioeconomic factors, and environmental measurements. The approach achieves state-of-the-art performance on all 27 geospatial interpolation tasks, and on 25 out of the 27 extrapolation and super-resolution tasks. We combined the PDFM with a state-of-the-art forecasting foundation model, TimesFM, to predict unemployment and poverty, achieving performance that surpasses fully supervised forecasting. The full set of embeddings and sample code are publicly available for researchers.
Community search signatures as foundation features for human-centered geospatial modeling
Oct 30, 2024



Aggregated relative search frequencies offer a unique composite signal reflecting people's habits, concerns, interests, intents, and general information needs, which are not found in other readily available datasets. Temporal search trends have been successfully used in time series modeling across a variety of domains such as infectious diseases, unemployment rates, and retail sales. However, most existing applications require curating specialized datasets of individual keywords, queries, or query clusters, and the search data need to be temporally aligned with the outcome variable of interest. We propose a novel approach for generating an aggregated and anonymized representation of search interest as foundation features at the community level for geospatial modeling. We benchmark these features using spatial datasets across multiple domains. In zip codes with a population greater than 3000 that cover over 95% of the contiguous US population, our models for predicting missing values in a 20% set of holdout counties achieve an average $R^2$ score of 0.74 across 21 health variables, and 0.80 across 6 demographic and environmental variables. Our results demonstrate that these search features can be used for spatial predictions without strict temporal alignment, and that the resulting models outperform spatial interpolation and state of the art methods using satellite imagery features.
Dense Feature Memory Augmented Transformers for COVID-19 Vaccination Search Classification
Dec 16, 2022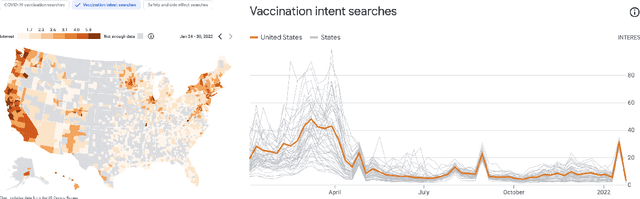
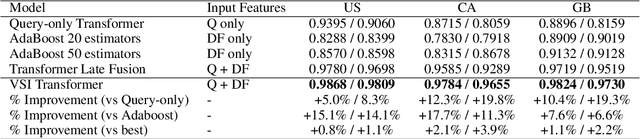
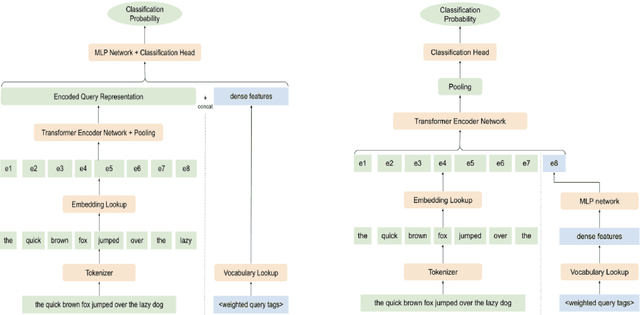
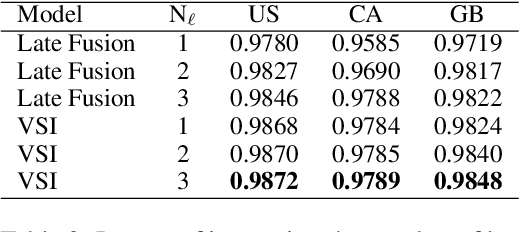
With the devastating outbreak of COVID-19, vaccines are one of the crucial lines of defense against mass infection in this global pandemic. Given the protection they provide, vaccines are becoming mandatory in certain social and professional settings. This paper presents a classification model for detecting COVID-19 vaccination related search queries, a machine learning model that is used to generate search insights for COVID-19 vaccinations. The proposed method combines and leverages advancements from modern state-of-the-art (SOTA) natural language understanding (NLU) techniques such as pretrained Transformers with traditional dense features. We propose a novel approach of considering dense features as memory tokens that the model can attend to. We show that this new modeling approach enables a significant improvement to the Vaccine Search Insights (VSI) task, improving a strong well-established gradient-boosting baseline by relative +15% improvement in F1 score and +14% in precision.
Scalable and accurate deep learning for electronic health records
May 11, 2018
Predictive modeling with electronic health record (EHR) data is anticipated to drive personalized medicine and improve healthcare quality. Constructing predictive statistical models typically requires extraction of curated predictor variables from normalized EHR data, a labor-intensive process that discards the vast majority of information in each patient's record. We propose a representation of patients' entire, raw EHR records based on the Fast Healthcare Interoperability Resources (FHIR) format. We demonstrate that deep learning methods using this representation are capable of accurately predicting multiple medical events from multiple centers without site-specific data harmonization. We validated our approach using de-identified EHR data from two U.S. academic medical centers with 216,221 adult patients hospitalized for at least 24 hours. In the sequential format we propose, this volume of EHR data unrolled into a total of 46,864,534,945 data points, including clinical notes. Deep learning models achieved high accuracy for tasks such as predicting in-hospital mortality (AUROC across sites 0.93-0.94), 30-day unplanned readmission (AUROC 0.75-0.76), prolonged length of stay (AUROC 0.85-0.86), and all of a patient's final discharge diagnoses (frequency-weighted AUROC 0.90). These models outperformed state-of-the-art traditional predictive models in all cases. We also present a case-study of a neural-network attribution system, which illustrates how clinicians can gain some transparency into the predictions. We believe that this approach can be used to create accurate and scalable predictions for a variety of clinical scenarios, complete with explanations that directly highlight evidence in the patient's chart.
* Published version from https://www.nature.com/articles/s41746-018-0029-1