 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Intrinsic Reasoning over Dense Geospatial Embeddings with DFR-Gemma
Apr 08, 2026Representation learning for geospatial and spatio-temporal data plays a critical role in enabling general-purpose geospatial intelligence. Recent geospatial foundation models, such as the Population Dynamics Foundation Model (PDFM), encode complex population and mobility dynamics into compact embeddings. However, their integration with Large Language Models (LLMs) remains limited. Existing approaches to LLM integration treat these embeddings as retrieval indices or convert them into textual descriptions for reasoning, introducing redundancy, token inefficiency, and numerical inaccuracies. We propose Direct Feature Reasoning-Gemma (DFR-Gemma), a novel framework that enables LLMs to reason directly over dense geospatial embeddings. DFR aligns high-dimensional embeddings with the latent space of an LLM via a lightweight projector, allowing embeddings to be injected as semantic tokens alongside natural language instructions. This design eliminates the need for intermediate textual representations and enables intrinsic reasoning over spatial features. To evaluate this paradigm, we introduce a multi-task geospatial benchmark that pairs embeddings with diverse question-answer tasks, including feature querying, comparison, and semantic description. Experimental results show that DFR allows LLMs to decode latent spatial patterns and perform accurate zero-shot reasoning across tasks, while significantly improving efficiency compared to text-based baselines. Our results demonstrate that treating embeddings as primary data inputs, provides a more direct, efficient, and scalable approach to multimodal geospatial intelligence.
Application and Validation of Geospatial Foundation Model Data for the Prediction of Health Facility Programmatic Outputs -- A Case Study in Malawi
Oct 29, 2025



The reliability of routine health data in low and middle-income countries (LMICs) is often constrained by reporting delays and incomplete coverage, necessitating the exploration of novel data sources and analytics. Geospatial Foundation Models (GeoFMs) offer a promising avenue by synthesizing diverse spatial, temporal, and behavioral data into mathematical embeddings that can be efficiently used for downstream prediction tasks. This study evaluated the predictive performance of three GeoFM embedding sources - Google Population Dynamics Foundation Model (PDFM), Google AlphaEarth (derived from satellite imagery), and mobile phone call detail records (CDR) - for modeling 15 routine health programmatic outputs in Malawi, and compared their utility to traditional geospatial interpolation methods. We used XGBoost models on data from 552 health catchment areas (January 2021-May 2023), assessing performance with R2, and using an 80/20 training and test data split with 5-fold cross-validation used in training. While predictive performance was mixed, the embedding-based approaches improved upon baseline geostatistical methods in 13 of 15 (87%) indicators tested. A Multi-GeoFM model integrating all three embedding sources produced the most robust predictions, achieving average 5-fold cross validated R2 values for indicators like population density (0.63), new HIV cases (0.57), and child vaccinations (0.47) and test set R2 of 0.64, 0.68, and 0.55, respectively. Prediction was poor for prediction targets with low primary data availability, such as TB and malnutrition cases. These results demonstrate that GeoFM embeddings imbue a modest predictive improvement for select health and demographic outcomes in an LMIC context. We conclude that the integration of multiple GeoFM sources is an efficient and valuable tool for supplementing and strengthening constrained routine health information systems.
General Geospatial Inference with a Population Dynamics Foundation Model
Nov 13, 2024



Supporting the health and well-being of dynamic populations around the world requires governmental agencies, organizations and researchers to understand and reason over complex relationships between human behavior and local contexts in order to identify high-risk groups and strategically allocate limited resources. Traditional approaches to these classes of problems often entail developing manually curated, task-specific features and models to represent human behavior and the natural and built environment, which can be challenging to adapt to new, or even, related tasks. To address this, we introduce a Population Dynamics Foundation Model (PDFM) that aims to capture the relationships between diverse data modalities and is applicable to a broad range of geospatial tasks. We first construct a geo-indexed dataset for postal codes and counties across the United States, capturing rich aggregated information on human behavior from maps, busyness, and aggregated search trends, and environmental factors such as weather and air quality. We then model this data and the complex relationships between locations using a graph neural network, producing embeddings that can be adapted to a wide range of downstream tasks using relatively simple models. We evaluate the effectiveness of our approach by benchmarking it on 27 downstream tasks spanning three distinct domains: health indicators, socioeconomic factors, and environmental measurements. The approach achieves state-of-the-art performance on all 27 geospatial interpolation tasks, and on 25 out of the 27 extrapolation and super-resolution tasks. We combined the PDFM with a state-of-the-art forecasting foundation model, TimesFM, to predict unemployment and poverty, achieving performance that surpasses fully supervised forecasting. The full set of embeddings and sample code are publicly available for researchers.
Community search signatures as foundation features for human-centered geospatial modeling
Oct 30, 2024



Aggregated relative search frequencies offer a unique composite signal reflecting people's habits, concerns, interests, intents, and general information needs, which are not found in other readily available datasets. Temporal search trends have been successfully used in time series modeling across a variety of domains such as infectious diseases, unemployment rates, and retail sales. However, most existing applications require curating specialized datasets of individual keywords, queries, or query clusters, and the search data need to be temporally aligned with the outcome variable of interest. We propose a novel approach for generating an aggregated and anonymized representation of search interest as foundation features at the community level for geospatial modeling. We benchmark these features using spatial datasets across multiple domains. In zip codes with a population greater than 3000 that cover over 95% of the contiguous US population, our models for predicting missing values in a 20% set of holdout counties achieve an average $R^2$ score of 0.74 across 21 health variables, and 0.80 across 6 demographic and environmental variables. Our results demonstrate that these search features can be used for spatial predictions without strict temporal alignment, and that the resulting models outperform spatial interpolation and state of the art methods using satellite imagery features.
EEV Dataset: Predicting Expressions Evoked by Diverse Videos
Jan 15, 2020
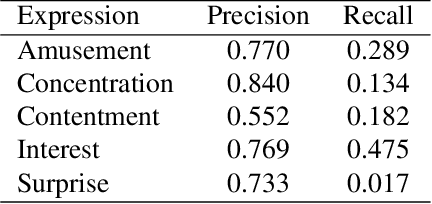
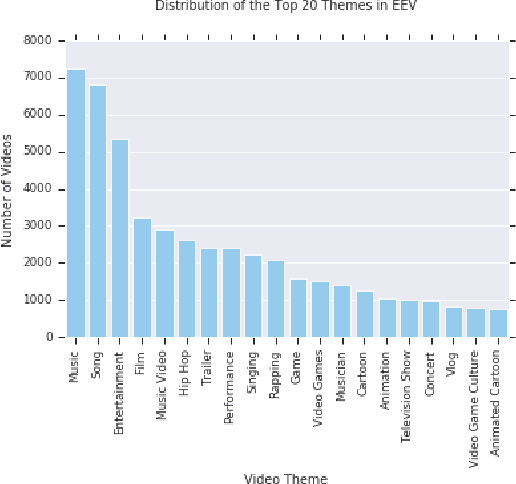
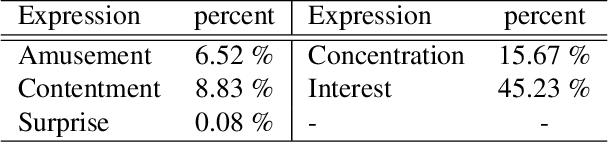
When we watch videos, the visual and auditory information we experience can evoke a range of affective responses. The ability to automatically predict evoked affect from videos can help recommendation systems and social machines better interact with their users. Here, we introduce the Evoked Expressions in Videos (EEV) dataset, a large-scale dataset for studying viewer responses to videos based on their facial expressions. The dataset consists of a total of 4.8 million annotations of viewer facial reactions to 18,541 videos. We use a publicly available video corpus to obtain a diverse set of video content. The training split is fully machine-annotated, while the validation and test splits have both human and machine annotations. We verify the performance of our machine annotations with human raters to have an average precision of 73.3%. We establish baseline performance on the EEV dataset using an existing multimodal recurrent model. Our results show that affective information can be learned from EEV, but with a MAP of 20.32%, there is potential for improvement. This gap motivates the need for new approaches for understanding affective content. Our transfer learning experiments show an improvement in performance on the LIRIS-ACCEDE video dataset when pre-trained on EEV. We hope that the size and diversity of the EEV dataset will encourage further explorations in video understanding and affective computing.
GLA in MediaEval 2018 Emotional Impact of Movies Task
Nov 27, 2019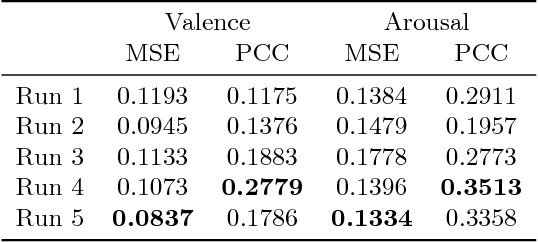
The visual and audio information from movies can evoke a variety of emotions in viewers. Towards a better understanding of viewer impact, we present our methods for the MediaEval 2018 Emotional Impact of Movies Task to predict the expected valence and arousal continuously in movies. This task, using the LIRIS-ACCEDE dataset, enables researchers to compare different approaches for predicting viewer impact from movies. Our approach leverages image, audio, and face based features computed using pre-trained neural networks. These features were computed over time and modeled using a gated recurrent unit (GRU) based network followed by a mixture of experts model to compute multiclass predictions. We smoothed these predictions using a Butterworth filter for our final result. Our method enabled us to achieve top performance in three evaluation metrics in the MediaEval 2018 task.
Agriculture Commodity Arrival Prediction using Remote Sensing Data: Insights and Beyond
Jun 14, 2019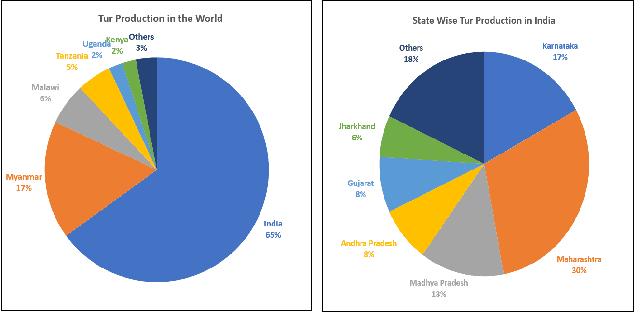
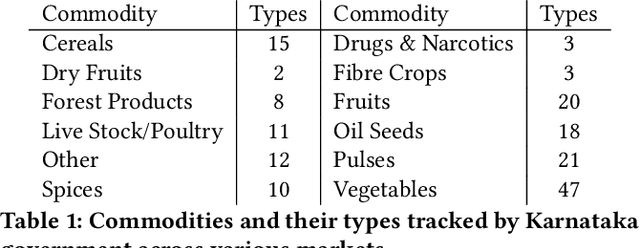
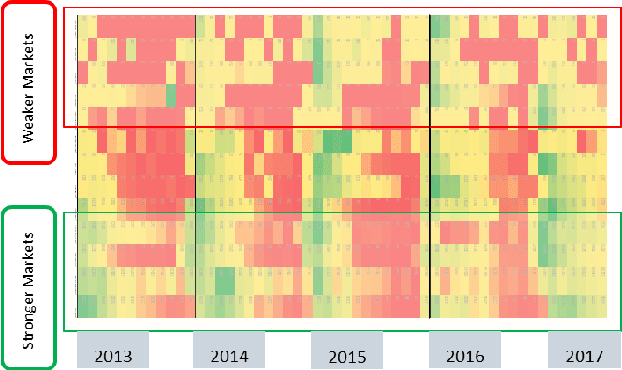
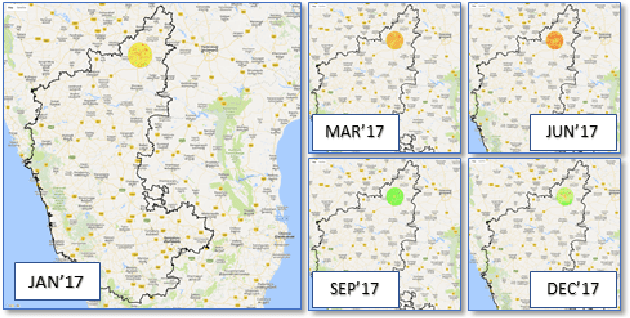
In developing countries like India agriculture plays an extremely important role in the lives of the population. In India, around 80\% of the population depend on agriculture or its by-products as the primary means for employment. Given large population dependency on agriculture, it becomes extremely important for the government to estimate market factors in advance and prepare for any deviation from those estimates. Commodity arrivals to market is an extremely important factor which is captured at district level throughout the country. Historical data and short-term prediction of important variables such as arrivals, prices, crop quality etc. for commodities are used by the government to take proactive steps and decide various policy measures. In this paper, we present a framework to work with short timeseries in conjunction with remote sensing data to predict future commodity arrivals. We deal with extremely high dimensional data which exceed the observation sizes by multiple orders of magnitude. We use cascaded layers of dimensionality reduction techniques combined with regularized regression models for prediction. We present results to predict arrivals to major markets and state wide prices for `Tur' (red gram) crop in Karnataka, India. Our model consistently beats popular ML techniques on many instances. Our model is scalable, time efficient and can be generalized to many other crops and regions. We draw multiple insights from the regression parameters, some of which are important aspects to consider when predicting more complex quantities such as prices in the future. We also combine the insights to generate important recommendations for different government organizations.
Weakly Supervised Action Localization by Sparse Temporal Pooling Network
Apr 03, 2018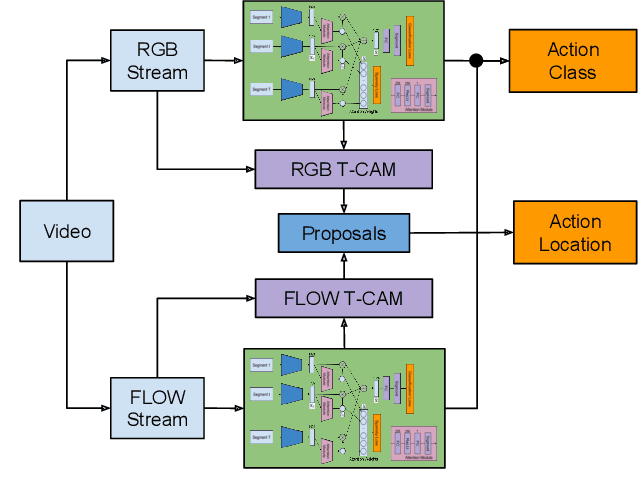
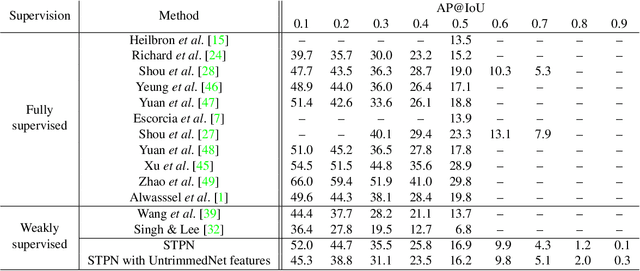
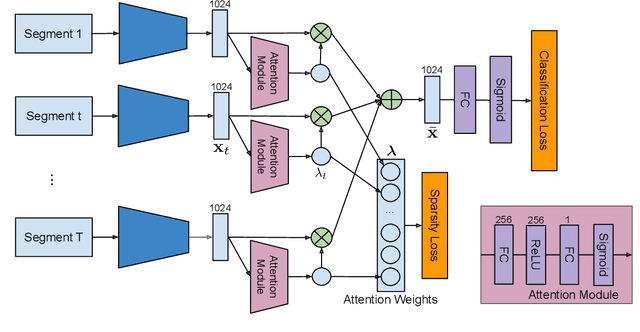
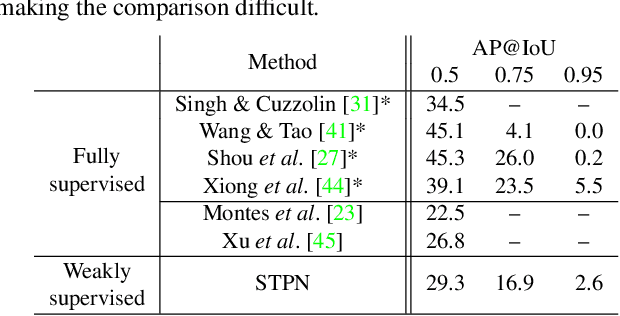
We propose a weakly supervised temporal action localization algorithm on untrimmed videos using convolutional neural networks. Our algorithm learns from video-level class labels and predicts temporal intervals of human actions with no requirement of temporal localization annotations. We design our network to identify a sparse subset of key segments associated with target actions in a video using an attention module and fuse the key segments through adaptive temporal pooling. Our loss function is comprised of two terms that minimize the video-level action classification error and enforce the sparsity of the segment selection. At inference time, we extract and score temporal proposals using temporal class activations and class-agnostic attentions to estimate the time intervals that correspond to target actions. The proposed algorithm attains state-of-the-art results on the THUMOS14 dataset and outstanding performance on ActivityNet1.3 even with its weak supervision.