 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupMemBench: Benchmarking LLM Agent Memory in Multi-Party Conversations
May 14, 2026Large Language Model (LLM) agents increasingly serve as personal assistants and workplace collaborators, where their utility depends on memory systems that extract, retrieve, and apply information across long-running conversations. However, both existing memory systems and benchmarks are built around the dyadic, single-user setup, even though real deployments routinely span groups and channels with multiple users interacting with the agent and with each other. This mismatch leaves three properties of group memory unmeasured: (i) group dynamics that go beyond concatenated one-on-one chats, (ii) speaker-grounded belief tracking, where the per-user memory modeling is needed, and (iii) audience-adapted language, where Theory-of-Mind shifts produce role-specific vocabulary. We introduce GroupMemBench, a benchmark that exposes all three. A graph-grounded synthesis pipeline produces multi-party conversations with controllable reply structure and conditions each message on per-user personas and target audiences. An adversarial query pipeline then binds every question to a specific asker across six categories, spanning multi-hop reasoning, knowledge update, term ambiguity, user-implicit reasoning, temporal reasoning, and abstention, and iteratively searches challenging, realistic queries that reflect comprehensive memory capability. Benchmarking leading memory systems exposes a sharp collapse: the strongest one reaches only 46.0% average accuracy, with knowledge update at 27.1% and term ambiguity at 37.7%, while a simple BM25 baseline matches or exceeds most agent memory systems. This indicates current memory ingestion erases the structural and lexical features group memory depends on, leaving multi-user memory far from solved.
Dense Feature Memory Augmented Transformers for COVID-19 Vaccination Search Classification
Dec 16, 2022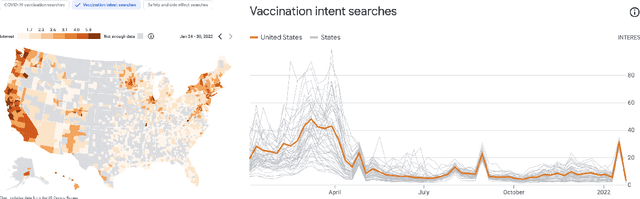
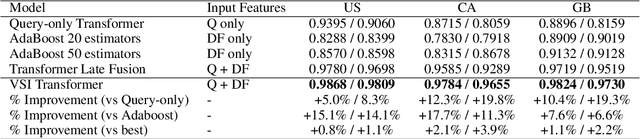
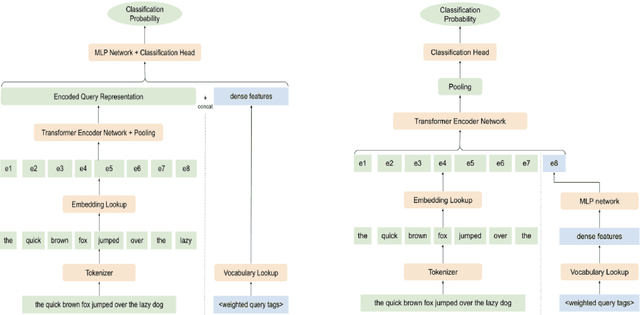
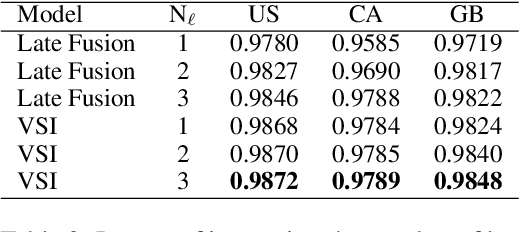
With the devastating outbreak of COVID-19, vaccines are one of the crucial lines of defense against mass infection in this global pandemic. Given the protection they provide, vaccines are becoming mandatory in certain social and professional settings. This paper presents a classification model for detecting COVID-19 vaccination related search queries, a machine learning model that is used to generate search insights for COVID-19 vaccinations. The proposed method combines and leverages advancements from modern state-of-the-art (SOTA) natural language understanding (NLU) techniques such as pretrained Transformers with traditional dense features. We propose a novel approach of considering dense features as memory tokens that the model can attend to. We show that this new modeling approach enables a significant improvement to the Vaccine Search Insights (VSI) task, improving a strong well-established gradient-boosting baseline by relative +15% improvement in F1 score and +14% in precision.
Machine-learned epidemiology: real-time detection of foodborne illness at scale
Dec 05, 2018
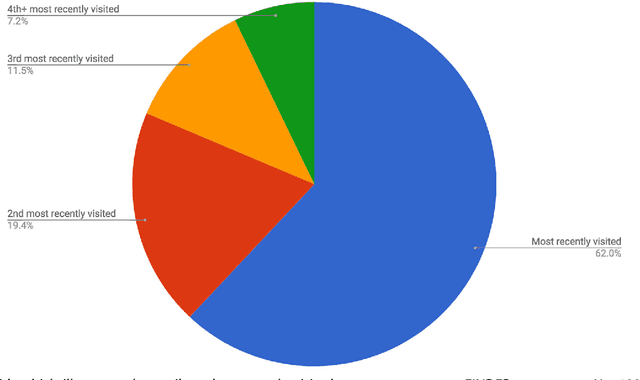

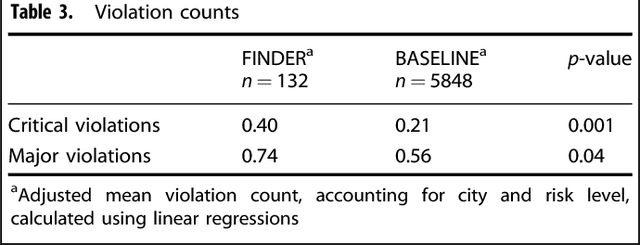
Machine learning has become an increasingly powerful tool for solving complex problems, and its application in public health has been underutilized. The objective of this study is to test the efficacy of a machine-learned model of foodborne illness detection in a real-world setting. To this end, we built FINDER, a machine-learned model for real-time detection of foodborne illness using anonymous and aggregated web search and location data. We computed the fraction of people who visited a particular restaurant and later searched for terms indicative of food poisoning to identify potentially unsafe restaurants. We used this information to focus restaurant inspections in two cities and demonstrated that FINDER improves the accuracy of health inspections; restaurants identified by FINDER are 3.1 times as likely to be deemed unsafe during the inspection as restaurants identified by existing methods. Additionally, FINDER enables us to ascertain previously intractable epidemiological information, for example, in 38% of cases the restaurant potentially causing food poisoning was not the last one visited, which may explain the lower precision of complaint-based inspections. We found that FINDER is able to reliably identify restaurants that have an active lapse in food safety, allowing for implementation of corrective actions that would prevent the potential spread of foodborne illness.
A Review of Relational Machine Learning for Knowledge Graphs
Sep 28, 2015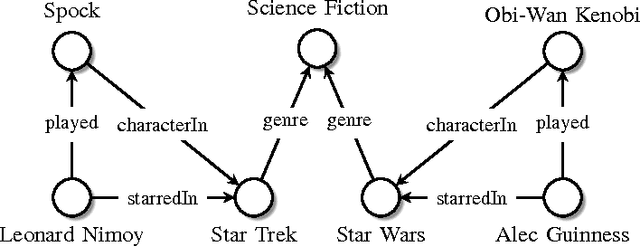
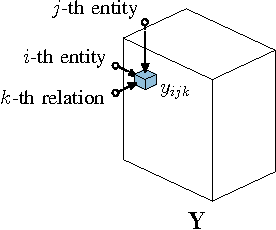
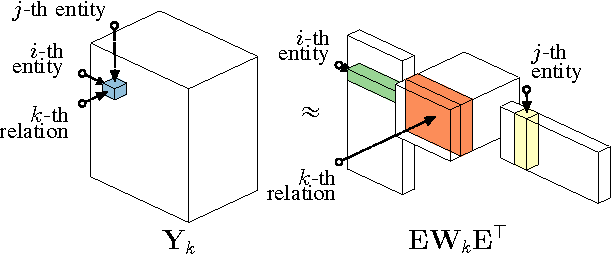

Relational machine learning studies methods for the statistical analysis of relational, or graph-structured, data. In this paper, we provide a review of how such statistical models can be "trained" on large knowledge graphs, and then used to predict new facts about the world (which is equivalent to predicting new edges in the graph). In particular, we discuss two fundamentally different kinds of statistical relational models, both of which can scale to massive datasets. The first is based on latent feature models such as tensor factorization and multiway neural networks. The second is based on mining observable patterns in the graph. We also show how to combine these latent and observable models to get improved modeling power at decreased computational cost. Finally, we discuss how such statistical models of graphs can be combined with text-based information extraction methods for automatically constructing knowledge graphs from the Web. To this end, we also discuss Google's Knowledge Vault project as an example of such combination.
Quizz: Targeted crowdsourcing with a billion (potential) users
Jun 02, 2015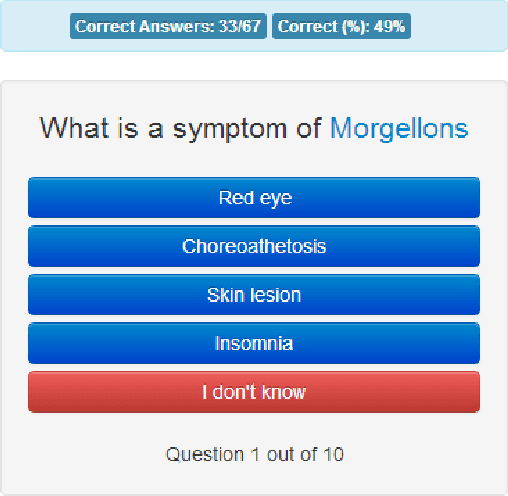
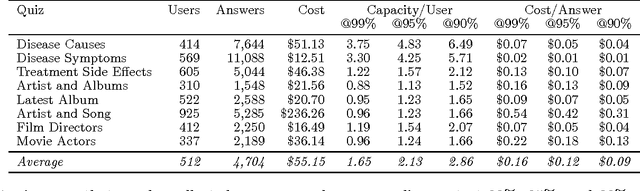
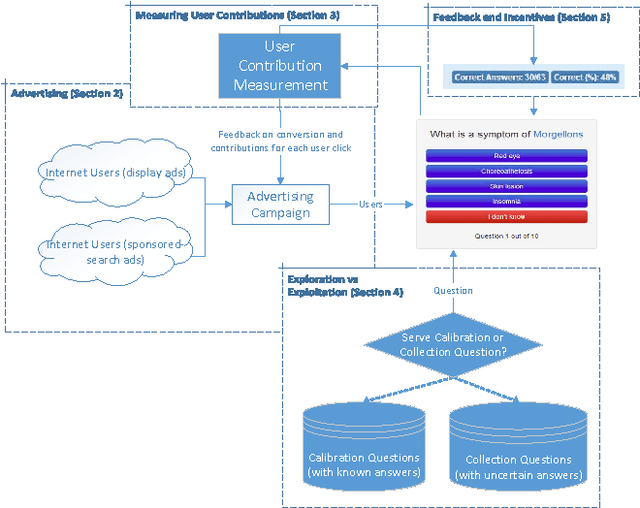

We describe Quizz, a gamified crowdsourcing system that simultaneously assesses the knowledge of users and acquires new knowledge from them. Quizz operates by asking users to complete short quizzes on specific topics; as a user answers the quiz questions, Quizz estimates the user's competence. To acquire new knowledge, Quizz also incorporates questions for which we do not have a known answer; the answers given by competent users provide useful signals for selecting the correct answers for these questions. Quizz actively tries to identify knowledgeable users on the Internet by running advertising campaigns, effectively leveraging the targeting capabilities of existing, publicly available, ad placement services. Quizz quantifies the contributions of the users using information theory and sends feedback to the advertisingsystem about each user. The feedback allows the ad targeting mechanism to further optimize ad placement. Our experiments, which involve over ten thousand users, confirm that we can crowdsource knowledge curation for niche and specialized topics, as the advertising network can automatically identify users with the desired expertise and interest in the given topic. We present controlled experiments that examine the effect of various incentive mechanisms, highlighting the need for having short-term rewards as goals, which incentivize the users to contribute. Finally, our cost-quality analysis indicates that the cost of our approach is below that of hiring workers through paid-crowdsourcing platforms, while offering the additional advantage of giving access to billions of potential users all over the planet, and being able to reach users with specialized expertise that is not typically available through existing labor marketplaces.
Wikipedia-based Semantic Interpretation for Natural Language Processing
Jan 15, 2014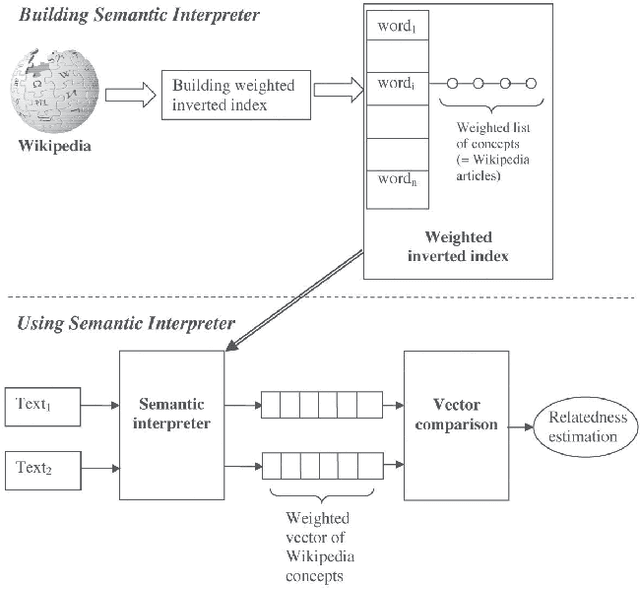
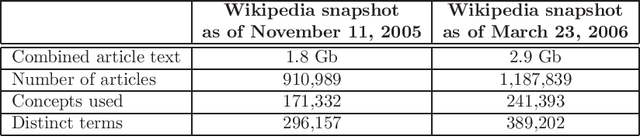
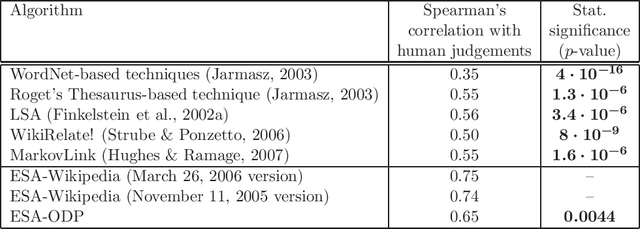
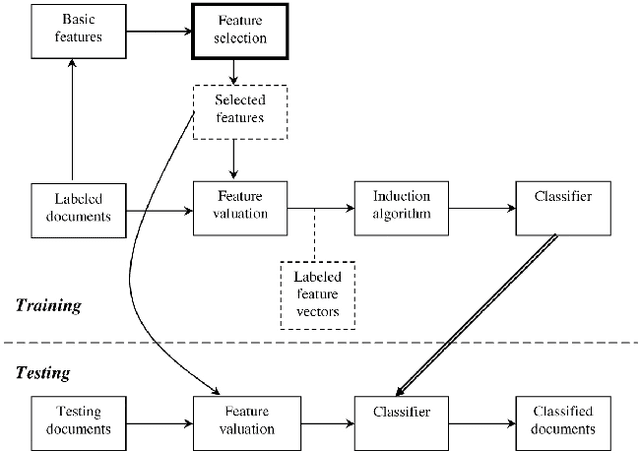
Adequate representation of natural language semantics requires access to vast amounts of common sense and domain-specific world knowledge. Prior work in the field was based on purely statistical techniques that did not make use of background knowledge, on limited lexicographic knowledge bases such as WordNet, or on huge manual efforts such as the CYC project. Here we propose a novel method, called Explicit Semantic Analysis (ESA), for fine-grained semantic interpretation of unrestricted natural language texts. Our method represents meaning in a high-dimensional space of concepts derived from Wikipedia, the largest encyclopedia in existence. We explicitly represent the meaning of any text in terms of Wikipedia-based concepts. We evaluate the effectiveness of our method on text categorization and on computing the degree of semantic relatedness between fragments of natural language text. Using ESA results in significant improvements over the previous state of the art in both tasks. Importantly, due to the use of natural concepts, the ESA model is easy to explain to human users.
Amalia -- A Unified Platform for Parsing and Generation
Sep 24, 1997

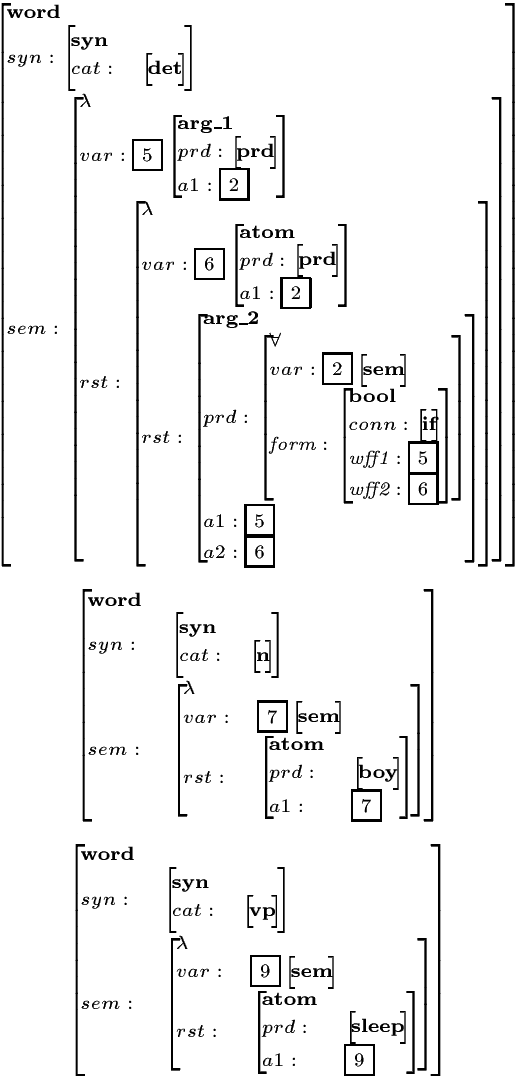
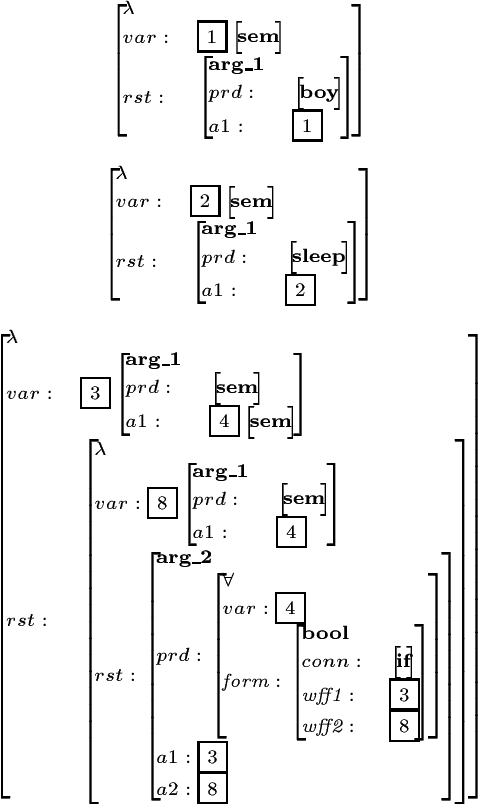
Contemporary linguistic theories (in particular, HPSG) are declarative in nature: they specify constraints on permissible structures, not how such structures are to be computed. Grammars designed under such theories are, therefore, suitable for both parsing and generation. However, practical implementations of such theories don't usually support bidirectional processing of grammars. We present a grammar development system that includes a compiler of grammars (for parsing and generation) to abstract machine instructions, and an interpreter for the abstract machine language. The generation compiler inverts input grammars (designed for parsing) to a form more suitable for generation. The compiled grammars are then executed by the interpreter using one control strategy, regardless of whether the grammar is the original or the inverted version. We thus obtain a unified, efficient platform for developing reversible grammars.
* 8 pages postscript