 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Music Annotation and Retrieval: Learning to Rank in Joint Semantic Spaces
Paper and Code
May 26, 2011
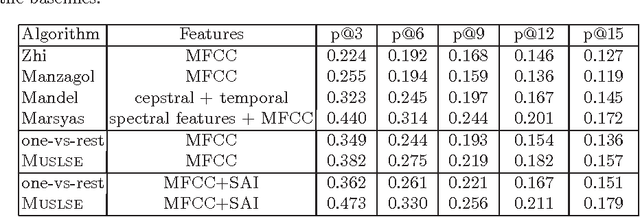
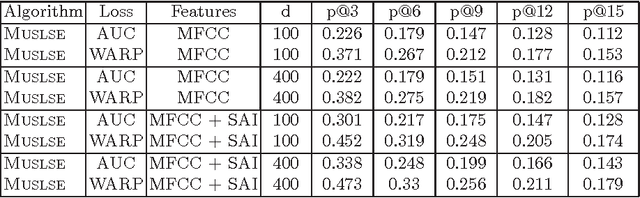

Music prediction tasks range from predicting tags given a song or clip of audio, predicting the name of the artist, or predicting related songs given a song, clip, artist name or tag. That is, we are interested in every semantic relationship between the different musical concepts in our database. In realistically sized databases, the number of songs is measured in the hundreds of thousands or more, and the number of artists in the tens of thousands or more, providing a considerable challenge to standard machine learning techniques. In this work, we propose a method that scales to such datasets which attempts to capture the semantic similarities between the database items by modeling audio, artist names, and tags in a single low-dimensional semantic space. This choice of space is learnt by optimizing the set of prediction tasks of interest jointly using multi-task learning. Our method both outperforms baseline methods and, in comparison to them, is faster and consumes less memory. We then demonstrate how our method learns an interpretable model, where the semantic space captures well the similarities of interest.