 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Guard: Parameter-Efficient Guardrail Adaptation for Content Moderation of Large Language Models
Jul 03, 2024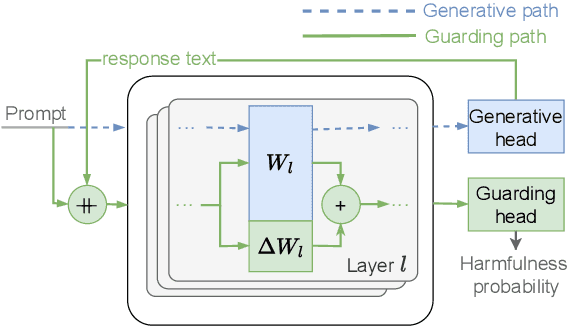
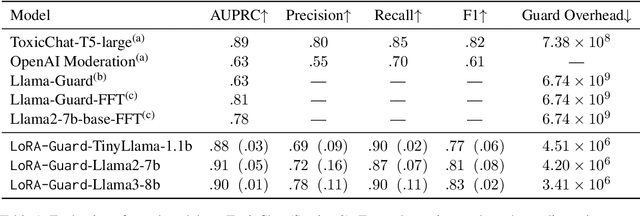
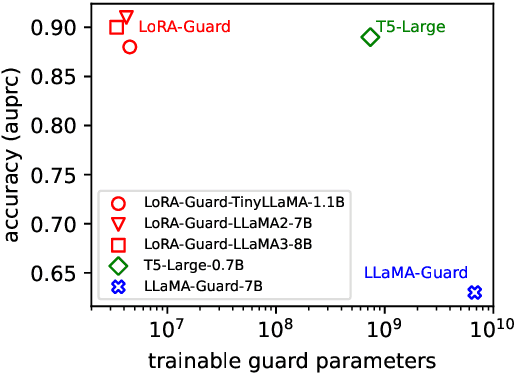
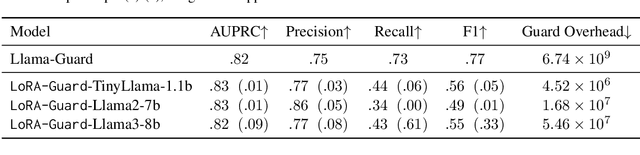
Guardrails have emerged as an alternative to safety alignment for content moderation of large language models (LLMs). Existing model-based guardrails have not been designed for resource-constrained computational portable devices, such as mobile phones, more and more of which are running LLM-based applications locally. We introduce LoRA-Guard, a parameter-efficient guardrail adaptation method that relies on knowledge sharing between LLMs and guardrail models. LoRA-Guard extracts language features from the LLMs and adapts them for the content moderation task using low-rank adapters, while a dual-path design prevents any performance degradation on the generative task. We show that LoRA-Guard outperforms existing approaches with 100-1000x lower parameter overhead while maintaining accuracy, enabling on-device content moderation.
On Redundancy and Diversity in Cell-based Neural Architecture Search
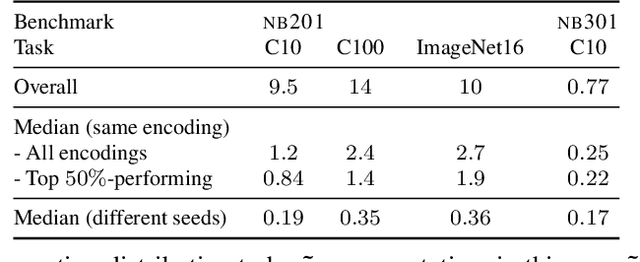
Mar 16, 2022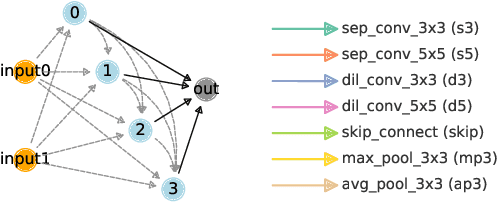
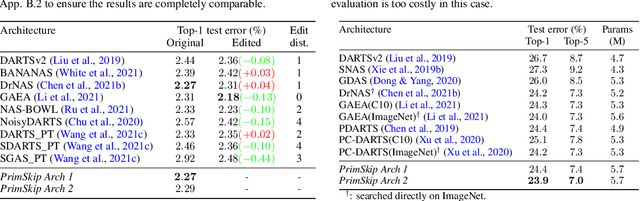
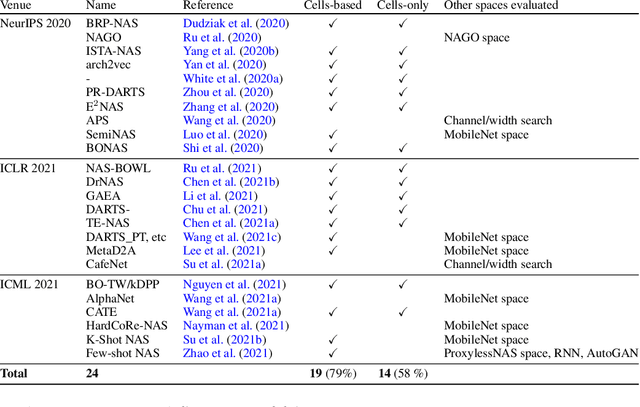

Searching for the architecture cells is a dominant paradigm in NAS. However, little attention has been devoted to the analysis of the cell-based search spaces even though it is highly important for the continual development of NAS. In this work, we conduct an empirical post-hoc analysis of architectures from the popular cell-based search spaces and find that the existing search spaces contain a high degree of redundancy: the architecture performance is minimally sensitive to changes at large parts of the cells, and universally adopted designs, like the explicit search for a reduction cell, significantly increase the complexities but have very limited impact on the performance. Across architectures found by a diverse set of search strategies, we consistently find that the parts of the cells that do matter for architecture performance often follow similar and simple patterns. By explicitly constraining cells to include these patterns, randomly sampled architectures can match or even outperform the state of the art. These findings cast doubts into our ability to discover truly novel architectures in the existing cell-based search spaces, and inspire our suggestions for improvement to guide future NAS research. Code is available at https://github.com/xingchenwan/cell-based-NAS-analysis.
Approximate Neural Architecture Search via Operation Distribution Learning
Nov 08, 2021
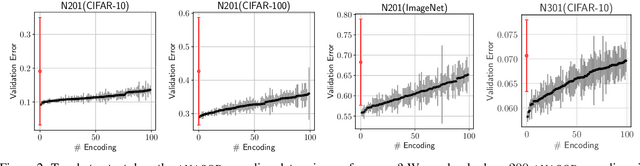
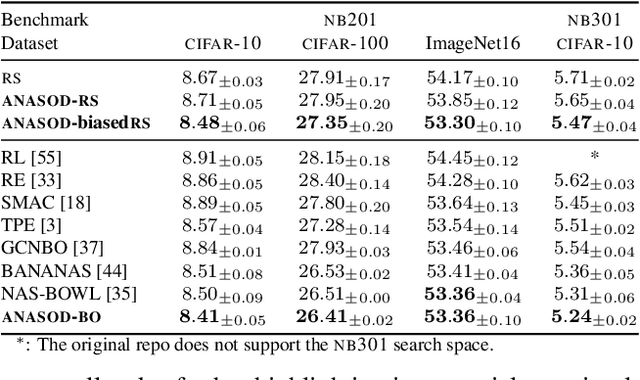
The standard paradigm in Neural Architecture Search (NAS) is to search for a fully deterministic architecture with specific operations and connections. In this work, we instead propose to search for the optimal operation distribution, thus providing a stochastic and approximate solution, which can be used to sample architectures of arbitrary length. We propose and show, that given an architectural cell, its performance largely depends on the ratio of used operations, rather than any specific connection pattern in typical search spaces; that is, small changes in the ordering of the operations are often irrelevant. This intuition is orthogonal to any specific search strategy and can be applied to a diverse set of NAS algorithms. Through extensive validation on 4 data-sets and 4 NAS techniques (Bayesian optimisation, differentiable search, local search and random search), we show that the operation distribution (1) holds enough discriminating power to reliably identify a solution and (2) is significantly easier to optimise than traditional encodings, leading to large speed-ups at little to no cost in performance. Indeed, this simple intuition significantly reduces the cost of current approaches and potentially enable NAS to be used in a broader range of applications.
NAS evaluation is frustratingly hard
Feb 13, 2020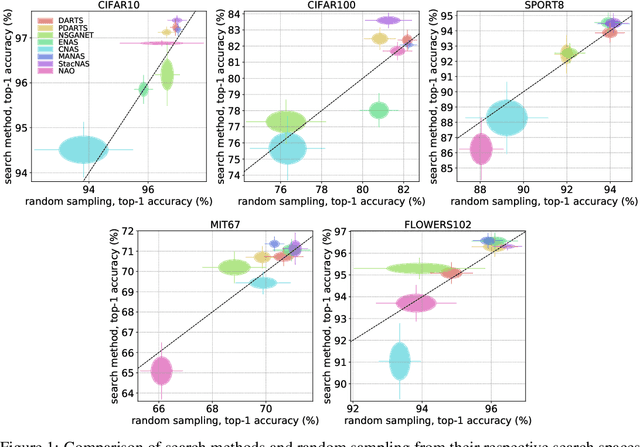
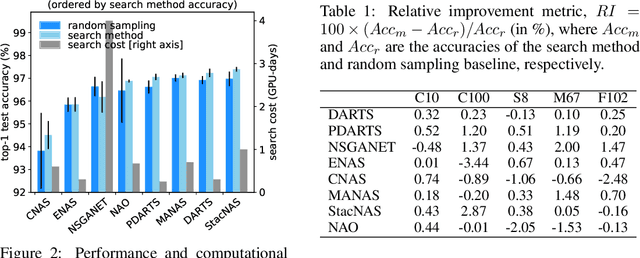
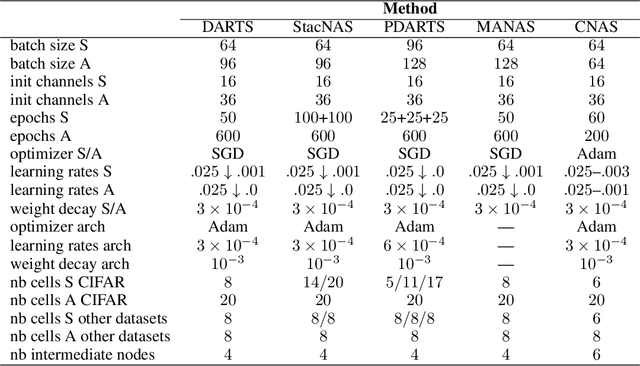
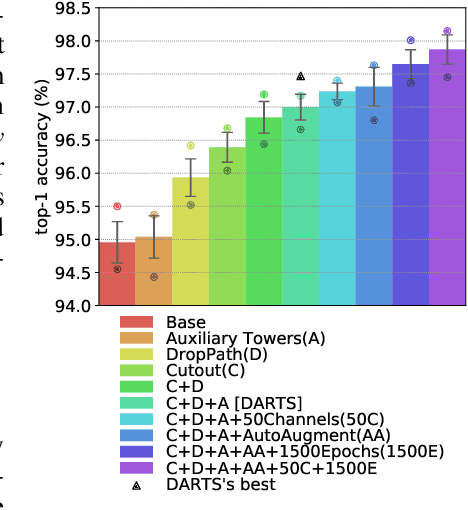
Neural Architecture Search (NAS) is an exciting new field which promises to be as much as a game-changer as Convolutional Neural Networks were in 2012. Despite many great works leading to substantial improvements on a variety of tasks, comparison between different methods is still very much an open issue. While most algorithms are tested on the same datasets, there is no shared experimental protocol followed by all. As such, and due to the under-use of ablation studies, there is a lack of clarity regarding why certain methods are more effective than others. Our first contribution is a benchmark of $8$ NAS methods on $5$ datasets. To overcome the hurdle of comparing methods with different search spaces, we propose using a method's relative improvement over the randomly sampled average architecture, which effectively removes advantages arising from expertly engineered search spaces or training protocols. Surprisingly, we find that many NAS techniques struggle to significantly beat the average architecture baseline. We perform further experiments with the commonly used DARTS search space in order to understand the contribution of each component in the NAS pipeline. These experiments highlight that: (i) the use of tricks in the evaluation protocol has a predominant impact on the reported performance of architectures; (ii) the cell-based search space has a very narrow accuracy range, such that the seed has a considerable impact on architecture rankings; (iii) the hand-designed macro-structure (cells) is more important than the searched micro-structure (operations); and (iv) the depth-gap is a real phenomenon, evidenced by the change in rankings between $8$ and $20$ cell architectures. To conclude, we suggest best practices, that we hope will prove useful for the community and help mitigate current NAS pitfalls. The code used is available at https://github.com/antoyang/NAS-Benchmark.
Encrypted accelerated least squares regression
Mar 02, 2017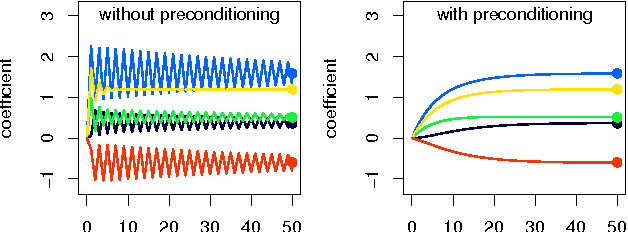

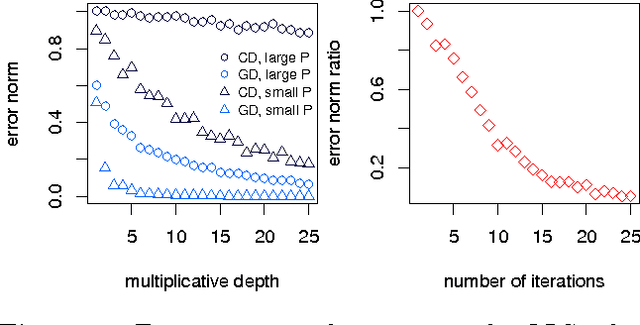
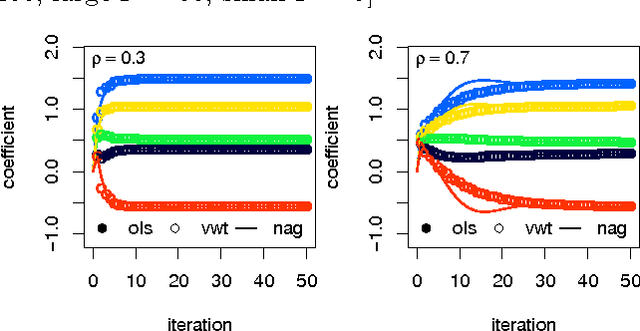
Information that is stored in an encrypted format is, by definition, usually not amenable to statistical analysis or machine learning methods. In this paper we present detailed analysis of coordinate and accelerated gradient descent algorithms which are capable of fitting least squares and penalised ridge regression models, using data encrypted under a fully homomorphic encryption scheme. Gradient descent is shown to dominate in terms of encrypted computational speed, and theoretical results are proven to give parameter bounds which ensure correctness of decryption. The characteristics of encrypted computation are empirically shown to favour a non-standard acceleration technique. This demonstrates the possibility of approximating conventional statistical regression methods using encrypted data without compromising privacy.
Encrypted statistical machine learning: new privacy preserving methods
Aug 27, 2015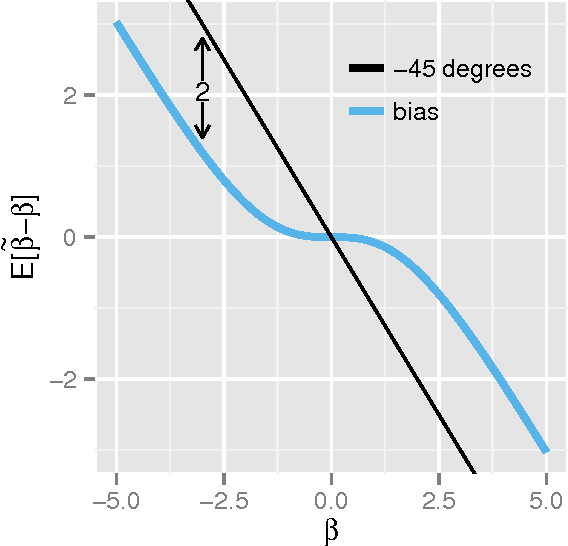
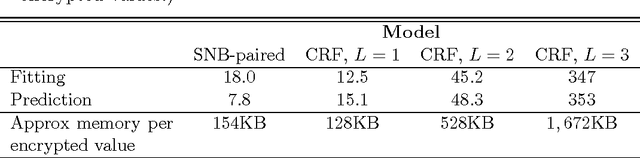
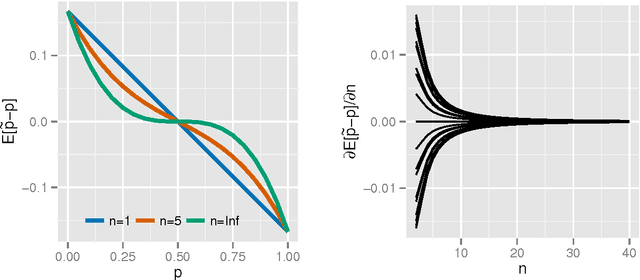
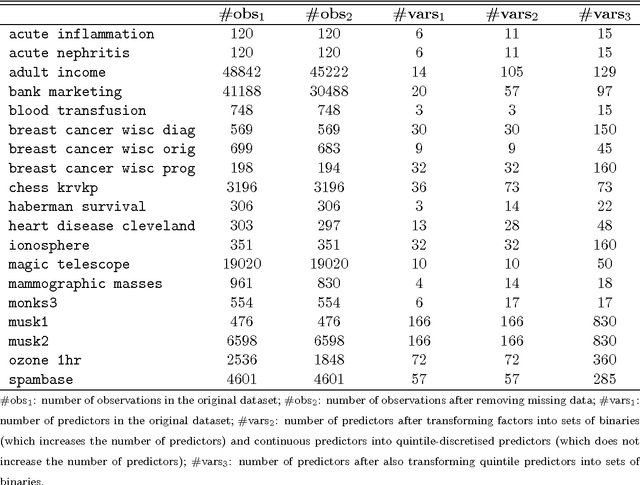
We present two new statistical machine learning methods designed to learn on fully homomorphic encrypted (FHE) data. The introduction of FHE schemes following Gentry (2009) opens up the prospect of privacy preserving statistical machine learning analysis and modelling of encrypted data without compromising security constraints. We propose tailored algorithms for applying extremely random forests, involving a new cryptographic stochastic fraction estimator, and na\"{i}ve Bayes, involving a semi-parametric model for the class decision boundary, and show how they can be used to learn and predict from encrypted data. We demonstrate that these techniques perform competitively on a variety of classification data sets and provide detailed information about the computational practicalities of these and other FHE methods.
A review of homomorphic encryption and software tools for encrypted statistical machine learning
Aug 26, 2015
Recent advances in cryptography promise to enable secure statistical computation on encrypted data, whereby a limited set of operations can be carried out without the need to first decrypt. We review these homomorphic encryption schemes in a manner accessible to statisticians and machine learners, focusing on pertinent limitations inherent in the current state of the art. These limitations restrict the kind of statistics and machine learning algorithms which can be implemented and we review those which have been successfully applied in the literature. Finally, we document a high performance R package implementing a recent homomorphic scheme in a general framework.