 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real-World Evaluation of LLM Medication Safety Reviews in NHS Primary Care
Dec 24, 2025Large language models (LLMs) often match or exceed clinician-level performance on medical benchmarks, yet very few are evaluated on real clinical data or examined beyond headline metrics. We present, to our knowledge, the first evaluation of an LLM-based medication safety review system on real NHS primary care data, with detailed characterisation of key failure behaviours across varying levels of clinical complexity. In a retrospective study using a population-scale EHR spanning 2,125,549 adults in NHS Cheshire and Merseyside, we strategically sampled patients to capture a broad range of clinical complexity and medication safety risk, yielding 277 patients after data-quality exclusions. An expert clinician reviewed these patients and graded system-identified issues and proposed interventions. Our primary LLM system showed strong performance in recognising when a clinical issue is present (sensitivity 100\% [95\% CI 98.2--100], specificity 83.1\% [95\% CI 72.7--90.1]), yet correctly identified all issues and interventions in only 46.9\% [95\% CI 41.1--52.8] of patients. Failure analysis reveals that, in this setting, the dominant failure mechanism is contextual reasoning rather than missing medication knowledge, with five primary patterns: overconfidence in uncertainty, applying standard guidelines without adjusting for patient context, misunderstanding how healthcare is delivered in practice, factual errors, and process blindness. These patterns persisted across patient complexity and demographic strata, and across a range of state-of-the-art models and configurations. We provide 45 detailed vignettes that comprehensively cover all identified failure cases. This work highlights shortcomings that must be addressed before LLM-based clinical AI can be safely deployed. It also begs larger-scale, prospective evaluations and deeper study of LLM behaviours in clinical contexts.
TensOrMachine: Probabilistic Boolean Tensor Decomposition
May 11, 2018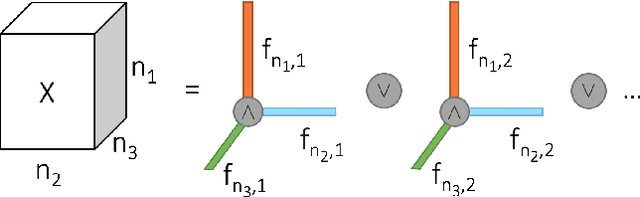
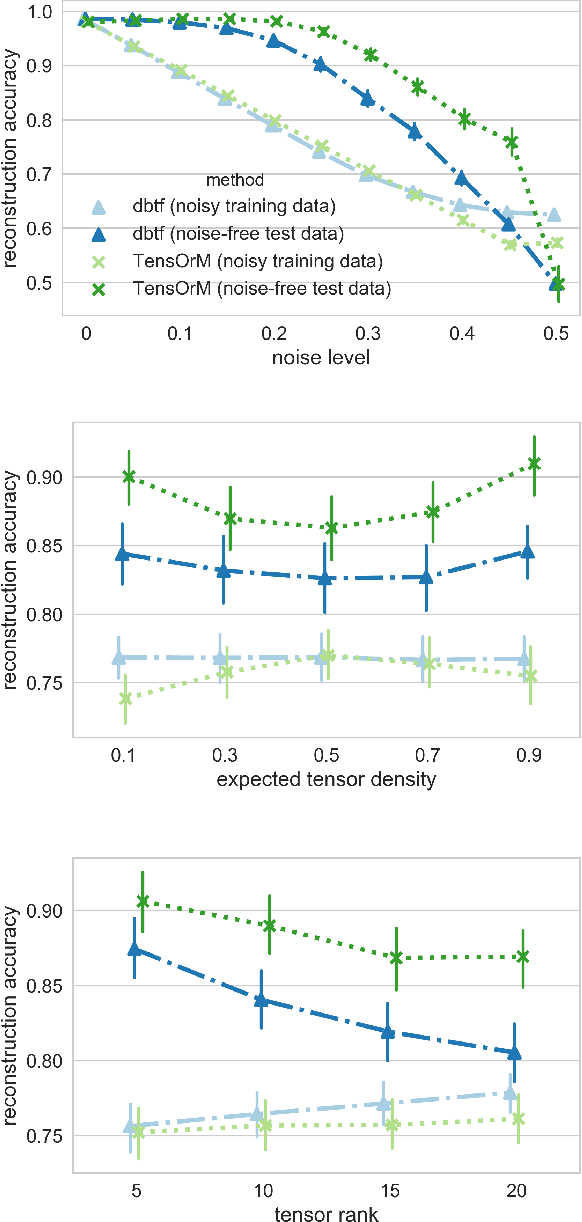

Boolean tensor decomposition approximates data of multi-way binary relationships as product of interpretable low-rank binary factors, following the rules of Boolean algebra. Here, we present its first probabilistic treatment. We facilitate scalable sampling-based posterior inference by exploitation of the combinatorial structure of the factor conditionals. Maximum a posteriori decompositions feature higher accuracies than existing techniques throughout a wide range of simulated conditions. Moreover, the probabilistic approach facilitates the treatment of missing data and enables model selection with much greater accuracy. We investigate three real-world data-sets. First, temporal interaction networks in a hospital ward and behavioural data of university students demonstrate the inference of instructive latent patterns. Next, we decompose a tensor with more than 10 billion data points, indicating relations of gene expression in cancer patients. Not only does this demonstrate scalability, it also provides an entirely novel perspective on relational properties of continuous data and, in the present example, on the molecular heterogeneity of cancer. Our implementation is available on GitHub: https://github.com/TammoR/LogicalFactorisationMachines.
Encrypted accelerated least squares regression
Mar 02, 2017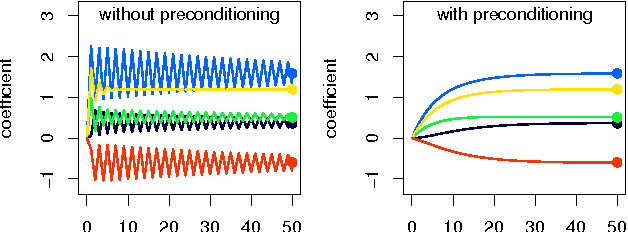

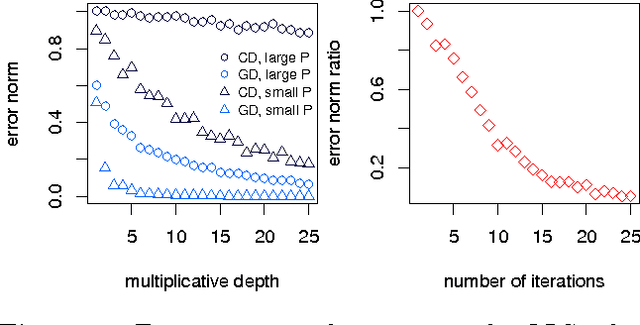
Information that is stored in an encrypted format is, by definition, usually not amenable to statistical analysis or machine learning methods. In this paper we present detailed analysis of coordinate and accelerated gradient descent algorithms which are capable of fitting least squares and penalised ridge regression models, using data encrypted under a fully homomorphic encryption scheme. Gradient descent is shown to dominate in terms of encrypted computational speed, and theoretical results are proven to give parameter bounds which ensure correctness of decryption. The characteristics of encrypted computation are empirically shown to favour a non-standard acceleration technique. This demonstrates the possibility of approximating conventional statistical regression methods using encrypted data without compromising privacy.
Bayesian Boolean Matrix Factorisation
Feb 25, 2017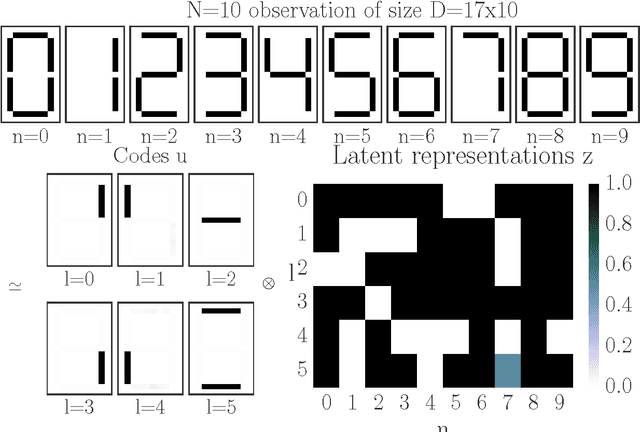
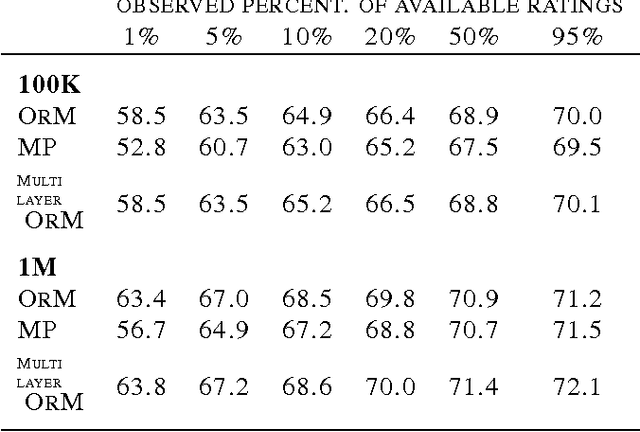
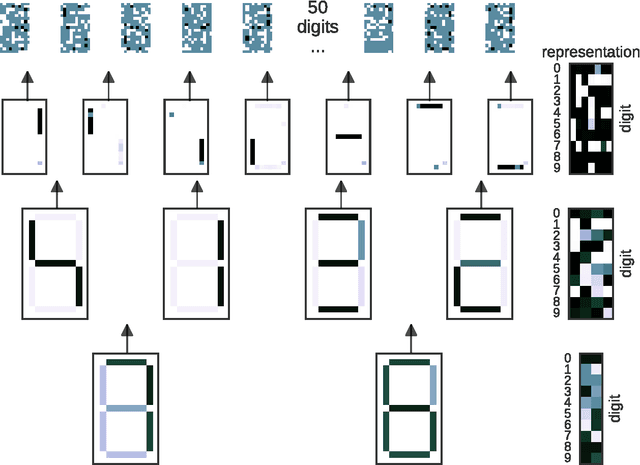
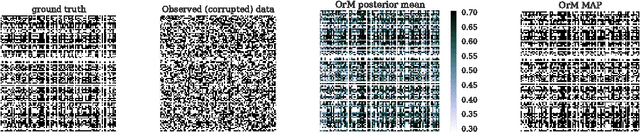
Boolean matrix factorisation aims to decompose a binary data matrix into an approximate Boolean product of two low rank, binary matrices: one containing meaningful patterns, the other quantifying how the observations can be expressed as a combination of these patterns. We introduce the OrMachine, a probabilistic generative model for Boolean matrix factorisation and derive a Metropolised Gibbs sampler that facilitates efficient parallel posterior inference. On real world and simulated data, our method outperforms all currently existing approaches for Boolean matrix factorisation and completion. This is the first method to provide full posterior inference for Boolean Matrix factorisation which is relevant in applications, e.g. for controlling false positive rates in collaborative filtering and, crucially, improves the interpretability of the inferred patterns. The proposed algorithm scales to large datasets as we demonstrate by analysing single cell gene expression data in 1.3 million mouse brain cells across 11 thousand genes on commodity hardware.
Encrypted statistical machine learning: new privacy preserving methods
Aug 27, 2015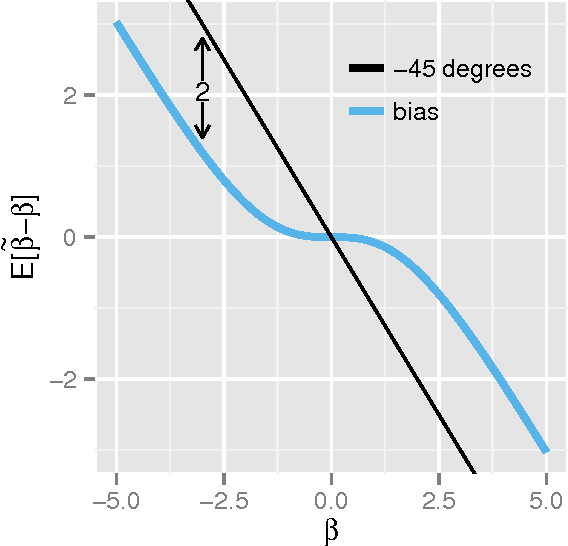
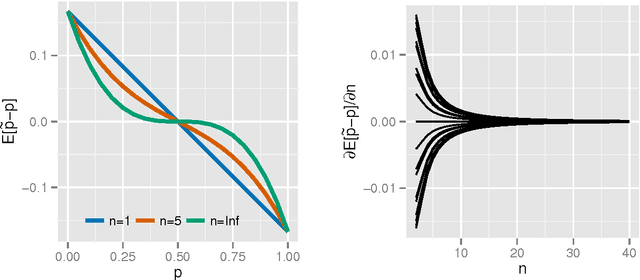
We present two new statistical machine learning methods designed to learn on fully homomorphic encrypted (FHE) data. The introduction of FHE schemes following Gentry (2009) opens up the prospect of privacy preserving statistical machine learning analysis and modelling of encrypted data without compromising security constraints. We propose tailored algorithms for applying extremely random forests, involving a new cryptographic stochastic fraction estimator, and na\"{i}ve Bayes, involving a semi-parametric model for the class decision boundary, and show how they can be used to learn and predict from encrypted data. We demonstrate that these techniques perform competitively on a variety of classification data sets and provide detailed information about the computational practicalities of these and other FHE methods.
A review of homomorphic encryption and software tools for encrypted statistical machine learning
Aug 26, 2015
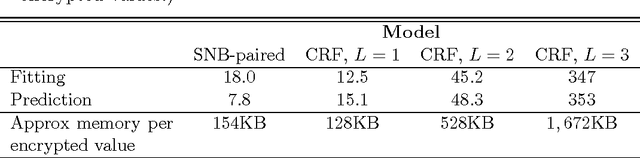
Recent advances in cryptography promise to enable secure statistical computation on encrypted data, whereby a limited set of operations can be carried out without the need to first decrypt. We review these homomorphic encryption schemes in a manner accessible to statisticians and machine learners, focusing on pertinent limitations inherent in the current state of the art. These limitations restrict the kind of statistics and machine learning algorithms which can be implemented and we review those which have been successfully applied in the literature. Finally, we document a high performance R package implementing a recent homomorphic scheme in a general framework.