 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen and How Does CLIP Enable Domain and Compositional Generalization?
Paper and Code
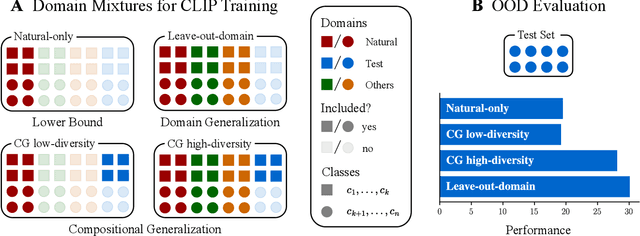

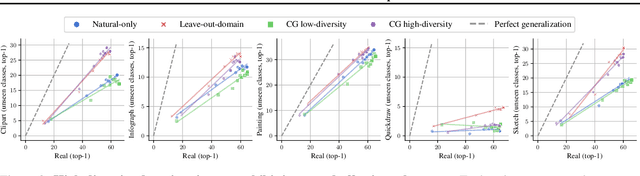

The remarkable generalization performance of contrastive vision-language models like CLIP is often attributed to the diversity of their training distributions. However, key questions remain unanswered: Can CLIP generalize to an entirely unseen domain when trained on a diverse mixture of domains (domain generalization)? Can it generalize to unseen classes within partially seen domains (compositional generalization)? What factors affect such generalization? To answer these questions, we trained CLIP models on systematically constructed training distributions with controlled domain diversity and object class exposure. Our experiments show that domain diversity is essential for both domain and compositional generalization, yet compositional generalization can be surprisingly weaker than domain generalization when the training distribution contains a suboptimal subset of the test domain. Through data-centric and mechanistic analyses, we find that successful generalization requires learning of shared representations already in intermediate layers and shared circuitry.