 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Bottleneck Models Without Predefined Concepts
Jul 04, 2024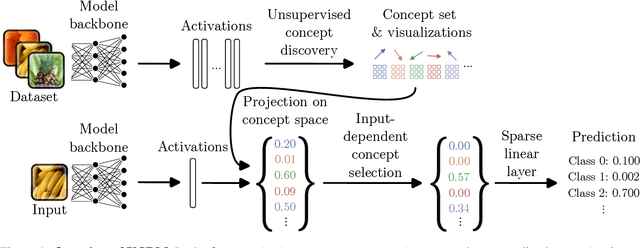

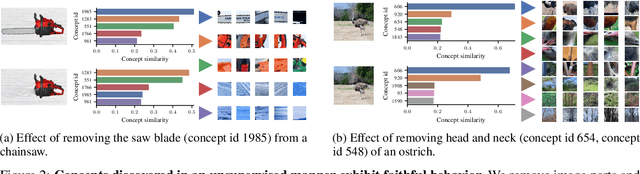

There has been considerable recent interest in interpretable concept-based models such as Concept Bottleneck Models (CBMs), which first predict human-interpretable concepts and then map them to output classes. To reduce reliance on human-annotated concepts, recent works have converted pretrained black-box models into interpretable CBMs post-hoc. However, these approaches predefine a set of concepts, assuming which concepts a black-box model encodes in its representations. In this work, we eliminate this assumption by leveraging unsupervised concept discovery to automatically extract concepts without human annotations or a predefined set of concepts. We further introduce an input-dependent concept selection mechanism that ensures only a small subset of concepts is used across all classes. We show that our approach improves downstream performance and narrows the performance gap to black-box models, while using significantly fewer concepts in the classification. Finally, we demonstrate how large vision-language models can intervene on the final model weights to correct model errors.