 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Behavior of Sparse Mixture-of-Experts Layers in CNN-based Semantic Segmentation
Apr 15, 2026Sparse mixture-of-experts (MoE) layers have been shown to substantially increase model capacity without a proportional increase in computational cost and are widely used in transformer architectures, where they typically replace feed-forward network blocks. In contrast, integrating sparse MoE layers into convolutional neural networks (CNNs) remains inconsistent, with most prior work focusing on fine-grained MoEs operating at the filter or channel levels. In this work, we investigate a coarser, patch-wise formulation of sparse MoE layers for semantic segmentation, where local regions are routed to a small subset of convolutional experts. Through experiments on the Cityscapes and BDD100K datasets using encoder-decoder and backbone-based CNNs, we conduct a design analysis to assess how architectural choices affect routing dynamics and expert specialization. Our results demonstrate consistent, architecture-dependent improvements (up to +3.9 mIoU) with little computational overhead, while revealing strong design sensitivity. Our work provides empirical insights into the design and internal dynamics of sparse MoE layers in CNN-based dense prediction. Our code is available at https://github.com/KASTEL-MobilityLab/moe-layers/.
Robust Experts: the Effect of Adversarial Training on CNNs with Sparse Mixture-of-Experts Layers
Sep 05, 2025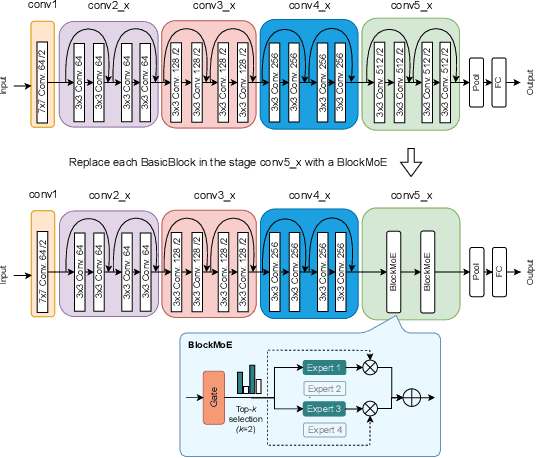
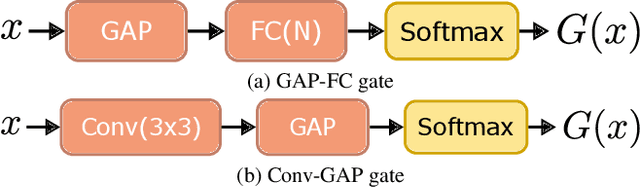
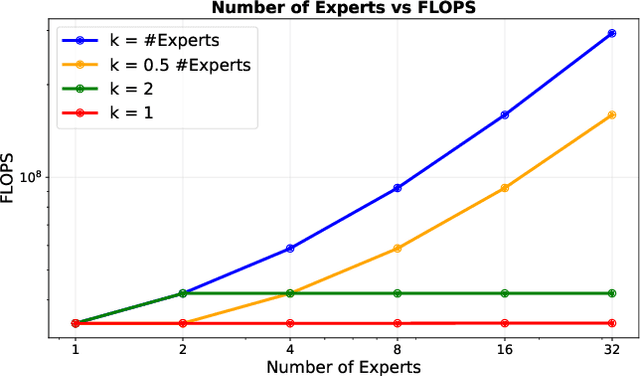
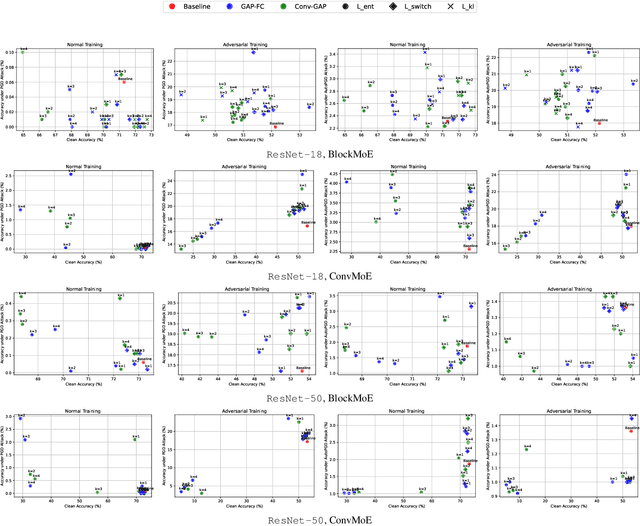
Robustifying convolutional neural networks (CNNs) against adversarial attacks remains challenging and often requires resource-intensive countermeasures. We explore the use of sparse mixture-of-experts (MoE) layers to improve robustness by replacing selected residual blocks or convolutional layers, thereby increasing model capacity without additional inference cost. On ResNet architectures trained on CIFAR-100, we find that inserting a single MoE layer in the deeper stages leads to consistent improvements in robustness under PGD and AutoPGD attacks when combined with adversarial training. Furthermore, we discover that when switch loss is used for balancing, it causes routing to collapse onto a small set of overused experts, thereby concentrating adversarial training on these paths and inadvertently making them more robust. As a result, some individual experts outperform the gated MoE model in robustness, suggesting that robust subpaths emerge through specialization. Our code is available at https://github.com/KASTEL-MobilityLab/robust-sparse-moes.
Self-Distilled Representation Learning for Time Series
Nov 19, 2023



Self-supervised learning for time-series data holds potential similar to that recently unleashed in Natural Language Processing and Computer Vision. While most existing works in this area focus on contrastive learning, we propose a conceptually simple yet powerful non-contrastive approach, based on the data2vec self-distillation framework. The core of our method is a student-teacher scheme that predicts the latent representation of an input time series from masked views of the same time series. This strategy avoids strong modality-specific assumptions and biases typically introduced by the design of contrastive sample pairs. We demonstrate the competitiveness of our approach for classification and forecasting as downstream tasks, comparing with state-of-the-art self-supervised learning methods on the UCR and UEA archives as well as the ETT and Electricity datasets.
Curve Your Enthusiasm: Concurvity Regularization in Differentiable Generalized Additive Models
May 19, 2023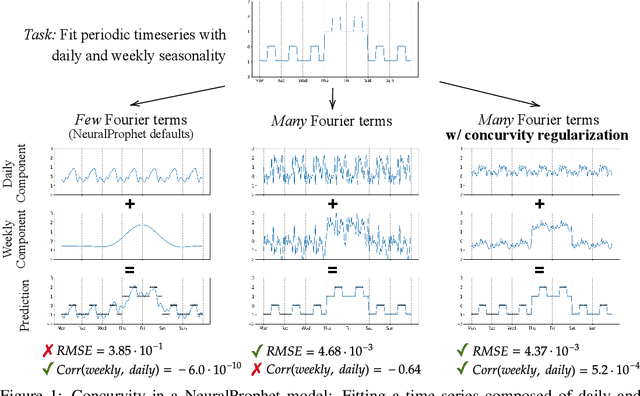

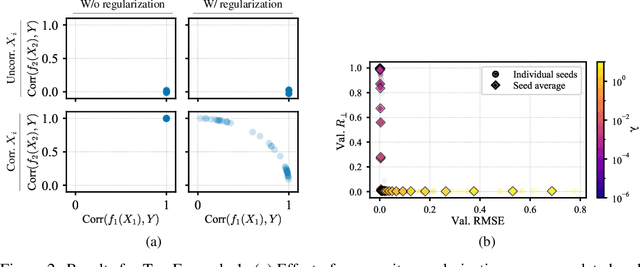
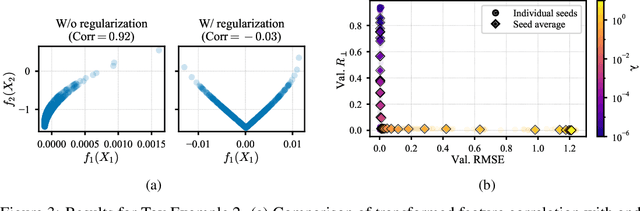
Generalized Additive Models (GAMs) have recently experienced a resurgence in popularity due to their interpretability, which arises from expressing the target value as a sum of non-linear transformations of the features. Despite the current enthusiasm for GAMs, their susceptibility to concurvity - i.e., (possibly non-linear) dependencies between the features - has hitherto been largely overlooked. Here, we demonstrate how concurvity can severly impair the interpretability of GAMs and propose a remedy: a conceptually simple, yet effective regularizer which penalizes pairwise correlations of the non-linearly transformed feature variables. This procedure is applicable to any differentiable additive model, such as Neural Additive Models or NeuralProphet, and enhances interpretability by eliminating ambiguities due to self-canceling feature contributions. We validate the effectiveness of our regularizer in experiments on synthetic as well as real-world datasets for time-series and tabular data. Our experiments show that concurvity in GAMs can be reduced without significantly compromising prediction quality, improving interpretability and reducing variance in the feature importances.
Auto-Compressing Subset Pruning for Semantic Image Segmentation
Jan 26, 2022State-of-the-art semantic segmentation models are characterized by high parameter counts and slow inference times, making them unsuitable for deployment in resource-constrained environments. To address this challenge, we propose \textsc{Auto-Compressing Subset Pruning}, \acosp, as a new online compression method. The core of \acosp consists of learning a channel selection mechanism for individual channels of each convolution in the segmentation model based on an effective temperature annealing schedule. We show a crucial interplay between providing a high-capacity model at the beginning of training and the compression pressure forcing the model to compress concepts into retained channels. We apply \acosp to \segnet and \pspnet architectures and show its success when trained on the \camvid, \city, \voc, and \ade datasets. The results are competitive with existing baselines for compression of segmentation models at low compression ratios and outperform them significantly at high compression ratios, yielding acceptable results even when removing more than $93\%$ of the parameters. In addition, \acosp is conceptually simple, easy to implement, and can readily be generalized to other data modalities, tasks, and architectures. Our code is available at \url{https://github.com/merantix/acosp}.