 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Non-Parametric Time Series Forecaster
Dec 22, 2023



This paper presents non-parametric baseline models for time series forecasting. Unlike classical forecasting models, the proposed approach does not assume any parametric form for the predictive distribution and instead generates predictions by sampling from the empirical distribution according to a tunable strategy. By virtue of this, the model is always able to produce reasonable forecasts (i.e., predictions within the observed data range) without fail unlike classical models that suffer from numerical stability on some data distributions. Moreover, we develop a global version of the proposed method that automatically learns the sampling strategy by exploiting the information across multiple related time series. The empirical evaluation shows that the proposed methods have reasonable and consistent performance across all datasets, proving them to be strong baselines to be considered in one's forecasting toolbox.
Criteria for Classifying Forecasting Methods
Dec 07, 2022


Classifying forecasting methods as being either of a "machine learning" or "statistical" nature has become commonplace in parts of the forecasting literature and community, as exemplified by the M4 competition and the conclusion drawn by the organizers. We argue that this distinction does not stem from fundamental differences in the methods assigned to either class. Instead, this distinction is probably of a tribal nature, which limits the insights into the appropriateness and effectiveness of different forecasting methods. We provide alternative characteristics of forecasting methods which, in our view, allow to draw meaningful conclusions. Further, we discuss areas of forecasting which could benefit most from cross-pollination between the ML and the statistics communities.
Intrinsic Anomaly Detection for Multi-Variate Time Series
Jun 29, 2022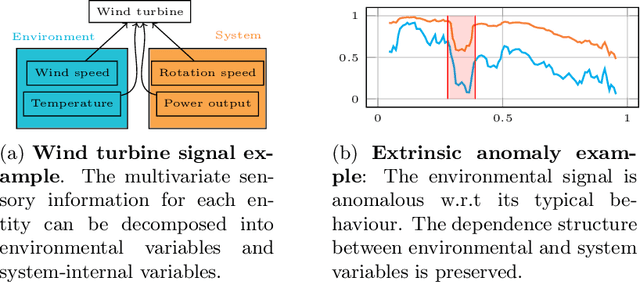

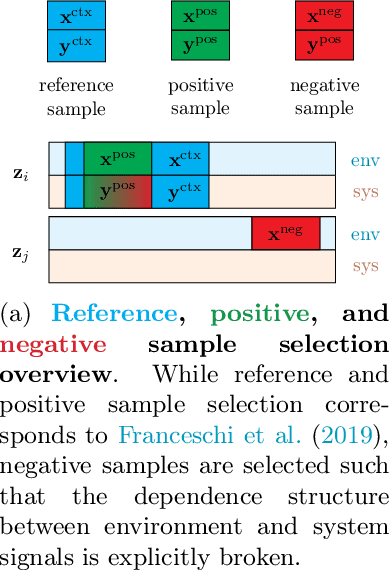
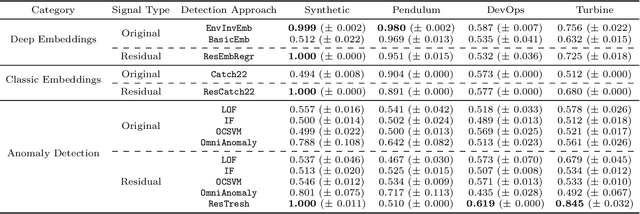
We introduce a novel, practically relevant variation of the anomaly detection problem in multi-variate time series: intrinsic anomaly detection. It appears in diverse practical scenarios ranging from DevOps to IoT, where we want to recognize failures of a system that operates under the influence of a surrounding environment. Intrinsic anomalies are changes in the functional dependency structure between time series that represent an environment and time series that represent the internal state of a system that is placed in said environment. We formalize this problem, provide under-studied public and new purpose-built data sets for it, and present methods that handle intrinsic anomaly detection. These address the short-coming of existing anomaly detection methods that cannot differentiate between expected changes in the system's state and unexpected ones, i.e., changes in the system that deviate from the environment's influence. Our most promising approach is fully unsupervised and combines adversarial learning and time series representation learning, thereby addressing problems such as label sparsity and subjectivity, while allowing to navigate and improve notoriously problematic anomaly detection data sets.
Multi-Objective Model Selection for Time Series Forecasting
Feb 17, 2022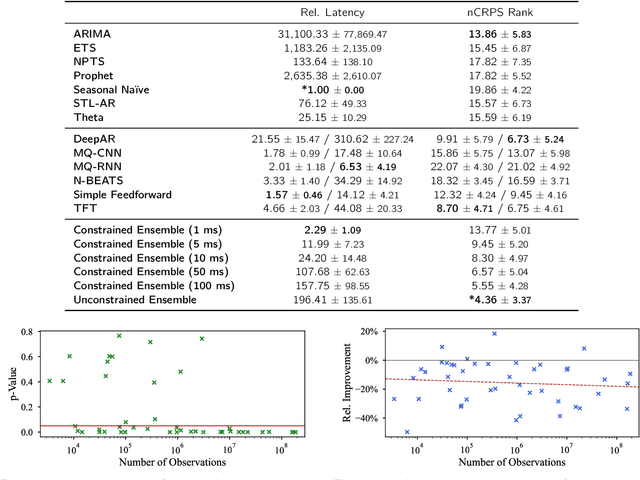



Research on time series forecasting has predominantly focused on developing methods that improve accuracy. However, other criteria such as training time or latency are critical in many real-world applications. We therefore address the question of how to choose an appropriate forecasting model for a given dataset among the plethora of available forecasting methods when accuracy is only one of many criteria. For this, our contributions are two-fold. First, we present a comprehensive benchmark, evaluating 7 classical and 6 deep learning forecasting methods on 44 heterogeneous, publicly available datasets. The benchmark code is open-sourced along with evaluations and forecasts for all methods. These evaluations enable us to answer open questions such as the amount of data required for deep learning models to outperform classical ones. Second, we leverage the benchmark evaluations to learn good defaults that consider multiple objectives such as accuracy and latency. By learning a mapping from forecasting models to performance metrics, we show that our method PARETOSELECT is able to accurately select models from the Pareto front -- alleviating the need to train or evaluate many forecasting models for model selection. To the best of our knowledge, PARETOSELECT constitutes the first method to learn default models in a multi-objective setting.
Meta-Forecasting by combining Global Deep Representations with Local Adaptation
Nov 12, 2021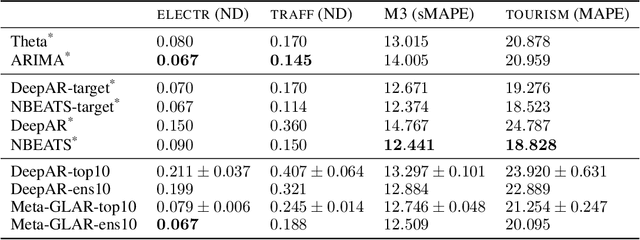
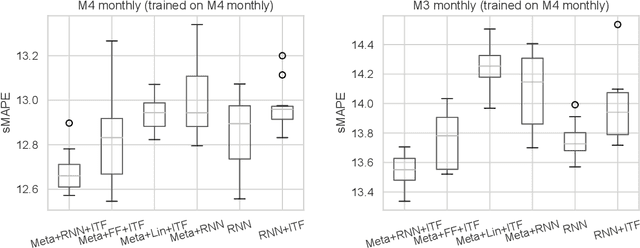


While classical time series forecasting considers individual time series in isolation, recent advances based on deep learning showed that jointly learning from a large pool of related time series can boost the forecasting accuracy. However, the accuracy of these methods suffers greatly when modeling out-of-sample time series, significantly limiting their applicability compared to classical forecasting methods. To bridge this gap, we adopt a meta-learning view of the time series forecasting problem. We introduce a novel forecasting method, called Meta Global-Local Auto-Regression (Meta-GLAR), that adapts to each time series by learning in closed-form the mapping from the representations produced by a recurrent neural network (RNN) to one-step-ahead forecasts. Crucially, the parameters ofthe RNN are learned across multiple time series by backpropagating through the closed-form adaptation mechanism. In our extensive empirical evaluation we show that our method is competitive with the state-of-the-art in out-of-sample forecasting accuracy reported in earlier work.
Neural Contextual Anomaly Detection for Time Series
Jul 16, 2021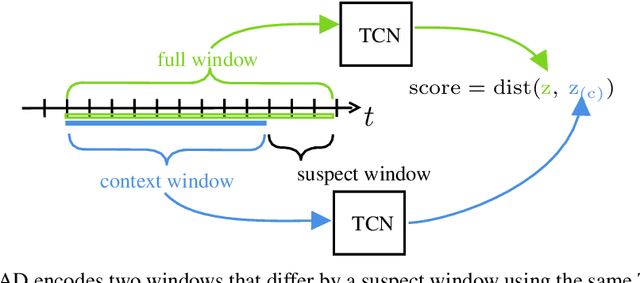
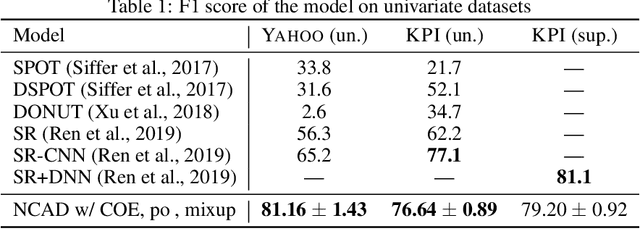
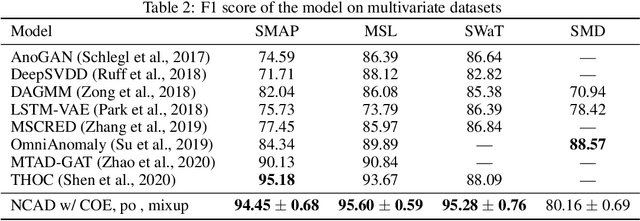
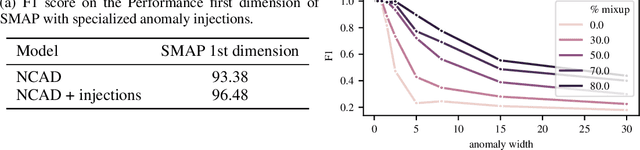
We introduce Neural Contextual Anomaly Detection (NCAD), a framework for anomaly detection on time series that scales seamlessly from the unsupervised to supervised setting, and is applicable to both univariate and multivariate time series. This is achieved by effectively combining recent developments in representation learning for multivariate time series, with techniques for deep anomaly detection originally developed for computer vision that we tailor to the time series setting. Our window-based approach facilitates learning the boundary between normal and anomalous classes by injecting generic synthetic anomalies into the available data. Moreover, our method can effectively take advantage of all the available information, be it as domain knowledge, or as training labels in the semi-supervised setting. We demonstrate empirically on standard benchmark datasets that our approach obtains a state-of-the-art performance in these settings.
A simple and effective predictive resource scaling heuristic for large-scale cloud applications
Aug 03, 2020

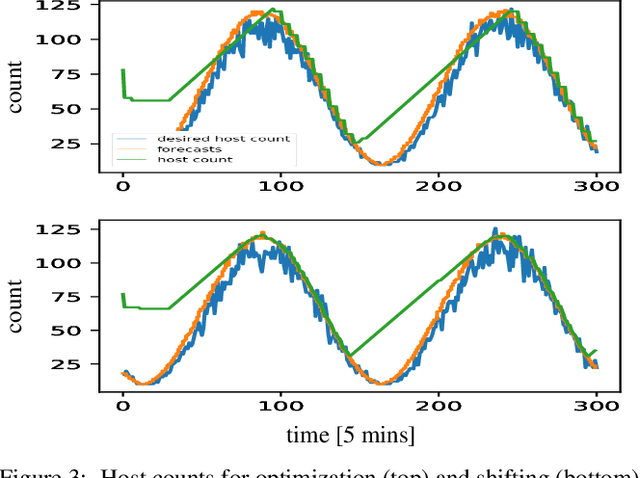

We propose a simple yet effective policy for the predictive auto-scaling of horizontally scalable applications running in cloud environments, where compute resources can only be added with a delay, and where the deployment throughput is limited. Our policy uses a probabilistic forecast of the workload to make scaling decisions dependent on the risk aversion of the application owner. We show in our experiments using real-world and synthetic data that this policy compares favorably to mathematically more sophisticated approaches as well as to simple benchmark policies.
The Effectiveness of Discretization in Forecasting: An Empirical Study on Neural Time Series Models
May 20, 2020
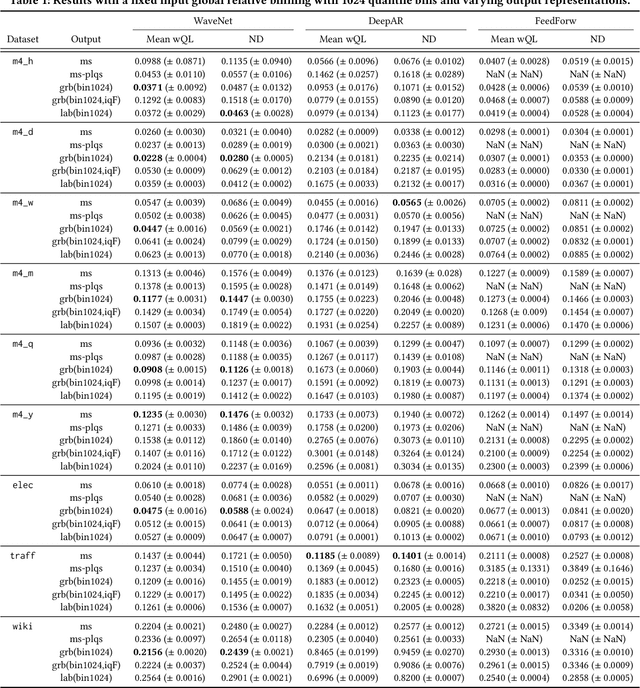

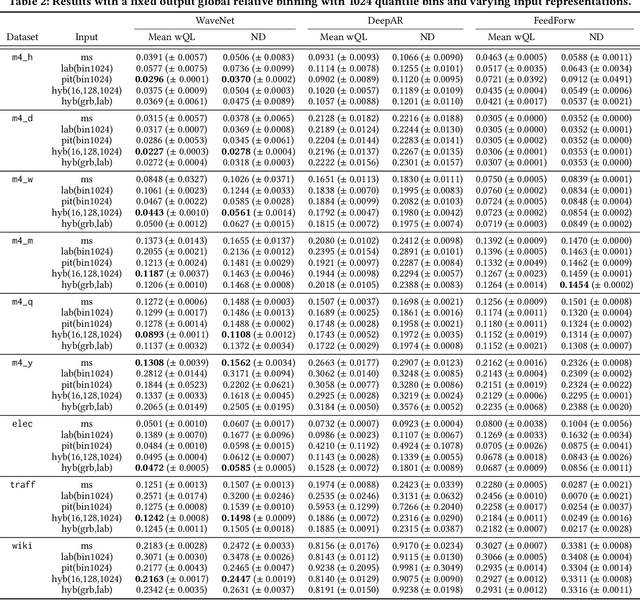
Time series modeling techniques based on deep learning have seen many advancements in recent years, especially in data-abundant settings and with the central aim of learning global models that can extract patterns across multiple time series. While the crucial importance of appropriate data pre-processing and scaling has often been noted in prior work, most studies focus on improving model architectures. In this paper we empirically investigate the effect of data input and output transformations on the predictive performance of several neural forecasting architectures. In particular, we investigate the effectiveness of several forms of data binning, i.e. converting real-valued time series into categorical ones, when combined with feed-forward, recurrent neural networks, and convolution-based sequence models. In many non-forecasting applications where these models have been very successful, the model inputs and outputs are categorical (e.g. words from a fixed vocabulary in natural language processing applications or quantized pixel color intensities in computer vision). For forecasting applications, where the time series are typically real-valued, various ad-hoc data transformations have been proposed, but have not been systematically compared. To remedy this, we evaluate the forecasting accuracy of instances of the aforementioned model classes when combined with different types of data scaling and binning. We find that binning almost always improves performance (compared to using normalized real-valued inputs), but that the particular type of binning chosen is of lesser importance.
Neural forecasting: Introduction and literature overview
Apr 21, 2020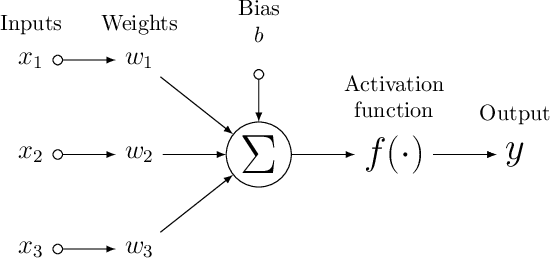

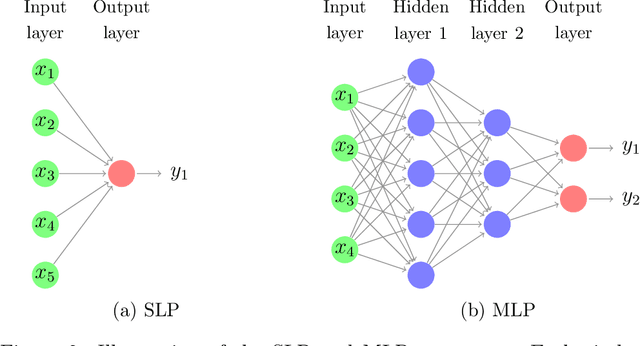

Neural network based forecasting methods have become ubiquitous in large-scale industrial forecasting applications over the last years. As the prevalence of neural network based solutions among the best entries in the recent M4 competition shows, the recent popularity of neural forecasting methods is not limited to industry and has also reached academia. This article aims at providing an introduction and an overview of some of the advances that have permitted the resurgence of neural networks in machine learning. Building on these foundations, the article then gives an overview of the recent literature on neural networks for forecasting and applications.
GluonTS: Probabilistic Time Series Models in Python
Jun 14, 2019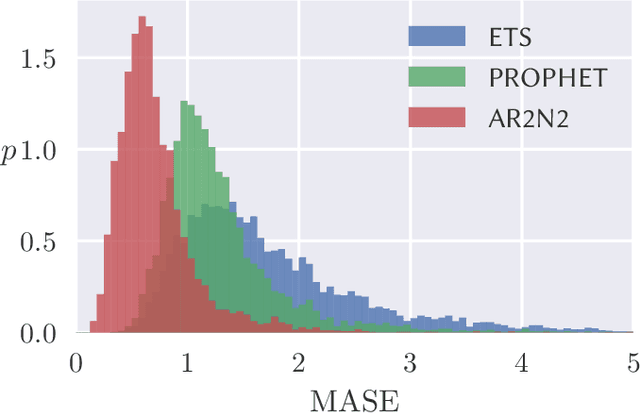

We introduce Gluon Time Series (GluonTS, available at https://gluon-ts.mxnet.io), a library for deep-learning-based time series modeling. GluonTS simplifies the development of and experimentation with time series models for common tasks such as forecasting or anomaly detection. It provides all necessary components and tools that scientists need for quickly building new models, for efficiently running and analyzing experiments and for evaluating model accuracy.