 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Anomaly Detection for Multi-Variate Time Series
Jun 29, 2022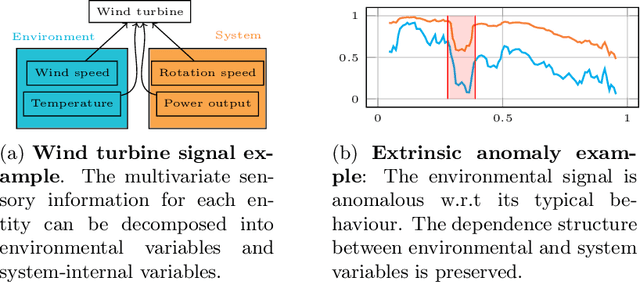

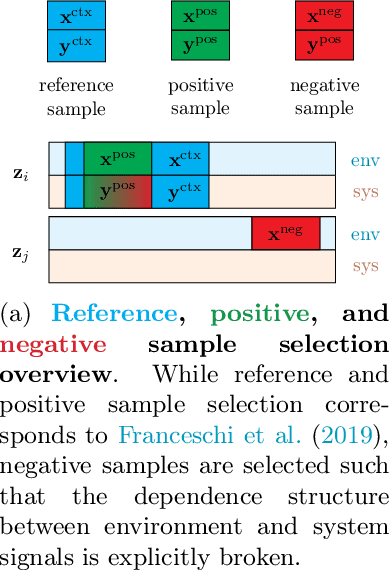
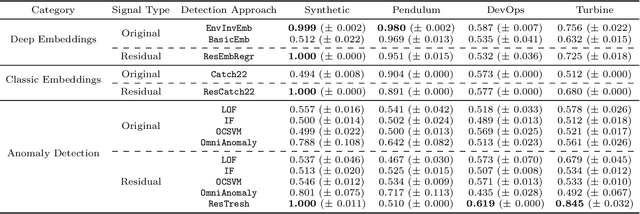
We introduce a novel, practically relevant variation of the anomaly detection problem in multi-variate time series: intrinsic anomaly detection. It appears in diverse practical scenarios ranging from DevOps to IoT, where we want to recognize failures of a system that operates under the influence of a surrounding environment. Intrinsic anomalies are changes in the functional dependency structure between time series that represent an environment and time series that represent the internal state of a system that is placed in said environment. We formalize this problem, provide under-studied public and new purpose-built data sets for it, and present methods that handle intrinsic anomaly detection. These address the short-coming of existing anomaly detection methods that cannot differentiate between expected changes in the system's state and unexpected ones, i.e., changes in the system that deviate from the environment's influence. Our most promising approach is fully unsupervised and combines adversarial learning and time series representation learning, thereby addressing problems such as label sparsity and subjectivity, while allowing to navigate and improve notoriously problematic anomaly detection data sets.
Multi-Objective Model Selection for Time Series Forecasting
Feb 17, 2022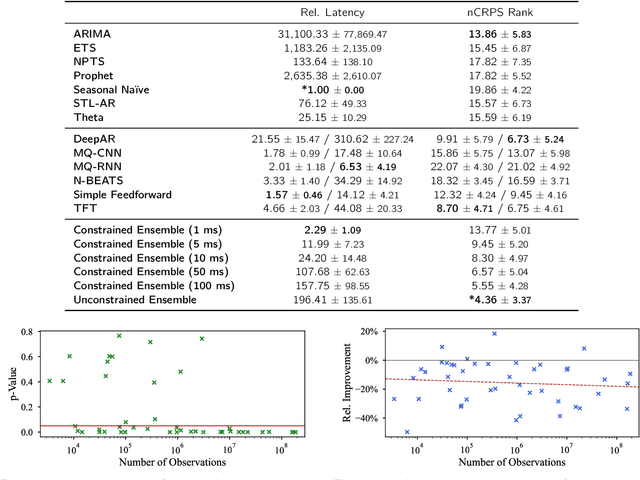



Research on time series forecasting has predominantly focused on developing methods that improve accuracy. However, other criteria such as training time or latency are critical in many real-world applications. We therefore address the question of how to choose an appropriate forecasting model for a given dataset among the plethora of available forecasting methods when accuracy is only one of many criteria. For this, our contributions are two-fold. First, we present a comprehensive benchmark, evaluating 7 classical and 6 deep learning forecasting methods on 44 heterogeneous, publicly available datasets. The benchmark code is open-sourced along with evaluations and forecasts for all methods. These evaluations enable us to answer open questions such as the amount of data required for deep learning models to outperform classical ones. Second, we leverage the benchmark evaluations to learn good defaults that consider multiple objectives such as accuracy and latency. By learning a mapping from forecasting models to performance metrics, we show that our method PARETOSELECT is able to accurately select models from the Pareto front -- alleviating the need to train or evaluate many forecasting models for model selection. To the best of our knowledge, PARETOSELECT constitutes the first method to learn default models in a multi-objective setting.
Natural Posterior Network: Deep Bayesian Predictive Uncertainty for Exponential Family Distributions
May 10, 2021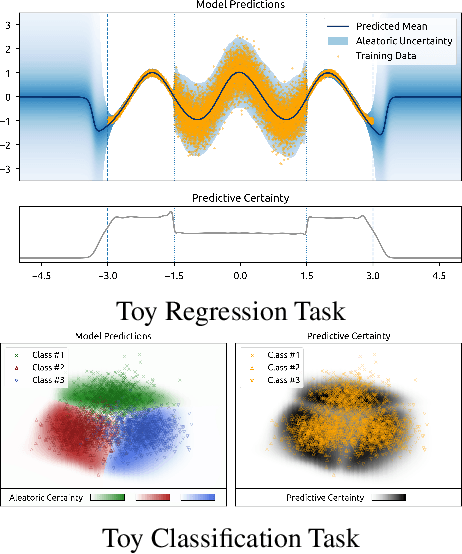



Uncertainty awareness is crucial to develop reliable machine learning models. In this work, we propose the Natural Posterior Network (NatPN) for fast and high-quality uncertainty estimation for any task where the target distribution belongs to the exponential family. Thus, NatPN finds application for both classification and general regression settings. Unlike many previous approaches, NatPN does not require out-of-distribution (OOD) data at training time. Instead, it leverages Normalizing Flows to fit a single density on a learned low-dimensional and task-dependent latent space. For any input sample, NatPN uses the predicted likelihood to perform a Bayesian update over the target distribution. Theoretically, NatPN assigns high uncertainty far away from training data. Empirically, our extensive experiments on calibration and OOD detection show that NatPN delivers highly competitive performance for classification, regression and count prediction tasks.