 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualize Me -- The Case for Context in Reinforcement Learning
Paper and Code
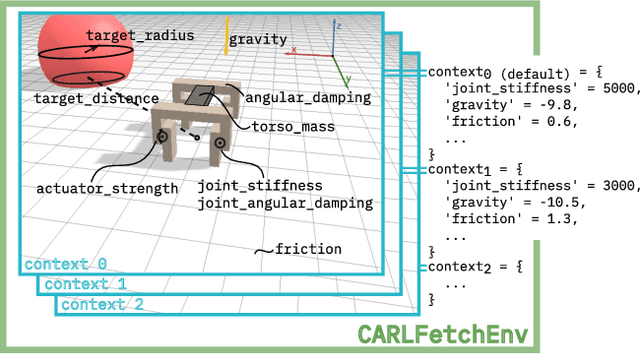
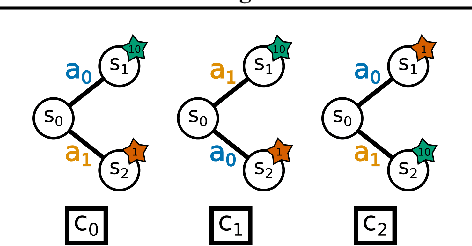
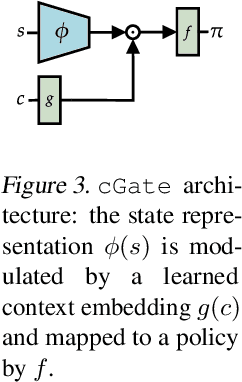
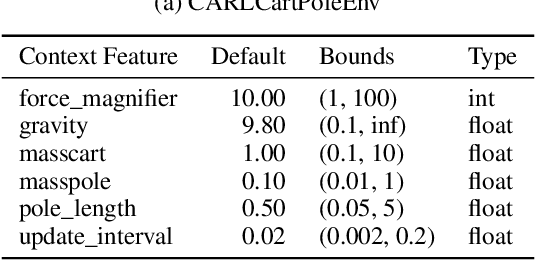
While Reinforcement Learning (RL) has made great strides towards solving increasingly complicated problems, many algorithms are still brittle to even slight changes in environments. Contextual Reinforcement Learning (cRL) provides a theoretical framework to model such changes in a principled manner, thereby enabling flexible, precise and interpretable task specification and generation. Thus, cRL is an important formalization for studying generalization in RL. In this work, we reason about solving cRL in theory and practice. We show that theoretically optimal behavior in contextual Markov Decision Processes requires explicit context information. In addition, we empirically explore context-based task generation, utilizing context information in training and propose cGate, our state-modulating policy architecture. To this end, we introduce the first benchmark library designed for generalization based on cRL extensions of popular benchmarks, CARL. In short: Context matters!