 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Risk Adaptation in Distributional Reinforcement Learning
Paper and Code
Jun 11, 2021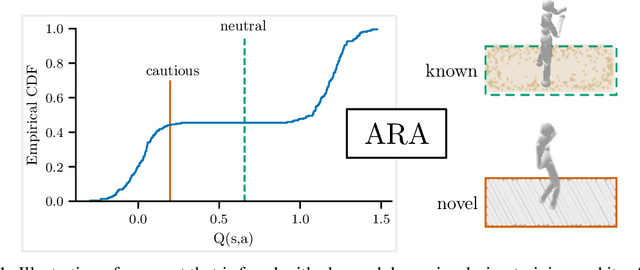


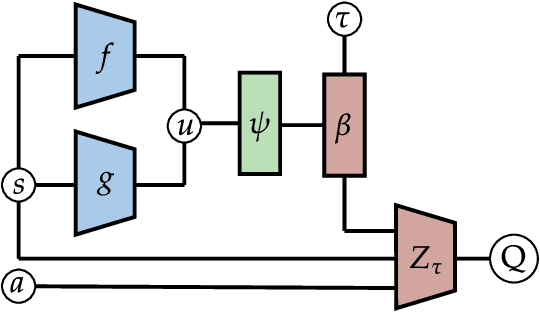
The use of Reinforcement Learning (RL) agents in practical applications requires the consideration of suboptimal outcomes, depending on the familiarity of the agent with its environment. This is especially important in safety-critical environments, where errors can lead to high costs or damage. In distributional RL, the risk-sensitivity can be controlled via different distortion measures of the estimated return distribution. However, these distortion functions require an estimate of the risk level, which is difficult to obtain and depends on the current state. In this work, we demonstrate the suboptimality of a static risk level estimation and propose a method to dynamically select risk levels at each environment step. Our method ARA (Automatic Risk Adaptation) estimates the appropriate risk level in both known and unknown environments using a Random Network Distillation error. We show reduced failure rates by up to a factor of 7 and improved generalization performance by up to 14% compared to both risk-aware and risk-agnostic agents in several locomotion environments.