 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of Modern Architectures and Regularization Approaches on CheXpert5000
Feb 13, 2023Computer aided diagnosis (CAD) has gained an increased amount of attention in the general research community over the last years as an example of a typical limited data application - with experiments on labeled 100k-200k datasets. Although these datasets are still small compared to natural image datasets like ImageNet1k, ImageNet21k and JFT, they are large for annotated medical datasets, where 1k-10k labeled samples are much more common. There is no baseline on which methods to build on in the low data regime. In this work we bridge this gap by providing an extensive study on medical image classification with limited annotations (5k). We present a study of modern architectures applied to a fixed low data regime of 5000 images on the CheXpert dataset. Conclusively we find that models pretrained on ImageNet21k achieve a higher AUC and larger models require less training steps. All models are quite well calibrated even though we only fine-tuned on 5000 training samples. All 'modern' architectures have higher AUC than ResNet50. Regularization of Big Transfer Models with MixUp or Mean Teacher improves calibration, MixUp also improves accuracy. Vision Transformer achieve comparable or on par results to Big Transfer Models.
Two-Stream Aural-Visual Affect Analysis in the Wild
Mar 03, 2020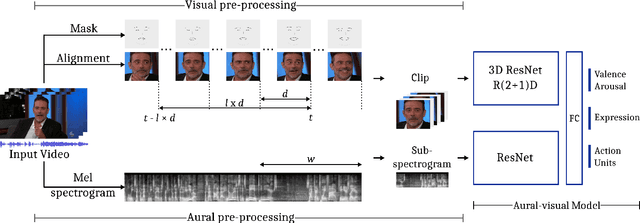
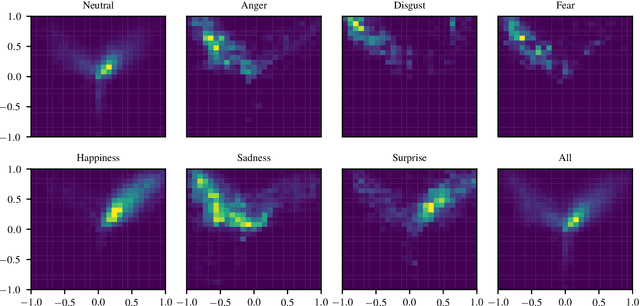

Human affect recognition is an essential part of natural human-computer interaction. However, current methods are still in their infancy, especially for in-the-wild data. In this work, we introduce our submission to the Affective Behavior Analysis in-the-wild (ABAW) 2020 competition. We propose a two-stream aural-visual analysis model to recognize affective behavior from videos. Audio and image streams are first processed separately and fed into a convolutional neural network. Instead of applying recurrent architectures for temporal analysis we only use temporal convolutions. Furthermore, the model is given access to additional features extracted during face-alignment. At training time, we exploit correlations between different emotion representations to improve performance. Our model achieves promising results on the challenging Aff-Wild2 database.
Unsupervised Features for Facial Expression Intensity Estimation over Time
May 03, 2018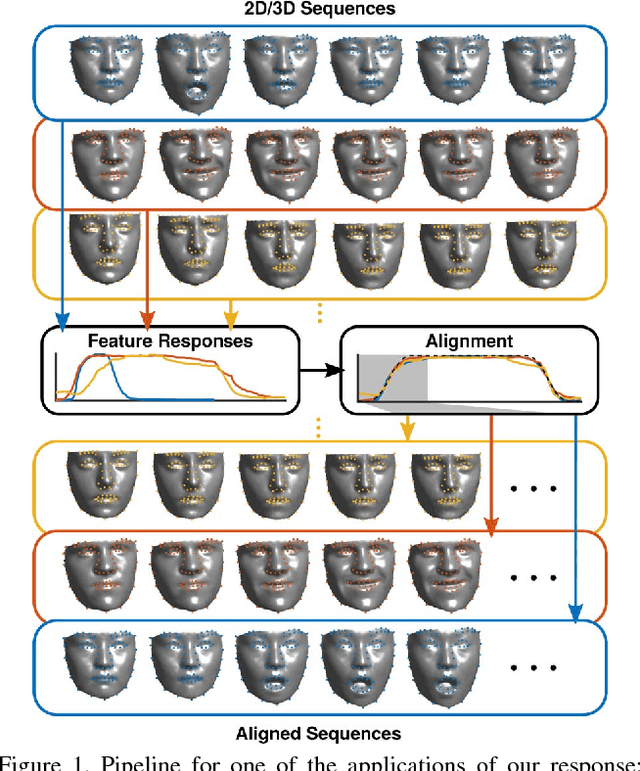
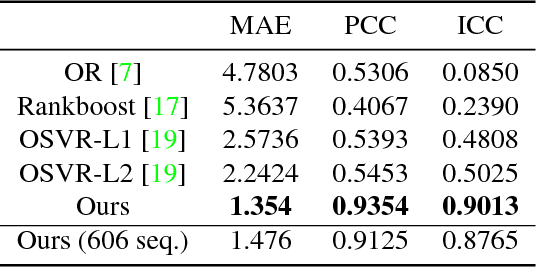
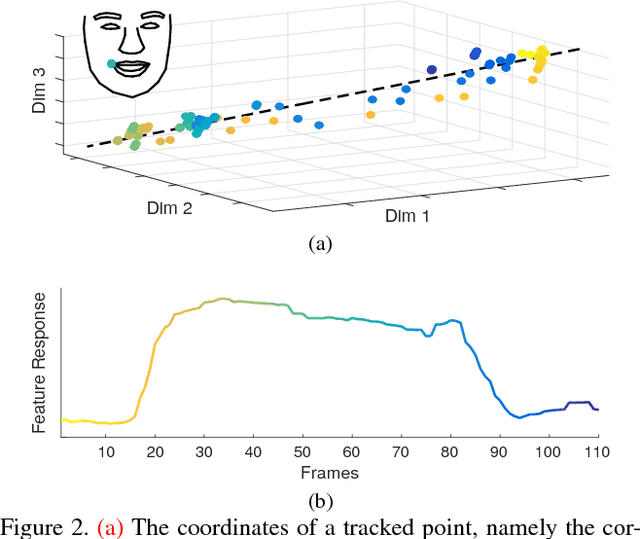
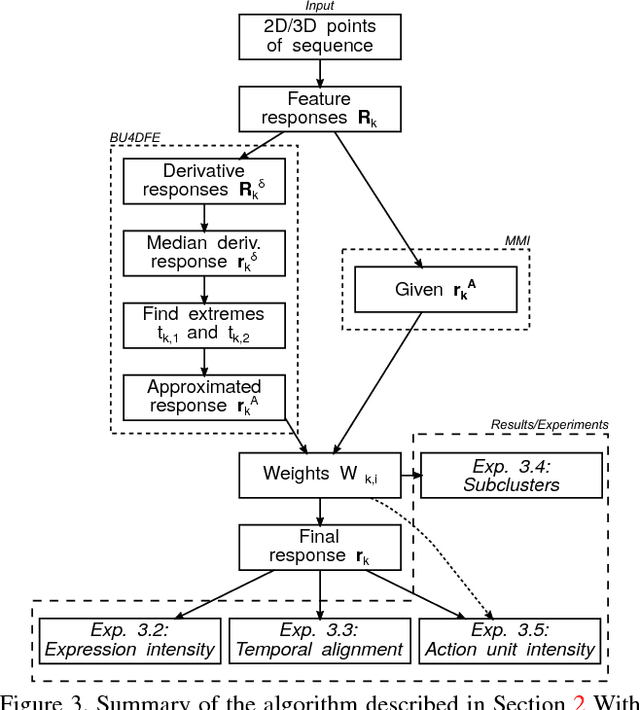
The diversity of facial shapes and motions among persons is one of the greatest challenges for automatic analysis of facial expressions. In this paper, we propose a feature describing expression intensity over time, while being invariant to person and the type of performed expression. Our feature is a weighted combination of the dynamics of multiple points adapted to the overall expression trajectory. We evaluate our method on several tasks all related to temporal analysis of facial expression. The proposed feature is compared to a state-of-the-art method for expression intensity estimation, which it outperforms. We use our proposed feature to temporally align multiple sequences of recorded 3D facial expressions. Furthermore, we show how our feature can be used to reveal person-specific differences in performances of facial expressions. Additionally, we apply our feature to identify the local changes in face video sequences based on action unit labels. For all the experiments our feature proves to be robust against noise and outliers, making it applicable to a variety of applications for analysis of facial movements.