 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of Modern Architectures and Regularization Approaches on CheXpert5000
Feb 13, 2023Computer aided diagnosis (CAD) has gained an increased amount of attention in the general research community over the last years as an example of a typical limited data application - with experiments on labeled 100k-200k datasets. Although these datasets are still small compared to natural image datasets like ImageNet1k, ImageNet21k and JFT, they are large for annotated medical datasets, where 1k-10k labeled samples are much more common. There is no baseline on which methods to build on in the low data regime. In this work we bridge this gap by providing an extensive study on medical image classification with limited annotations (5k). We present a study of modern architectures applied to a fixed low data regime of 5000 images on the CheXpert dataset. Conclusively we find that models pretrained on ImageNet21k achieve a higher AUC and larger models require less training steps. All models are quite well calibrated even though we only fine-tuned on 5000 training samples. All 'modern' architectures have higher AUC than ResNet50. Regularization of Big Transfer Models with MixUp or Mean Teacher improves calibration, MixUp also improves accuracy. Vision Transformer achieve comparable or on par results to Big Transfer Models.
Recalibration of Aleatoric and Epistemic Regression Uncertainty in Medical Imaging
Apr 26, 2021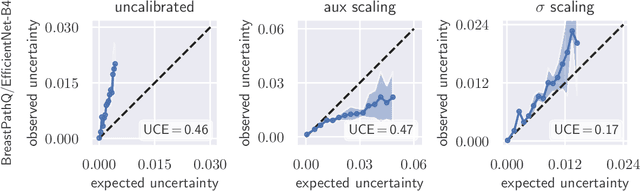
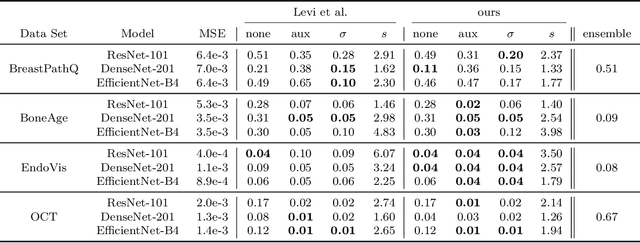
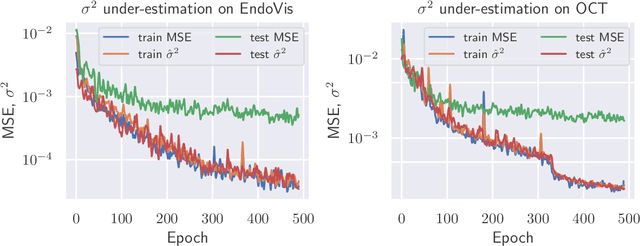
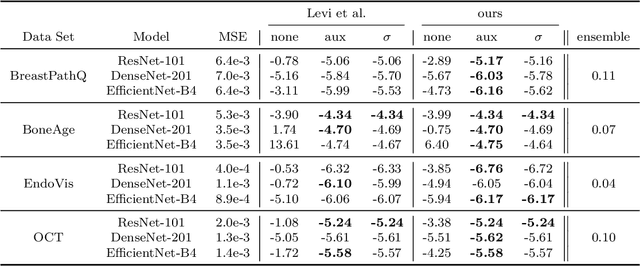
The consideration of predictive uncertainty in medical imaging with deep learning is of utmost importance. We apply estimation of both aleatoric and epistemic uncertainty by variational Bayesian inference with Monte Carlo dropout to regression tasks and show that predictive uncertainty is systematically underestimated. We apply $ \sigma $ scaling with a single scalar value; a simple, yet effective calibration method for both types of uncertainty. The performance of our approach is evaluated on a variety of common medical regression data sets using different state-of-the-art convolutional network architectures. In our experiments, $ \sigma $ scaling is able to reliably recalibrate predictive uncertainty. It is easy to implement and maintains the accuracy. Well-calibrated uncertainty in regression allows robust rejection of unreliable predictions or detection of out-of-distribution samples. Our source code is available at https://github.com/mlaves/well-calibrated-regression-uncertainty
Patient-Specific Domain Adaptation for Fast Optical Flow Based on Teacher-Student Knowledge Transfer
Jul 09, 2020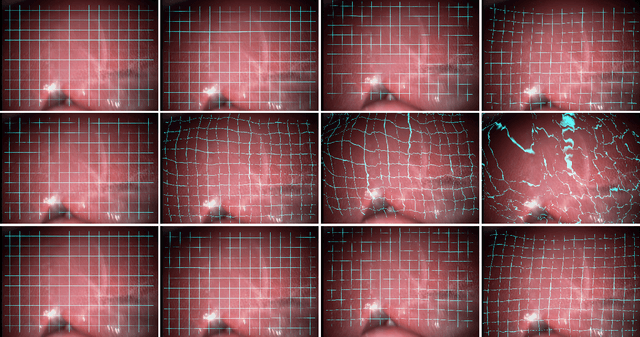

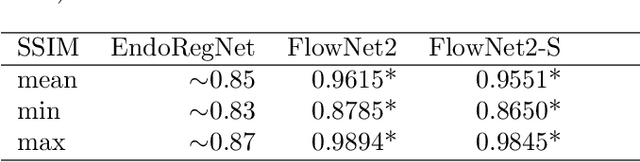
Fast motion feedback is crucial in computer-aided surgery (CAS) on moving tissue. Image-assistance in safety-critical vision applications requires a dense tracking of tissue motion. This can be done using optical flow (OF). Accurate motion predictions at high processing rates lead to higher patient safety. Current deep learning OF models show the common speed vs. accuracy trade-off. To achieve high accuracy at high processing rates, we propose patient-specific fine-tuning of a fast model. This minimizes the domain gap between training and application data, while reducing the target domain to the capability of the lower complex, fast model. We propose to obtain training sequences pre-operatively in the operation room. We handle missing ground truth, by employing teacher-student learning. Using flow estimations from teacher model FlowNet2 we specialize a fast student model FlowNet2S on the patient-specific domain. Evaluation is performed on sequences from the Hamlyn dataset. Our student model shows very good performance after fine-tuning. Tracking accuracy is comparable to the teacher model at a speed up of factor six. Fine-tuning can be performed within minutes, making it feasible for the operation room. Our method allows to use a real-time capable model that was previously not suited for this task. This method is laying the path for improved patient-specific motion estimation in CAS.
Calibration of Model Uncertainty for Dropout Variational Inference
Jun 20, 2020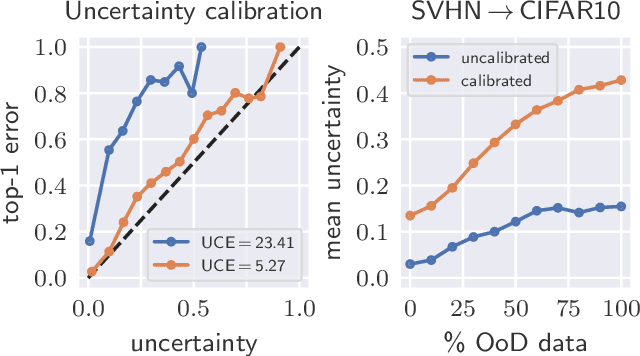
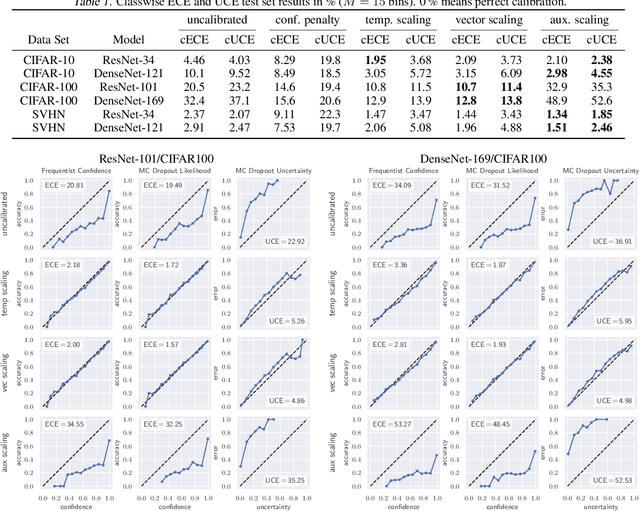
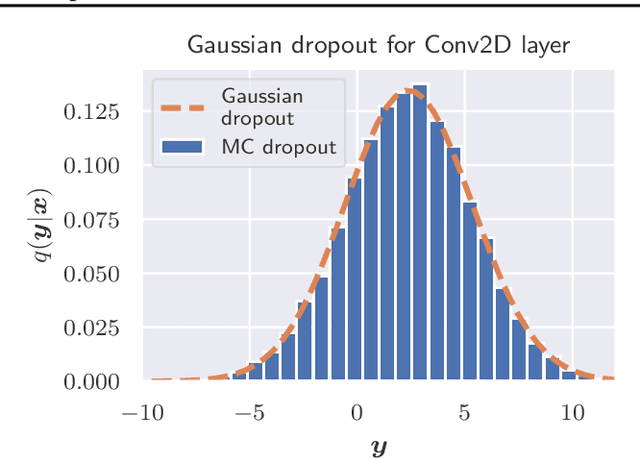

The model uncertainty obtained by variational Bayesian inference with Monte Carlo dropout is prone to miscalibration. In this paper, different logit scaling methods are extended to dropout variational inference to recalibrate model uncertainty. Expected uncertainty calibration error (UCE) is presented as a metric to measure miscalibration. The effectiveness of recalibration is evaluated on CIFAR-10/100 and SVHN for recent CNN architectures. Experimental results show that logit scaling considerably reduce miscalibration by means of UCE. Well-calibrated uncertainty enables reliable rejection of uncertain predictions and robust detection of out-of-distribution data.
Well-calibrated Model Uncertainty with Temperature Scaling for Dropout Variational Inference
Oct 01, 2019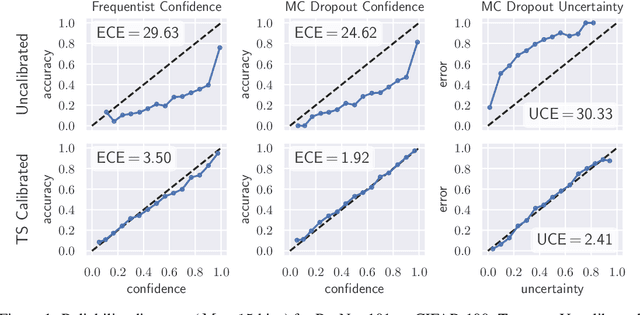
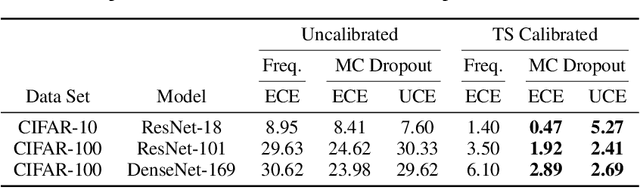
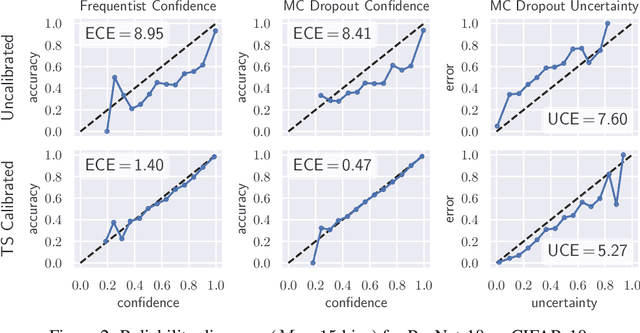
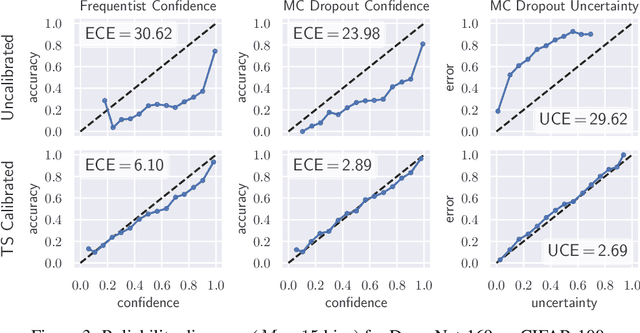
In this paper, well-calibrated model uncertainty is obtained by using temperature scaling together with Monte Carlo dropout as approximation to Bayesian inference. The proposed approach can easily be derived from frequentist temperature scaling and yields well-calibrated model uncertainty as well as softmax likelihood.
Uncertainty Quantification in Computer-Aided Diagnosis: Make Your Model say "I don't know" for Ambiguous Cases
Aug 02, 2019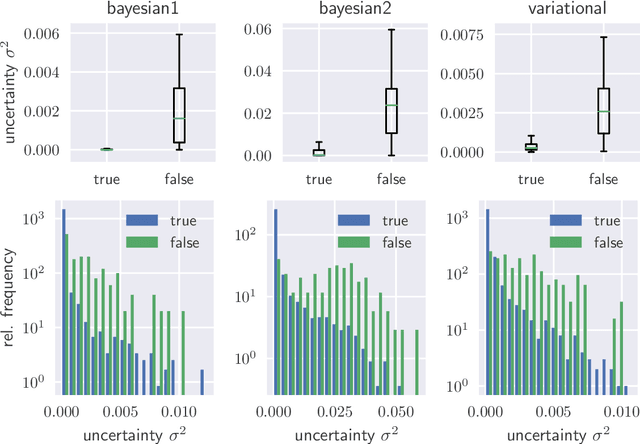

We evaluate two different methods for the integration of prediction uncertainty into diagnostic image classifiers to increase patient safety in deep learning. In the first method, Monte Carlo sampling is applied with dropout at test time to get a posterior distribution of the class labels (Bayesian ResNet). The second method extends ResNet to a probabilistic approach by predicting the parameters of the posterior distribution and sampling the final result from it (Variational ResNet).The variance of the posterior is used as metric for uncertainty.Both methods are trained on a data set of optical coherence tomography scans showing four different retinal conditions. Our results shown that cases in which the classifier predicts incorrectly correlate with a higher uncertainty. Mean uncertainty of incorrectly diagnosed cases was between 4.6 and 8.1 times higher than mean uncertainty of correctly diagnosed cases. Modeling of the prediction uncertainty in computer-aided diagnosis with deep learning yields more reliable results and is anticipated to increase patient safety.
Deformable Medical Image Registration Using a Randomly-Initialized CNN as Regularization Prior
Aug 02, 2019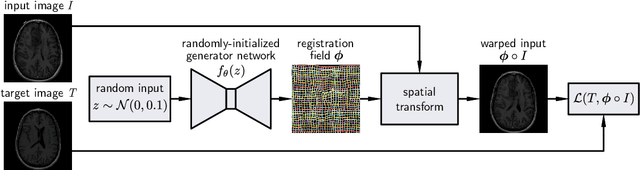
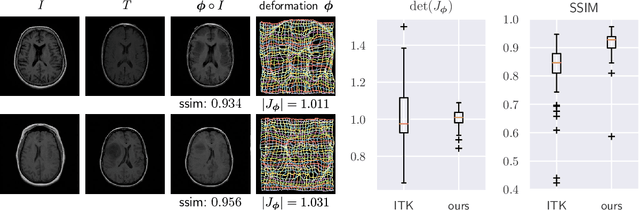
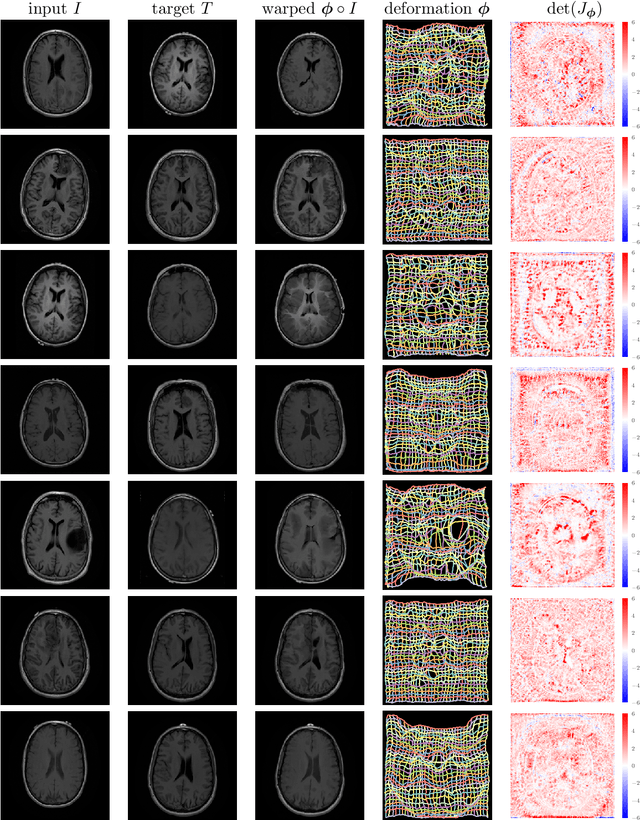
We present deformable unsupervised medical image registration using a randomly-initialized deep convolutional neural network (CNN) as regularization prior. Conventional registration methods predict a transformation by minimizing dissimilarities between an image pair. The minimization is usually regularized with manually engineered priors, which limits the potential of the registration. By learning transformation priors from a large dataset, CNNs have achieved great success in deformable registration. However, learned methods are restricted to domain-specific data and the required amounts of medical data are difficult to obtain. Our approach uses the idea of deep image priors to combine convolutional networks with conventional registration methods based on manually engineered priors. The proposed method is applied to brain MRI scans. We show that our approach registers image pairs with state-of-the-art accuracy by providing dense, pixel-wise correspondence maps. It does not rely on prior training and is therefore not limited to a specific image domain.
Semantic denoising autoencoders for retinal optical coherence tomography
Mar 23, 2019
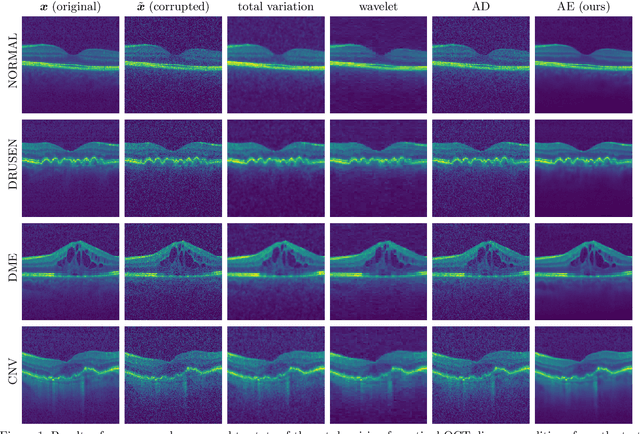
Noise in speckle-prone optical coherence tomography tends to obfuscate important details necessary for medical diagnosis. In this paper, a denoising approach that preserves disease characteristics on retinal optical coherence tomography images in ophthalmology is presented. By combining a deep convolutional autoencoder with a priorly trained ResNet image classifier as regularizer, the perceptibility of delicate details is encouraged and only information-less background noise is filtered out. With our approach, higher peak signal-to-noise ratios with $ \mathrm{PSNR} = 31.2\,\mathrm{dB} $ and higher classification accuracy of $\mathrm{ACC} = 85.0\,\%$ can be achieved for denoised images compared to state-of-the-art denoising with $ \mathrm{PSNR} = 29.4\,\mathrm{dB} $ or $\mathrm{ACC} = 70.3\,\%$, depending on the method. It is shown that regularized autoencoders are capable of denoising retinal OCT images without blurring details of diseases.
Retinal OCT disease classification with variational autoencoder regularization
Mar 23, 2019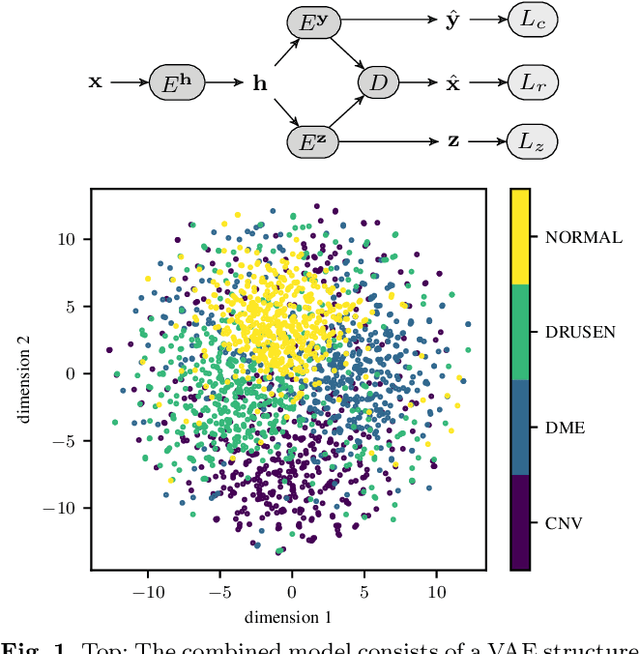

According to the World Health Organization, 285 million people worldwide live with visual impairment. The most commonly used imaging technique for diagnosis in ophthalmology is optical coherence tomography (OCT). However, analysis of retinal OCT requires trained ophthalmologists and time, making a comprehensive early diagnosis unlikely. A recent study established a diagnostic tool based on convolutional neural networks (CNN), which was trained on a large database of retinal OCT images. The performance of the tool in classifying retinal conditions was on par to that of trained medical experts. However, the training of these networks is based on an enormous amount of labeled data, which is expensive and difficult to obtain. Therefore, this paper describes a method based on variational autoencoder regularization that improves classification performance when using a limited amount of labeled data. This work uses a two-path CNN model combining a classification network with an autoencoder (AE) for regularization. The key idea behind this is to prevent overfitting when using a limited training dataset size with small number of patients. Results show superior classification performance compared to a pre-trained and fully fine-tuned baseline ResNet-34. Clustering of the latent space in relation to the disease class is distinct. Neural networks for disease classification on OCTs can benefit from regularization using variational autoencoders when trained with limited amount of patient data. Especially in the medical imaging domain, data annotated by experts is expensive to obtain.