 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Automatic Vocal Mode Classification
Jan 26, 2026The Complete Vocal Technique (CVT) is a school of singing developed in the past decades by Cathrin Sadolin et al.. CVT groups the use of the voice into so called vocal modes, namely Neutral, Curbing, Overdrive and Edge. Knowledge of the desired vocal mode can be helpful for singing students. Automatic classification of vocal modes can thus be important for technology-assisted singing teaching. Previously, automatic classification of vocal modes has been attempted without major success, potentially due to a lack of data. Therefore, we recorded a novel vocal mode dataset consisting of sustained vowels recorded from four singers, three of which professional singers with more than five years of CVT-experience. The dataset covers the entire vocal range of the subjects, totaling 3,752 unique samples. By using four microphones, thereby offering a natural data augmentation, the dataset consists of more than 13,000 samples combined. An annotation was created using three CVT-experienced annotators, each providing an individual annotation. The merged annotation as well as the three individual annotations come with the published dataset. Additionally, we provide some baseline classification results. The best balanced accuracy across a 5-fold cross validation of 81.3\,\% was achieved with a ResNet18. The dataset can be downloaded under https://zenodo.org/records/14276415.
Pruning-aware Loss Functions for STOI-Optimized Pruned Recurrent Autoencoders for the Compression of the Stimulation Patterns of Cochlear Implants at Zero Delay
Feb 04, 2025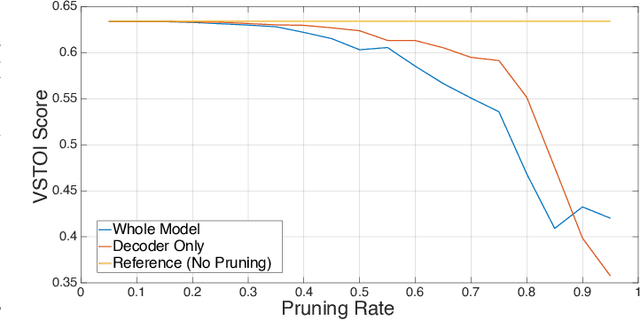
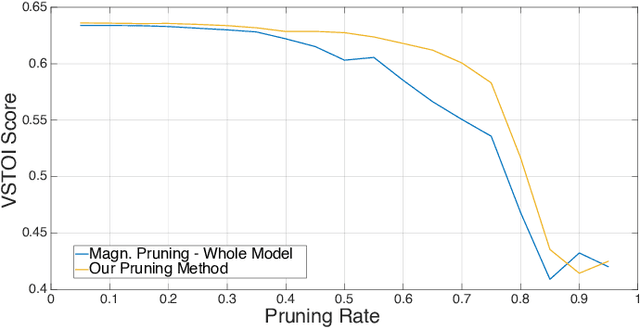
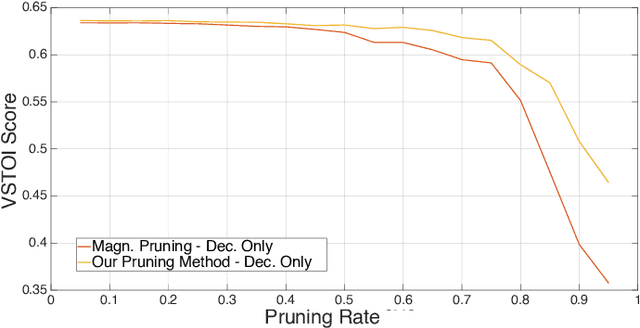
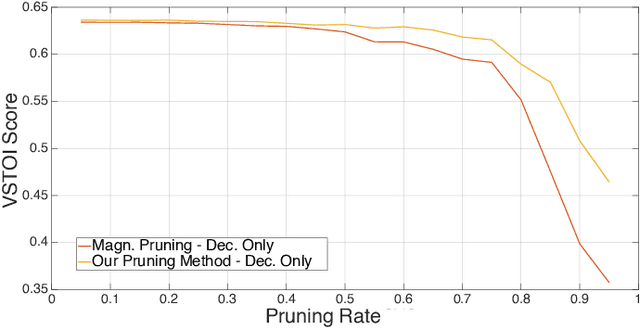
Cochlear implants (CIs) are surgically implanted hearing devices, which allow to restore a sense of hearing in people suffering from profound hearing loss. Wireless streaming of audio from external devices to CI signal processors has become common place. Specialized compression based on the stimulation patterns of a CI by deep recurrent autoencoders can decrease the power consumption in such a wireless streaming application through bit-rate reduction at zero latency. While previous research achieved considerable bit-rate reductions, model sizes were ignored, which can be of crucial importance in hearing-aids due to their limited computational resources. This work investigates maximizing objective speech intelligibility of the coded stimulation patterns of deep recurrent autoencoders while minimizing model size. For this purpose, a pruning-aware loss is proposed, which captures the impact of pruning during training. This training with a pruning-aware loss is compared to conventional magnitude-informed pruning and is found to yield considerable improvements in objective intelligibility, especially at higher pruning rates. After fine-tuning, little to no degradation of objective intelligibility is observed up to a pruning rate of about 55\,\%. The proposed pruning-aware loss yields substantial gains in objective speech intelligibility scores after pruning compared to the magnitude-informed baseline for pruning rates above 45\,\%.
* Preprint of Asilomar 2024 Paper