 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoTIF: Learning Motion Trajectories with Local Implicit Neural Functions for Continuous Space-Time Video Super-Resolution
Jul 16, 2023



This work addresses continuous space-time video super-resolution (C-STVSR) that aims to up-scale an input video both spatially and temporally by any scaling factors. One key challenge of C-STVSR is to propagate information temporally among the input video frames. To this end, we introduce a space-time local implicit neural function. It has the striking feature of learning forward motion for a continuum of pixels. We motivate the use of forward motion from the perspective of learning individual motion trajectories, as opposed to learning a mixture of motion trajectories with backward motion. To ease motion interpolation, we encode sparsely sampled forward motion extracted from the input video as the contextual input. Along with a reliability-aware splatting and decoding scheme, our framework, termed MoTIF, achieves the state-of-the-art performance on C-STVSR. The source code of MoTIF is available at https://github.com/sichun233746/MoTIF.
GSVNet: Guided Spatially-Varying Convolution for Fast Semantic Segmentation on Video
Mar 16, 2021
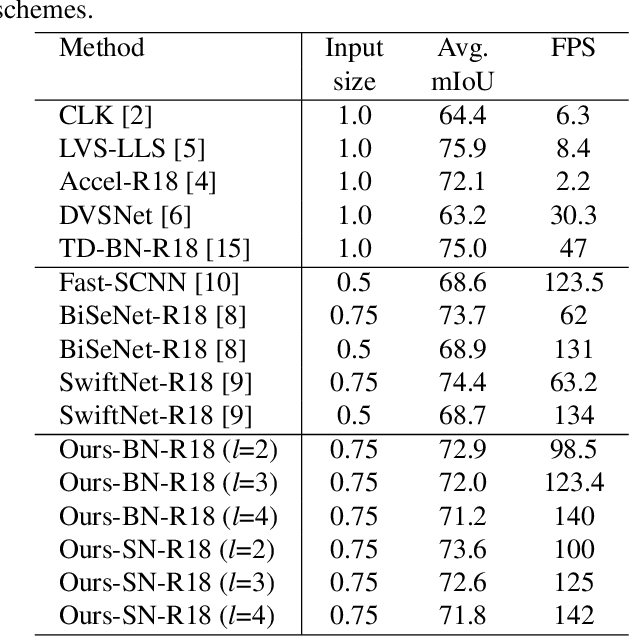

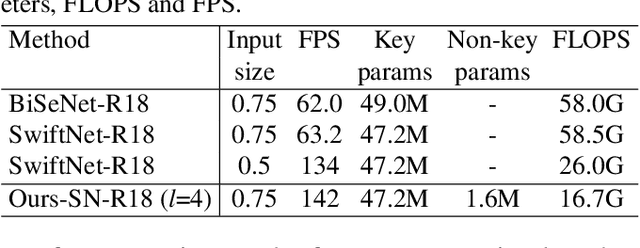
This paper addresses fast semantic segmentation on video.Video segmentation often calls for real-time, or even fasterthan real-time, processing. One common recipe for conserving computation arising from feature extraction is to propagate features of few selected keyframes. However, recent advances in fast image segmentation make these solutions less attractive. To leverage fast image segmentation for furthering video segmentation, we propose a simple yet efficient propagation framework. Specifically, we perform lightweight flow estimation in 1/8-downscaled image space for temporal warping in segmentation outpace space. Moreover, we introduce a guided spatially-varying convolution for fusing segmentations derived from the previous and current frames, to mitigate propagation error and enable lightweight feature extraction on non-keyframes. Experimental results on Cityscapes and CamVid show that our scheme achieves the state-of-the-art accuracy-throughput trade-off on video segmentation.