 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Verification for Speech Deepfakes
May 20, 2025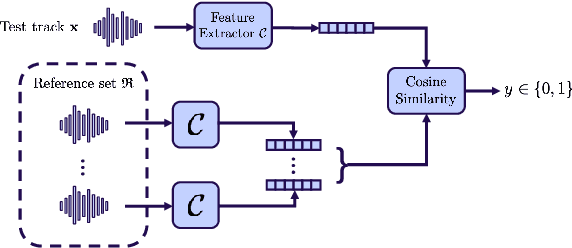
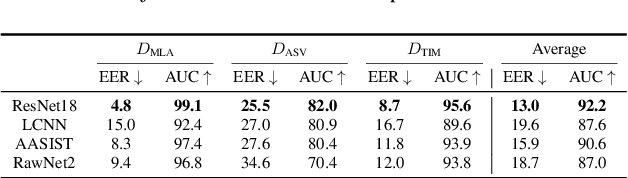
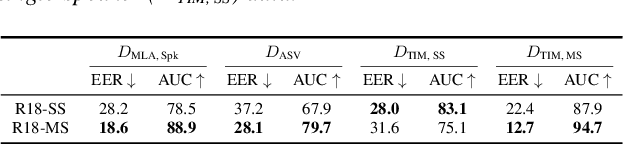
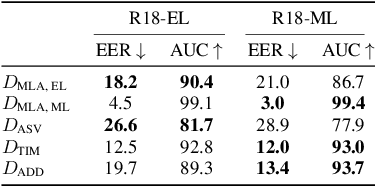
With the proliferation of speech deepfake generators, it becomes crucial not only to assess the authenticity of synthetic audio but also to trace its origin. While source attribution models attempt to address this challenge, they often struggle in open-set conditions against unseen generators. In this paper, we introduce the source verification task, which, inspired by speaker verification, determines whether a test track was produced using the same model as a set of reference signals. Our approach leverages embeddings from a classifier trained for source attribution, computing distance scores between tracks to assess whether they originate from the same source. We evaluate multiple models across diverse scenarios, analyzing the impact of speaker diversity, language mismatch, and post-processing operations. This work provides the first exploration of source verification, highlighting its potential and vulnerabilities, and offers insights for real-world forensic applications.
Comparative Analysis of ASR Methods for Speech Deepfake Detection
Nov 26, 2024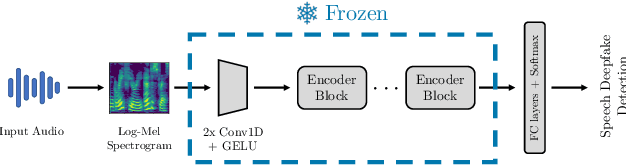
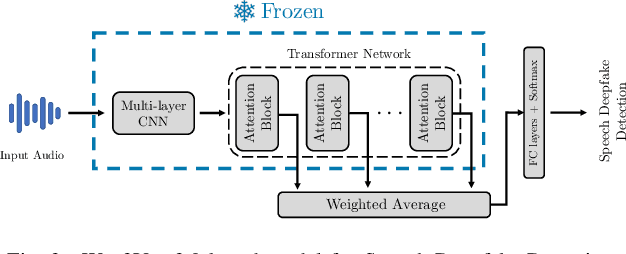
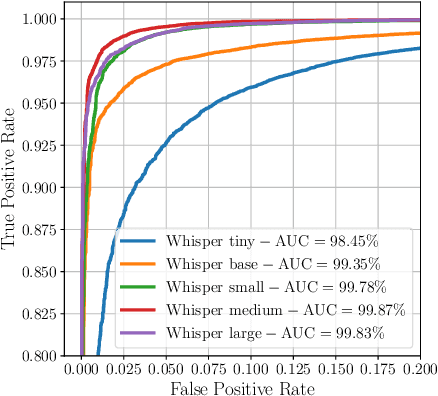
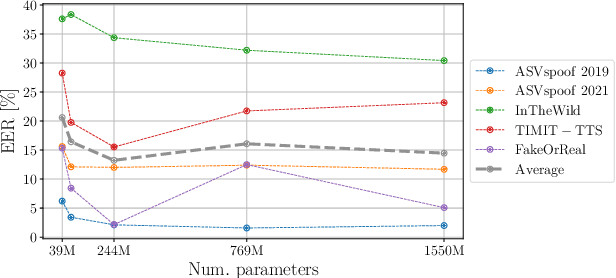
Recent techniques for speech deepfake detection often rely on pre-trained self-supervised models. These systems, initially developed for Automatic Speech Recognition (ASR), have proved their ability to offer a meaningful representation of speech signals, which can benefit various tasks, including deepfake detection. In this context, pre-trained models serve as feature extractors and are used to extract embeddings from input speech, which are then fed to a binary speech deepfake detector. The remarkable accuracy achieved through this approach underscores a potential relationship between ASR and speech deepfake detection. However, this connection is not yet entirely clear, and we do not know whether improved performance in ASR corresponds to higher speech deepfake detection capabilities. In this paper, we address this question through a systematic analysis. We consider two different pre-trained self-supervised ASR models, Whisper and Wav2Vec 2.0, and adapt them for the speech deepfake detection task. These models have been released in multiple versions, with increasing number of parameters and enhanced ASR performance. We investigate whether performance improvements in ASR correlate with improvements in speech deepfake detection. Our results provide insights into the relationship between these two tasks and offer valuable guidance for the development of more effective speech deepfake detectors.
Freeze and Learn: Continual Learning with Selective Freezing for Speech Deepfake Detection
Sep 26, 2024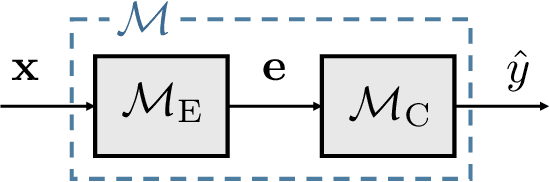
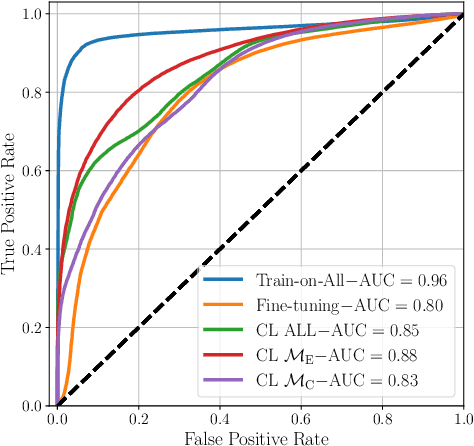
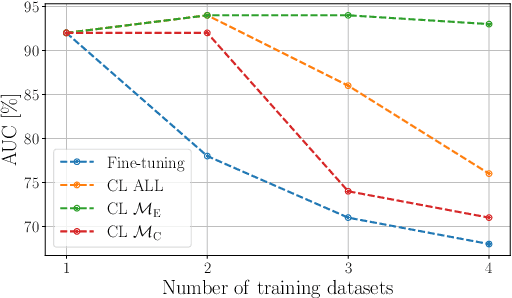
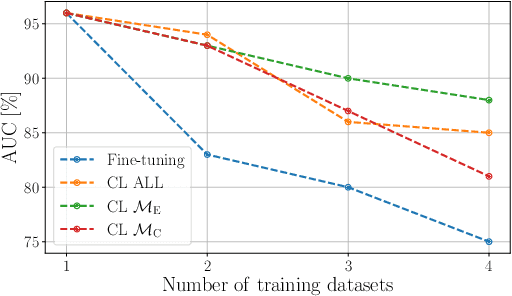
In speech deepfake detection, one of the critical aspects is developing detectors able to generalize on unseen data and distinguish fake signals across different datasets. Common approaches to this challenge involve incorporating diverse data into the training process or fine-tuning models on unseen datasets. However, these solutions can be computationally demanding and may lead to the loss of knowledge acquired from previously learned data. Continual learning techniques offer a potential solution to this problem, allowing the models to learn from unseen data without losing what they have already learned. Still, the optimal way to apply these algorithms for speech deepfake detection remains unclear, and we do not know which is the best way to apply these algorithms to the developed models. In this paper we address this aspect and investigate whether, when retraining a speech deepfake detector, it is more effective to apply continual learning across the entire model or to update only some of its layers while freezing others. Our findings, validated across multiple models, indicate that the most effective approach among the analyzed ones is to update only the weights of the initial layers, which are responsible for processing the input features of the detector.
Leveraging Mixture of Experts for Improved Speech Deepfake Detection
Sep 24, 2024
Speech deepfakes pose a significant threat to personal security and content authenticity. Several detectors have been proposed in the literature, and one of the primary challenges these systems have to face is the generalization over unseen data to identify fake signals across a wide range of datasets. In this paper, we introduce a novel approach for enhancing speech deepfake detection performance using a Mixture of Experts architecture. The Mixture of Experts framework is well-suited for the speech deepfake detection task due to its ability to specialize in different input types and handle data variability efficiently. This approach offers superior generalization and adaptability to unseen data compared to traditional single models or ensemble methods. Additionally, its modular structure supports scalable updates, making it more flexible in managing the evolving complexity of deepfake techniques while maintaining high detection accuracy. We propose an efficient, lightweight gating mechanism to dynamically assign expert weights for each input, optimizing detection performance. Experimental results across multiple datasets demonstrate the effectiveness and potential of our proposed approach.
Analyzing the Impact of Splicing Artifacts in Partially Fake Speech Signals
Aug 25, 2024



Speech deepfake detection has recently gained significant attention within the multimedia forensics community. Related issues have also been explored, such as the identification of partially fake signals, i.e., tracks that include both real and fake speech segments. However, generating high-quality spliced audio is not as straightforward as it may appear. Spliced signals are typically created through basic signal concatenation. This process could introduce noticeable artifacts that can make the generated data easier to detect. We analyze spliced audio tracks resulting from signal concatenation, investigate their artifacts and assess whether such artifacts introduce any bias in existing datasets. Our findings reveal that by analyzing splicing artifacts, we can achieve a detection EER of 6.16% and 7.36% on PartialSpoof and HAD datasets, respectively, without needing to train any detector. These results underscore the complexities of generating reliable spliced audio data and lead to discussions that can help improve future research in this area.
Localization of Synthetic Manipulations in Western Blot Images
Aug 25, 2024



Recent breakthroughs in deep learning and generative systems have significantly fostered the creation of synthetic media, as well as the local alteration of real content via the insertion of highly realistic synthetic manipulations. Local image manipulation, in particular, poses serious challenges to the integrity of digital content and societal trust. This problem is not only confined to multimedia data, but also extends to biological images included in scientific publications, like images depicting Western blots. In this work, we address the task of localizing synthetic manipulations in Western blot images. To discriminate between pristine and synthetic pixels of an analyzed image, we propose a synthetic detector that operates on small patches extracted from the image. We aggregate patch contributions to estimate a tampering heatmap, highlighting synthetic pixels out of pristine ones. Our methodology proves effective when tested over two manipulated Western blot image datasets, one altered automatically and the other manually by exploiting advanced AI-based image manipulation tools that are unknown at our training stage. We also explore the robustness of our method over an external dataset of other scientific images depicting different semantics, manipulated through unseen generation techniques.