 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeze and Learn: Continual Learning with Selective Freezing for Speech Deepfake Detection
Paper and Code
Sep 26, 2024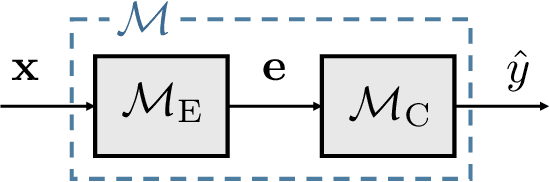
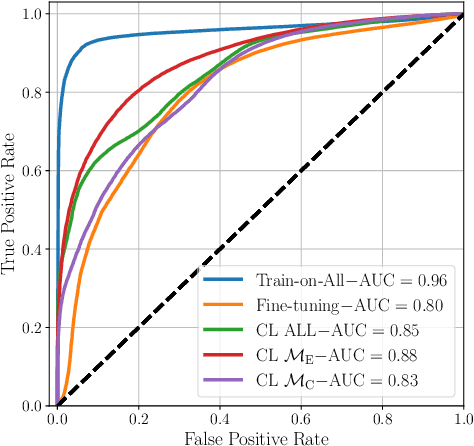
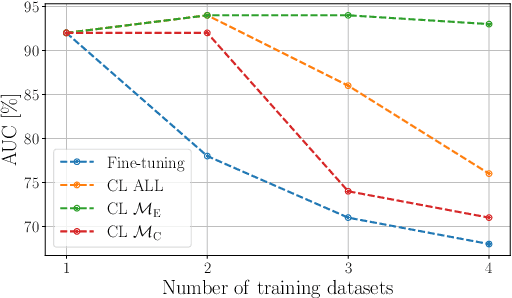
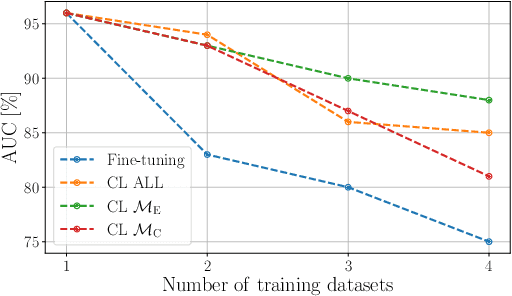
In speech deepfake detection, one of the critical aspects is developing detectors able to generalize on unseen data and distinguish fake signals across different datasets. Common approaches to this challenge involve incorporating diverse data into the training process or fine-tuning models on unseen datasets. However, these solutions can be computationally demanding and may lead to the loss of knowledge acquired from previously learned data. Continual learning techniques offer a potential solution to this problem, allowing the models to learn from unseen data without losing what they have already learned. Still, the optimal way to apply these algorithms for speech deepfake detection remains unclear, and we do not know which is the best way to apply these algorithms to the developed models. In this paper we address this aspect and investigate whether, when retraining a speech deepfake detector, it is more effective to apply continual learning across the entire model or to update only some of its layers while freezing others. Our findings, validated across multiple models, indicate that the most effective approach among the analyzed ones is to update only the weights of the initial layers, which are responsible for processing the input features of the detector.