 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of ASR Methods for Speech Deepfake Detection
Paper and Code
Nov 26, 2024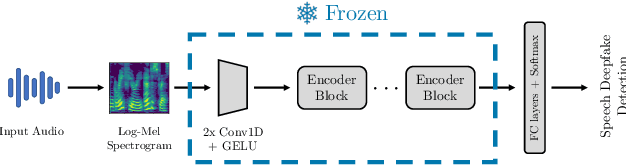
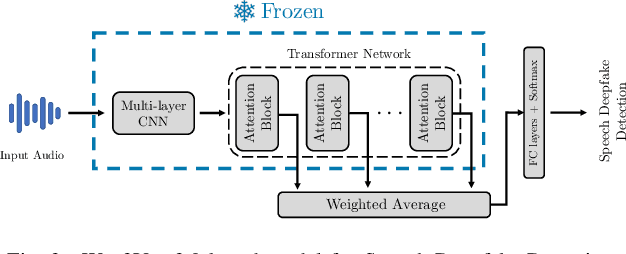
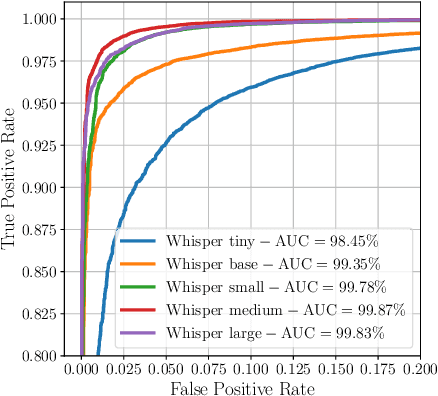
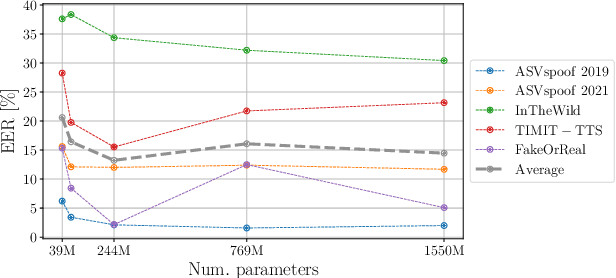
Recent techniques for speech deepfake detection often rely on pre-trained self-supervised models. These systems, initially developed for Automatic Speech Recognition (ASR), have proved their ability to offer a meaningful representation of speech signals, which can benefit various tasks, including deepfake detection. In this context, pre-trained models serve as feature extractors and are used to extract embeddings from input speech, which are then fed to a binary speech deepfake detector. The remarkable accuracy achieved through this approach underscores a potential relationship between ASR and speech deepfake detection. However, this connection is not yet entirely clear, and we do not know whether improved performance in ASR corresponds to higher speech deepfake detection capabilities. In this paper, we address this question through a systematic analysis. We consider two different pre-trained self-supervised ASR models, Whisper and Wav2Vec 2.0, and adapt them for the speech deepfake detection task. These models have been released in multiple versions, with increasing number of parameters and enhanced ASR performance. We investigate whether performance improvements in ASR correlate with improvements in speech deepfake detection. Our results provide insights into the relationship between these two tasks and offer valuable guidance for the development of more effective speech deepfake detectors.