 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeatMat: Simulation of City Material Impact on Urban Heat Island Effect
Jan 30, 2026The Urban Heat Island (UHI) effect, defined as a significant increase in temperature in urban environments compared to surrounding areas, is difficult to study in real cities using sensor data (satellites or in-situ stations) due to their coarse spatial and temporal resolution. Among the factors contributing to this effect are the properties of urban materials, which differ from those in rural areas. To analyze their individual impact and to test new material configurations, a high-resolution simulation at the city scale is required. Estimating the current materials used in a city, including those on building facades, is also challenging. We propose HeatMat, an approach to analyze at high resolution the individual impact of urban materials on the UHI effect in a real city, relying only on open data. We estimate building materials using street-view images and a pre-trained vision-language model (VLM) to supplement existing OpenStreetMap data, which describes the 2D geometry and features of buildings. We further encode this information into a set of 2D maps that represent the city's vertical structure and material characteristics. These maps serve as inputs for our 2.5D simulator, which models coupled heat transfers and enables random-access surface temperature estimation at multiple resolutions, reaching an x20 speedup compared to an equivalent simulation in 3D.
Scaling-Up the Pretraining of the Earth Observation Foundation Model PhilEO to the MajorTOM Dataset
Jun 17, 2025



Today, Earth Observation (EO) satellites generate massive volumes of data, with the Copernicus Sentinel-2 constellation alone producing approximately 1.6TB per day. To fully exploit this information, it is essential to pretrain EO Foundation Models (FMs) on large unlabeled datasets, enabling efficient fine-tuning for several different downstream tasks with minimal labeled data. In this work, we present the scaling-up of our recently proposed EO Foundation Model, PhilEO Geo-Aware U-Net, on the unlabeled 23TB dataset MajorTOM, which covers the vast majority of the Earth's surface, as well as on the specialized subset FastTOM 2TB that does not include oceans and ice. We develop and study various PhilEO model variants with different numbers of parameters and architectures. Finally, we fine-tune the models on the PhilEO Bench for road density estimation, building density pixel-wise regression, and land cover semantic segmentation, and we evaluate the performance. Our results demonstrate that for all n-shots for road density regression, the PhilEO 44M MajorTOM 23TB model outperforms PhilEO Globe 0.5TB 44M. We also show that for most n-shots for road density estimation and building density regression, PhilEO 200M FastTOM outperforms all the other models. The effectiveness of both dataset and model scaling is validated using the PhilEO Bench. We also study the impact of architecture scaling, transitioning from U-Net Convolutional Neural Networks (CNN) to Vision Transformers (ViT).
TerraMind: Large-Scale Generative Multimodality for Earth Observation
Apr 15, 2025



We present TerraMind, the first any-to-any generative, multimodal foundation model for Earth observation (EO). Unlike other multimodal models, TerraMind is pretrained on dual-scale representations combining both token-level and pixel-level data across modalities. On a token level, TerraMind encodes high-level contextual information to learn cross-modal relationships, while on a pixel level, TerraMind leverages fine-grained representations to capture critical spatial nuances. We pretrained TerraMind on nine geospatial modalities of a global, large-scale dataset. In this paper, we demonstrate that (i) TerraMind's dual-scale early fusion approach unlocks a range of zero-shot and few-shot applications for Earth observation, (ii) TerraMind introduces "Thinking-in-Modalities" (TiM) -- the capability of generating additional artificial data during finetuning and inference to improve the model output -- and (iii) TerraMind achieves beyond state-of-the-art performance in community-standard benchmarks for EO like PANGAEA. The pretraining dataset, the model weights, and our code is open-sourced under a permissive license.
CARE: Confidence-Aware Regression Estimation of building density fine-tuning EO Foundation Models
Feb 19, 2025



Performing accurate confidence quantification and assessment is important for deep neural networks to predict their failures, improve their performance and enhance their capabilities in real-world applications, for their practical deployment in real life. For pixel-wise regression tasks, confidence quantification and assessment has not been well addressed in the literature, in contrast to classification tasks like semantic segmentation. The softmax output layer is not used in deep neural networks that solve pixel-wise regression problems. In this paper, to address these problems, we develop, train and evaluate the proposed model Confidence-Aware Regression Estimation (CARE). Our model CARE computes and assigns confidence to regression output results. We focus on solving regression problems as downstream tasks of an AI Foundation Model for Earth Observation (EO). We evaluate the proposed model CARE and experimental results on data from the Copernicus Sentinel-2 satellite constellation for estimating the density of buildings show that the proposed method can be successfully applied to regression problems. We also show that our approach outperforms other methods.
Building Age Estimation: A New Multi-Modal Benchmark Dataset and Community Challenge
Feb 19, 2025Estimating the construction year of buildings is of great importance for sustainability. Sustainable buildings minimize energy consumption and are a key part of responsible and sustainable urban planning and development to effectively combat climate change. By using Artificial Intelligence (AI) and recently proposed Transformer models, we are able to estimate the construction epoch of buildings from a multi-modal dataset. In this paper, we introduce a new benchmark multi-modal dataset, i.e. the Map your City Dataset (MyCD), containing top-view Very High Resolution (VHR) images, Earth Observation (EO) multi-spectral data from the Copernicus Sentinel-2 satellite constellation, and street-view images in many different cities in Europe, co-localized with respect to the building under study and labelled with the construction epoch. We assess EO generalization performance on new/ previously unseen cities that have been held-out from training and appear only during inference. In this work, we present the community-based data challenge we organized based on MyCD. The ESA AI4EO Challenge MapYourCity was opened in 2024 for 4 months. Here, we present the Top-4 performing models, and the main evaluation results. During inference, the performance of the models using both all three input modalities and only the two top-view modalities, i.e. without the street-view images, is examined. The evaluation results show that the models are effective and can achieve good performance on this difficult real-world task of estimating the age of buildings, even on previously unseen cities, as well as even using only the two top-view modalities (i.e. VHR and Sentinel-2) during inference.
CAS: Confidence Assessments of classification algorithms for Semantic segmentation of EO data
Jun 26, 2024



Confidence assessments of semantic segmentation algorithms in remote sensing are important. It is a desirable property of models to a priori know if they produce an incorrect output. Evaluations of the confidence assigned to the estimates of models for the task of classification in Earth Observation (EO) are crucial as they can be used to achieve improved semantic segmentation performance and prevent high error rates during inference and deployment. The model we develop, the Confidence Assessments of classification algorithms for Semantic segmentation (CAS) model, performs confidence evaluations at both the segment and pixel levels, and outputs both labels and confidence. The outcome of this work has important applications. The main application is the evaluation of EO Foundation Models on semantic segmentation downstream tasks, in particular land cover classification using satellite Copernicus Sentinel-2 data. The evaluation shows that the proposed model is effective and outperforms other alternative baseline models.
Evaluating and Benchmarking Foundation Models for Earth Observation and Geospatial AI
Jun 26, 2024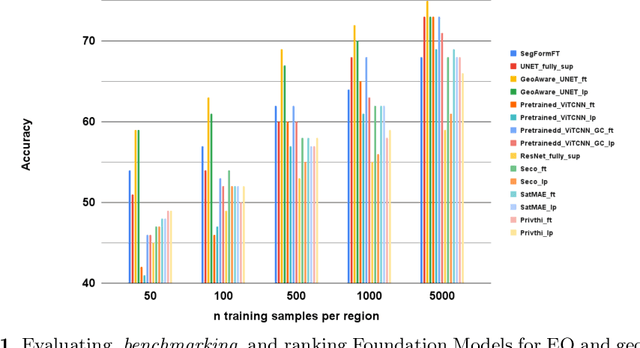
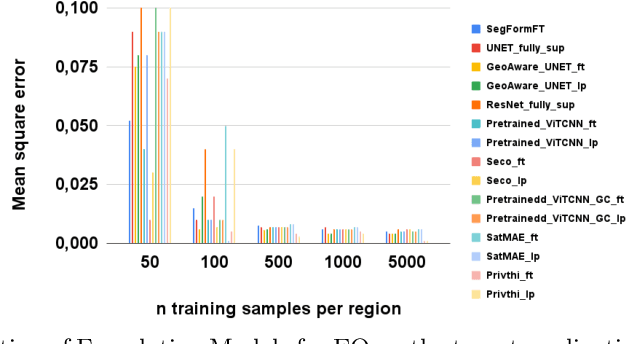
When we are primarily interested in solving several problems jointly with a given prescribed high performance accuracy for each target application, then Foundation Models should for most cases be used rather than problem-specific models. We focus on the specific Computer Vision application of Foundation Models for Earth Observation (EO) and geospatial AI. These models can solve important problems we are tackling, including for example land cover classification, crop type mapping, flood segmentation, building density estimation, and road regression segmentation. In this paper, we show that for a limited number of labelled data, Foundation Models achieve improved performance compared to problem-specific models. In this work, we also present our proposed evaluation benchmark for Foundation Models for EO. Benchmarking the generalization performance of Foundation Models is important as it has become difficult to standardize a fair comparison across the many different models that have been proposed recently. We present the results using our evaluation benchmark for EO Foundation Models and show that Foundation Models are label efficient in the downstream tasks and help us solve problems we are tackling in EO and remote sensing.
Learning from Unlabelled Data with Transformers: Domain Adaptation for Semantic Segmentation of High Resolution Aerial Images
Apr 17, 2024Data from satellites or aerial vehicles are most of the times unlabelled. Annotating such data accurately is difficult, requires expertise, and is costly in terms of time. Even if Earth Observation (EO) data were correctly labelled, labels might change over time. Learning from unlabelled data within a semi-supervised learning framework for segmentation of aerial images is challenging. In this paper, we develop a new model for semantic segmentation of unlabelled images, the Non-annotated Earth Observation Semantic Segmentation (NEOS) model. NEOS performs domain adaptation as the target domain does not have ground truth semantic segmentation masks. The distribution inconsistencies between the target and source domains are due to differences in acquisition scenes, environment conditions, sensors, and times. Our model aligns the learned representations of the different domains to make them coincide. The evaluation results show that NEOS is successful and outperforms other models for semantic segmentation of unlabelled data.
A Semantic Segmentation-guided Approach for Ground-to-Aerial Image Matching
Apr 17, 2024Nowadays the accurate geo-localization of ground-view images has an important role across domains as diverse as journalism, forensics analysis, transports, and Earth Observation. This work addresses the problem of matching a query ground-view image with the corresponding satellite image without GPS data. This is done by comparing the features from a ground-view image and a satellite one, innovatively leveraging the corresponding latter's segmentation mask through a three-stream Siamese-like network. The proposed method, Semantic Align Net (SAN), focuses on limited Field-of-View (FoV) and ground panorama images (images with a FoV of 360{\deg}). The novelty lies in the fusion of satellite images in combination with their semantic segmentation masks, aimed at ensuring that the model can extract useful features and focus on the significant parts of the images. This work shows how SAN through semantic analysis of images improves the performance on the unlabelled CVUSA dataset for all the tested FoVs.
PhilEO Bench: Evaluating Geo-Spatial Foundation Models
Jan 15, 2024Massive amounts of unlabelled data are captured by Earth Observation (EO) satellites, with the Sentinel-2 constellation generating 1.6 TB of data daily. This makes Remote Sensing a data-rich domain well suited to Machine Learning (ML) solutions. However, a bottleneck in applying ML models to EO is the lack of annotated data as annotation is a labour-intensive and costly process. As a result, research in this domain has focused on Self-Supervised Learning and Foundation Model approaches. This paper addresses the need to evaluate different Foundation Models on a fair and uniform benchmark by introducing the PhilEO Bench, a novel evaluation framework for EO Foundation Models. The framework comprises of a testbed and a novel 400 GB Sentinel-2 dataset containing labels for three downstream tasks, building density estimation, road segmentation, and land cover classification. We present experiments using our framework evaluating different Foundation Models, including Prithvi and SatMAE, at multiple n-shots and convergence rates.