 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Benchmarking Foundation Models for Earth Observation and Geospatial AI
Jun 26, 2024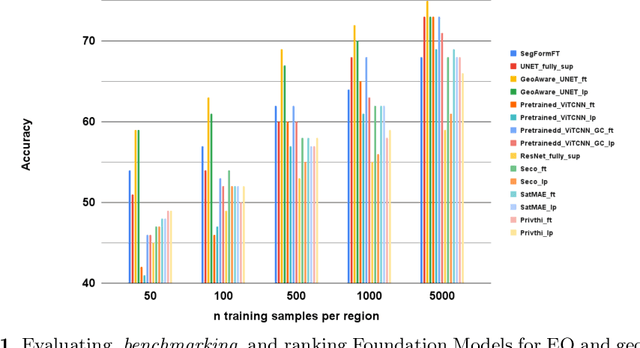
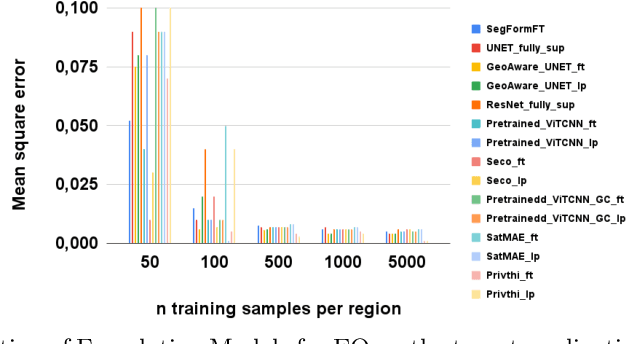
When we are primarily interested in solving several problems jointly with a given prescribed high performance accuracy for each target application, then Foundation Models should for most cases be used rather than problem-specific models. We focus on the specific Computer Vision application of Foundation Models for Earth Observation (EO) and geospatial AI. These models can solve important problems we are tackling, including for example land cover classification, crop type mapping, flood segmentation, building density estimation, and road regression segmentation. In this paper, we show that for a limited number of labelled data, Foundation Models achieve improved performance compared to problem-specific models. In this work, we also present our proposed evaluation benchmark for Foundation Models for EO. Benchmarking the generalization performance of Foundation Models is important as it has become difficult to standardize a fair comparison across the many different models that have been proposed recently. We present the results using our evaluation benchmark for EO Foundation Models and show that Foundation Models are label efficient in the downstream tasks and help us solve problems we are tackling in EO and remote sensing.
PhilEO Bench: Evaluating Geo-Spatial Foundation Models
Jan 15, 2024



Massive amounts of unlabelled data are captured by Earth Observation (EO) satellites, with the Sentinel-2 constellation generating 1.6 TB of data daily. This makes Remote Sensing a data-rich domain well suited to Machine Learning (ML) solutions. However, a bottleneck in applying ML models to EO is the lack of annotated data as annotation is a labour-intensive and costly process. As a result, research in this domain has focused on Self-Supervised Learning and Foundation Model approaches. This paper addresses the need to evaluate different Foundation Models on a fair and uniform benchmark by introducing the PhilEO Bench, a novel evaluation framework for EO Foundation Models. The framework comprises of a testbed and a novel 400 GB Sentinel-2 dataset containing labels for three downstream tasks, building density estimation, road segmentation, and land cover classification. We present experiments using our framework evaluating different Foundation Models, including Prithvi and SatMAE, at multiple n-shots and convergence rates.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.