 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling-Up the Pretraining of the Earth Observation Foundation Model PhilEO to the MajorTOM Dataset
Jun 17, 2025



Today, Earth Observation (EO) satellites generate massive volumes of data, with the Copernicus Sentinel-2 constellation alone producing approximately 1.6TB per day. To fully exploit this information, it is essential to pretrain EO Foundation Models (FMs) on large unlabeled datasets, enabling efficient fine-tuning for several different downstream tasks with minimal labeled data. In this work, we present the scaling-up of our recently proposed EO Foundation Model, PhilEO Geo-Aware U-Net, on the unlabeled 23TB dataset MajorTOM, which covers the vast majority of the Earth's surface, as well as on the specialized subset FastTOM 2TB that does not include oceans and ice. We develop and study various PhilEO model variants with different numbers of parameters and architectures. Finally, we fine-tune the models on the PhilEO Bench for road density estimation, building density pixel-wise regression, and land cover semantic segmentation, and we evaluate the performance. Our results demonstrate that for all n-shots for road density regression, the PhilEO 44M MajorTOM 23TB model outperforms PhilEO Globe 0.5TB 44M. We also show that for most n-shots for road density estimation and building density regression, PhilEO 200M FastTOM outperforms all the other models. The effectiveness of both dataset and model scaling is validated using the PhilEO Bench. We also study the impact of architecture scaling, transitioning from U-Net Convolutional Neural Networks (CNN) to Vision Transformers (ViT).
Evaluating and Benchmarking Foundation Models for Earth Observation and Geospatial AI
Jun 26, 2024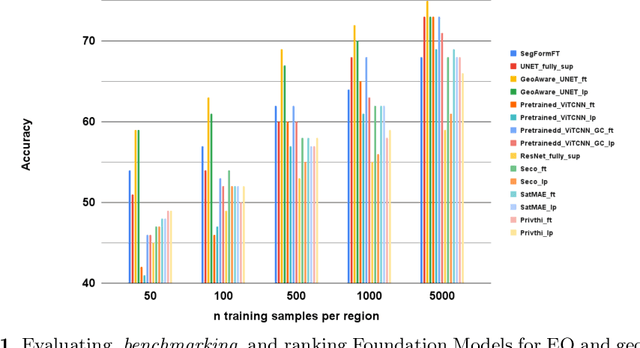
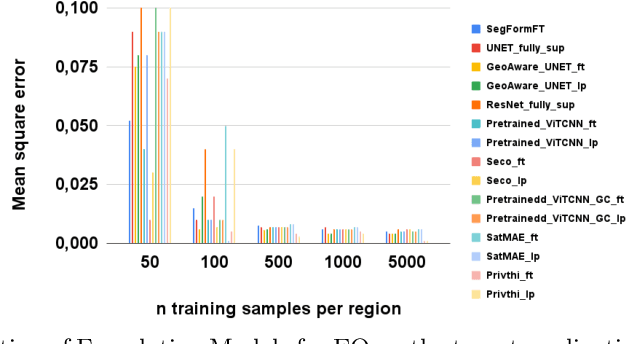
When we are primarily interested in solving several problems jointly with a given prescribed high performance accuracy for each target application, then Foundation Models should for most cases be used rather than problem-specific models. We focus on the specific Computer Vision application of Foundation Models for Earth Observation (EO) and geospatial AI. These models can solve important problems we are tackling, including for example land cover classification, crop type mapping, flood segmentation, building density estimation, and road regression segmentation. In this paper, we show that for a limited number of labelled data, Foundation Models achieve improved performance compared to problem-specific models. In this work, we also present our proposed evaluation benchmark for Foundation Models for EO. Benchmarking the generalization performance of Foundation Models is important as it has become difficult to standardize a fair comparison across the many different models that have been proposed recently. We present the results using our evaluation benchmark for EO Foundation Models and show that Foundation Models are label efficient in the downstream tasks and help us solve problems we are tackling in EO and remote sensing.
PhilEO Bench: Evaluating Geo-Spatial Foundation Models
Jan 15, 2024Massive amounts of unlabelled data are captured by Earth Observation (EO) satellites, with the Sentinel-2 constellation generating 1.6 TB of data daily. This makes Remote Sensing a data-rich domain well suited to Machine Learning (ML) solutions. However, a bottleneck in applying ML models to EO is the lack of annotated data as annotation is a labour-intensive and costly process. As a result, research in this domain has focused on Self-Supervised Learning and Foundation Model approaches. This paper addresses the need to evaluate different Foundation Models on a fair and uniform benchmark by introducing the PhilEO Bench, a novel evaluation framework for EO Foundation Models. The framework comprises of a testbed and a novel 400 GB Sentinel-2 dataset containing labels for three downstream tasks, building density estimation, road segmentation, and land cover classification. We present experiments using our framework evaluating different Foundation Models, including Prithvi and SatMAE, at multiple n-shots and convergence rates.