 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Award Winning Research Papers at Publication Time
Paper and Code
Jun 18, 2024


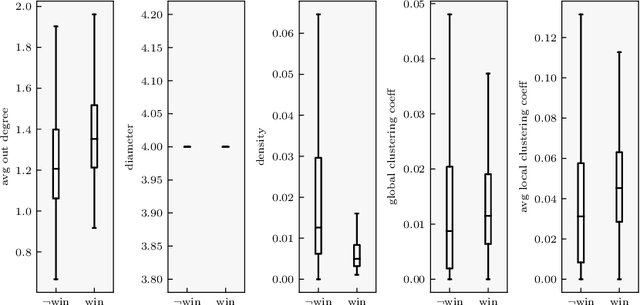
In recent years, many studies have been focusing on predicting the scientific impact of research papers. Most of these predictions are based on citations count or rely on features obtainable only from already published papers. In this study, we predict the likelihood for a research paper of winning an award only relying on information available at publication time. For each paper, we build the citation subgraph induced from its bibliography. We initially consider some features of this subgraph, such as the density and the global clustering coefficient, to make our prediction. Then, we mix this information with textual features, extracted from the abstract and the title, to obtain a more accurate final prediction. We made our experiments considering the ArnetMiner citation graph, while the ground truth on award-winning papers has been obtained from a collection of best paper awards from 32 computer science conferences. In our experiment, we obtained an encouraging F1 score of 0.694. Remarkably, The high recall and the low false negatives rate, show how the model performs very well at identifying papers that will not win an award. This behavior can help researchers in getting a first evaluation of their work at publication time. Lastly, we made some first experiments on interpretability. Our results highlight some interesting patterns both in topological and textual features.