 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
A Survey on Approximate Edge AI for Energy Efficient Autonomous Driving Services
Apr 13, 2023Autonomous driving services rely heavily on sensors such as cameras, LiDAR, radar, and communication modules. A common practice of processing the sensed data is using a high-performance computing unit placed inside the vehicle, which deploys AI models and algorithms to act as the brain or administrator of the vehicle. The vehicular data generated from average hours of driving can be up to 20 Terabytes depending on the data rate and specification of the sensors. Given the scale and fast growth of services for autonomous driving, it is essential to improve the overall energy and environmental efficiency, especially in the trend towards vehicular electrification (e.g., battery-powered). Although the areas have seen significant advancements in sensor technologies, wireless communications, computing and AI/ML algorithms, the challenge still exists in how to apply and integrate those technology innovations to achieve energy efficiency. This survey reviews and compares the connected vehicular applications, vehicular communications, approximation and Edge AI techniques. The focus is on energy efficiency by covering newly proposed approximation and enabling frameworks. To the best of our knowledge, this survey is the first to review the latest approximate Edge AI frameworks and publicly available datasets in energy-efficient autonomous driving. The insights and vision from this survey can be beneficial for the collaborative driving service development on low-power and memory-constrained systems and also for the energy optimization of autonomous vehicles.
P4L: Privacy Preserving Peer-to-Peer Learning for Infrastructureless Setups
Feb 26, 2023



Distributed (or Federated) learning enables users to train machine learning models on their very own devices, while they share only the gradients of their models usually in a differentially private way (utility loss). Although such a strategy provides better privacy guarantees than the traditional centralized approach, it requires users to blindly trust a centralized infrastructure that may also become a bottleneck with the increasing number of users. In this paper, we design and implement P4L: a privacy preserving peer-to-peer learning system for users to participate in an asynchronous, collaborative learning scheme without requiring any sort of infrastructure or relying on differential privacy. Our design uses strong cryptographic primitives to preserve both the confidentiality and utility of the shared gradients, a set of peer-to-peer mechanisms for fault tolerance and user churn, proximity and cross device communications. Extensive simulations under different network settings and ML scenarios for three real-life datasets show that P4L provides competitive performance to baselines, while it is resilient to different poisoning attacks. We implement P4L and experimental results show that the performance overhead and power consumption is minimal (less than 3mAh of discharge).
Scheduling Inference Workloads on Distributed Edge Clusters with Reinforcement Learning
Jan 31, 2023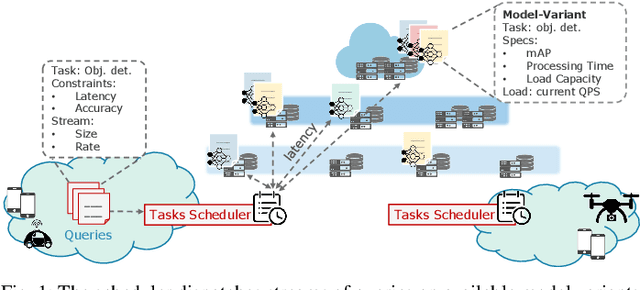
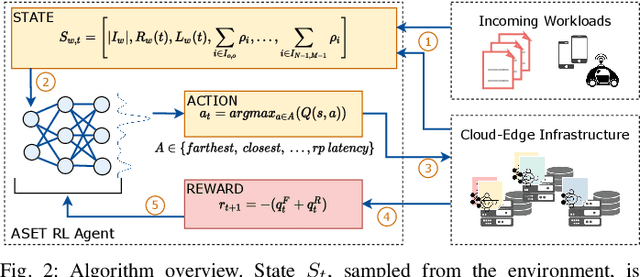
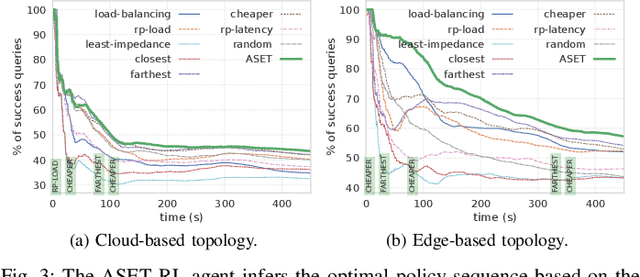
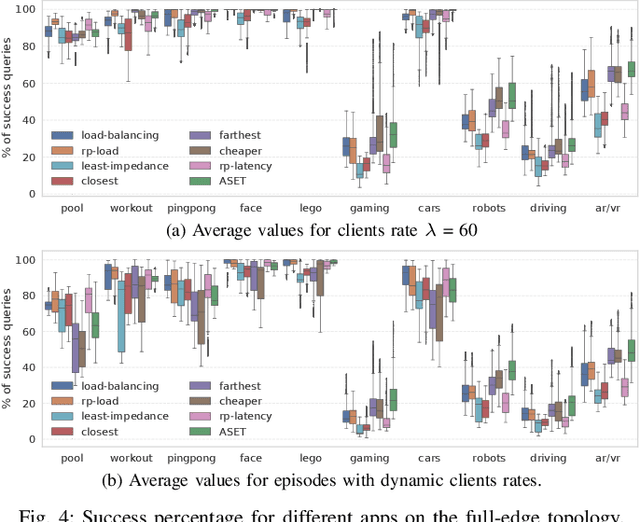
Many real-time applications (e.g., Augmented/Virtual Reality, cognitive assistance) rely on Deep Neural Networks (DNNs) to process inference tasks. Edge computing is considered a key infrastructure to deploy such applications, as moving computation close to the data sources enables us to meet stringent latency and throughput requirements. However, the constrained nature of edge networks poses several additional challenges to the management of inference workloads: edge clusters can not provide unlimited processing power to DNN models, and often a trade-off between network and processing time should be considered when it comes to end-to-end delay requirements. In this paper, we focus on the problem of scheduling inference queries on DNN models in edge networks at short timescales (i.e., few milliseconds). By means of simulations, we analyze several policies in the realistic network settings and workloads of a large ISP, highlighting the need for a dynamic scheduling policy that can adapt to network conditions and workloads. We therefore design ASET, a Reinforcement Learning based scheduling algorithm able to adapt its decisions according to the system conditions. Our results show that ASET effectively provides the best performance compared to static policies when scheduling over a distributed pool of edge resources.
Hierarchical Federated Learning with Privacy
Jun 10, 2022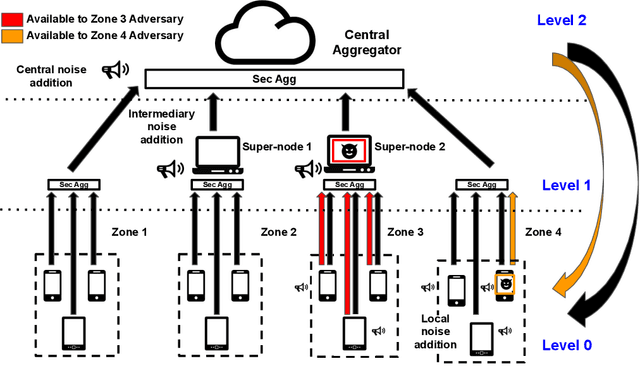
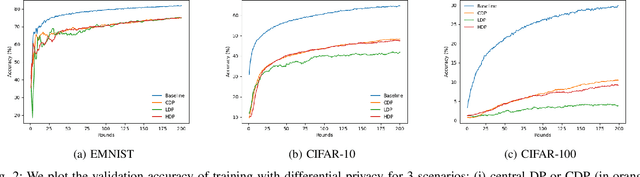
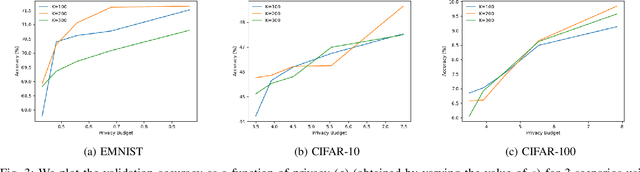

Federated learning (FL), where data remains at the federated clients, and where only gradient updates are shared with a central aggregator, was assumed to be private. Recent work demonstrates that adversaries with gradient-level access can mount successful inference and reconstruction attacks. In such settings, differentially private (DP) learning is known to provide resilience. However, approaches used in the status quo (\ie central and local DP) introduce disparate utility vs. privacy trade-offs. In this work, we take the first step towards mitigating such trade-offs through {\em hierarchical FL (HFL)}. We demonstrate that by the introduction of a new intermediary level where calibrated DP noise can be added, better privacy vs. utility trade-offs can be obtained; we term this {\em hierarchical DP (HDP)}. Our experiments with 3 different datasets (commonly used as benchmarks for FL) suggest that HDP produces models as accurate as those obtained using central DP, where noise is added at a central aggregator. Such an approach also provides comparable benefit against inference adversaries as in the local DP case, where noise is added at the federated clients.
PPFL: Privacy-preserving Federated Learning with Trusted Execution Environments
Apr 29, 2021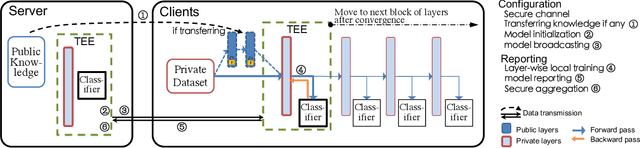

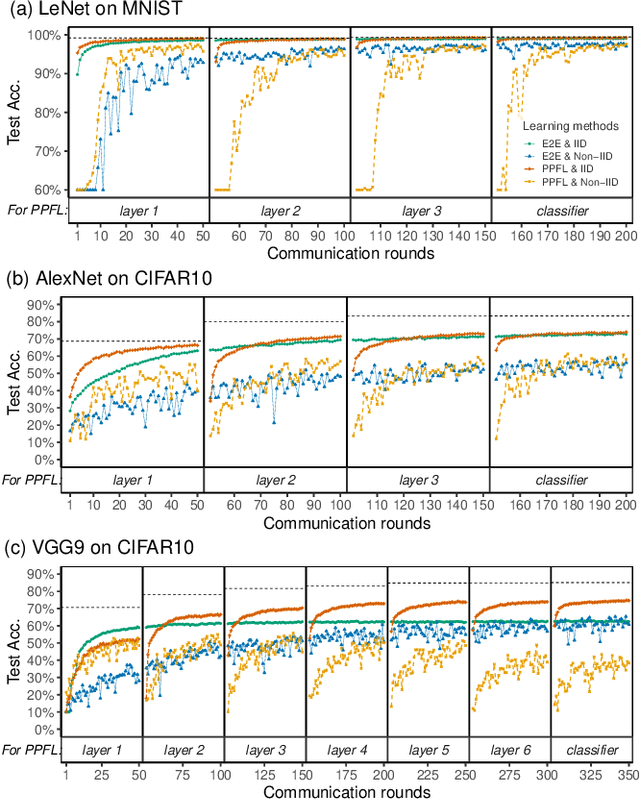
We propose and implement a Privacy-preserving Federated Learning (PPFL) framework for mobile systems to limit privacy leakages in federated learning. Leveraging the widespread presence of Trusted Execution Environments (TEEs) in high-end and mobile devices, we utilize TEEs on clients for local training, and on servers for secure aggregation, so that model/gradient updates are hidden from adversaries. Challenged by the limited memory size of current TEEs, we leverage greedy layer-wise training to train each model's layer inside the trusted area until its convergence. The performance evaluation of our implementation shows that PPFL can significantly improve privacy while incurring small system overheads at the client-side. In particular, PPFL can successfully defend the trained model against data reconstruction, property inference, and membership inference attacks. Furthermore, it can achieve comparable model utility with fewer communication rounds (0.54x) and a similar amount of network traffic (1.002x) compared to the standard federated learning of a complete model. This is achieved while only introducing up to ~15% CPU time, ~18% memory usage, and ~21% energy consumption overhead in PPFL's client-side.
FLaaS: Federated Learning as a Service
Nov 18, 2020
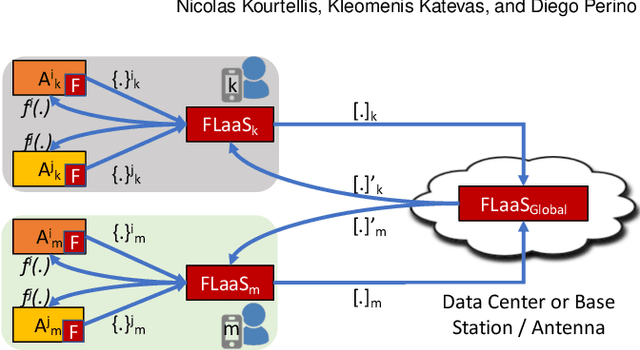
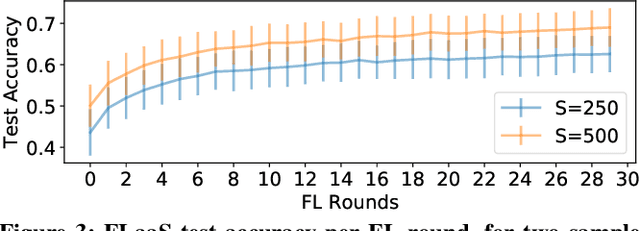
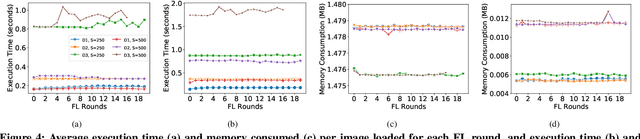
Federated Learning (FL) is emerging as a promising technology to build machine learning models in a decentralized, privacy-preserving fashion. Indeed, FL enables local training on user devices, avoiding user data to be transferred to centralized servers, and can be enhanced with differential privacy mechanisms. Although FL has been recently deployed in real systems, the possibility of collaborative modeling across different 3rd-party applications has not yet been explored. In this paper, we tackle this problem and present Federated Learning as a Service (FLaaS), a system enabling different scenarios of 3rd-party application collaborative model building and addressing the consequent challenges of permission and privacy management, usability, and hierarchical model training. FLaaS can be deployed in different operational environments. As a proof of concept, we implement it on a mobile phone setting and discuss practical implications of results on simulated and real devices with respect to on-device training CPU cost, memory footprint and power consumed per FL model round. Therefore, we demonstrate FLaaS's feasibility in building unique or joint FL models across applications for image object detection in a few hours, across 100 devices.
* 7 pages, 4 figures, 7 subfigures, 34 references