 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Characterizing and Limiting Information Exposure in DNN Layers
Paper and Code

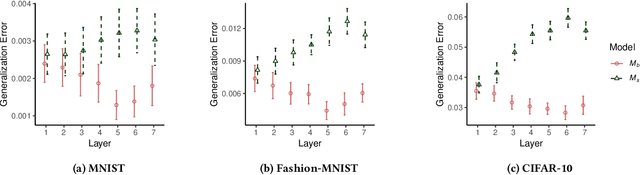
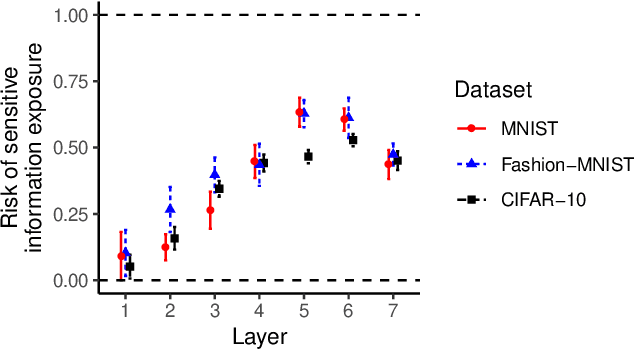
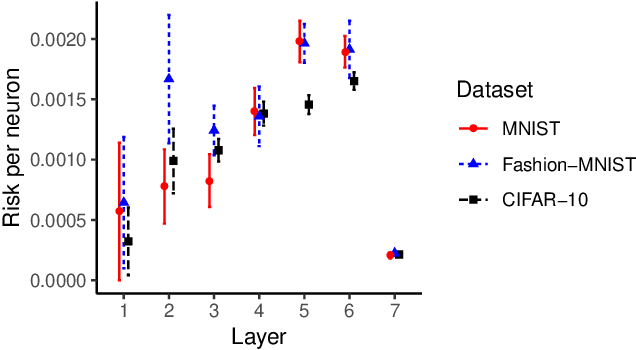
Pre-trained Deep Neural Network (DNN) models are increasingly used in smartphones and other user devices to enable prediction services, leading to potential disclosures of (sensitive) information from training data captured inside these models. Based on the concept of generalization error, we propose a framework to measure the amount of sensitive information memorized in each layer of a DNN. Our results show that, when considered individually, the last layers encode a larger amount of information from the training data compared to the first layers. We find that, while the neuron of convolutional layers can expose more (sensitive) information than that of fully connected layers, the same DNN architecture trained with different datasets has similar exposure per layer. We evaluate an architecture to protect the most sensitive layers within the memory limits of Trusted Execution Environment (TEE) against potential white-box membership inference attacks without the significant computational overhead.