 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluid Batching: Exit-Aware Preemptive Serving of Early-Exit Neural Networks on Edge NPUs
Paper and Code
Sep 27, 2022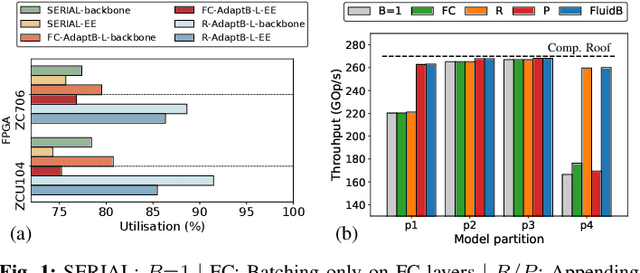
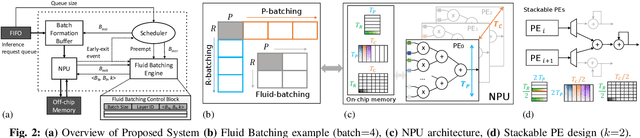
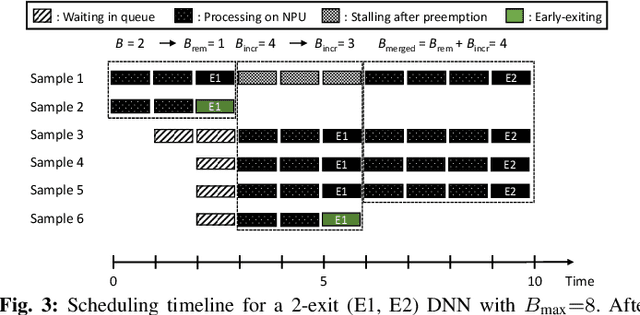
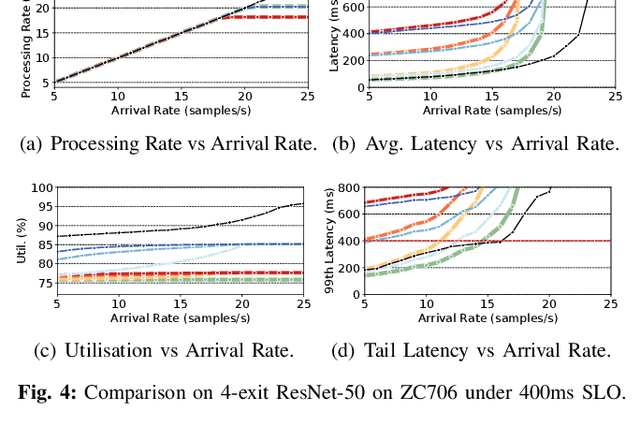
With deep neural networks (DNNs) emerging as the backbone in a multitude of computer vision tasks, their adoption in real-world consumer applications broadens continuously. Given the abundance and omnipresence of smart devices, "smart ecosystems" are being formed where sensing happens simultaneously rather than standalone. This is shifting the on-device inference paradigm towards deploying centralised neural processing units (NPUs) at the edge, where multiple devices (e.g. in smart homes or autonomous vehicles) can stream their data for processing with dynamic rates. While this provides enhanced potential for input batching, naive solutions can lead to subpar performance and quality of experience, especially under spiking loads. At the same time, the deployment of dynamic DNNs, comprising stochastic computation graphs (e.g. early-exit (EE) models), introduces a new dimension of dynamic behaviour in such systems. In this work, we propose a novel early-exit-aware scheduling algorithm that allows sample preemption at run time, to account for the dynamicity introduced both by the arrival and early-exiting processes. At the same time, we introduce two novel dimensions to the design space of the NPU hardware architecture, namely Fluid Batching and Stackable Processing Elements, that enable run-time adaptability to different batch sizes and significantly improve the NPU utilisation even at small batch sizes. Our evaluation shows that our system achieves an average 1.97x and 6.7x improvement over state-of-the-art DNN streaming systems in terms of average latency and tail latency SLO satisfaction, respectively.