 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewards as Labels: Revisiting RLVR from a Classification Perspective
Feb 05, 2026Reinforcement Learning with Verifiable Rewards has recently advanced the capabilities of Large Language Models in complex reasoning tasks by providing explicit rule-based supervision. Among RLVR methods, GRPO and its variants have achieved strong empirical performance. Despite their success, we identify that they suffer from Gradient Misassignment in Positives and Gradient Domination in Negatives, which lead to inefficient and suboptimal policy updates. To address these issues, we propose Rewards as Labels (REAL), a novel framework that revisits verifiable rewards as categorical labels rather than scalar weights, thereby reformulating policy optimization as a classification problem. Building on this, we further introduce anchor logits to enhance policy learning. Our analysis reveals that REAL induces a monotonic and bounded gradient weighting, enabling balanced gradient allocation across rollouts and effectively mitigating the identified mismatches. Extensive experiments on mathematical reasoning benchmarks show that REAL improves training stability and consistently outperforms GRPO and strong variants such as DAPO. On the 1.5B model, REAL improves average Pass@1 over DAPO by 6.7%. These gains further scale to 7B model, REAL continues to outperform DAPO and GSPO by 6.2% and 1.7%, respectively. Notably, even with a vanilla binary cross-entropy, REAL remains stable and exceeds DAPO by 4.5% on average.
Deep Time-series Forecasting Needs Kernelized Moment Balancing
Jan 31, 2026Deep time-series forecasting can be formulated as a distribution balancing problem aimed at aligning the distribution of the forecasts and ground truths. According to Imbens' criterion, true distribution balance requires matching the first moments with respect to any balancing function. We demonstrate that existing objectives fail to meet this criterion, as they enforce moment matching only for one or two predefined balancing functions, thus failing to achieve full distribution balance. To address this limitation, we propose direct forecasting with kernelized moment balancing (KMB-DF). Unlike existing objectives, KMB-DF adaptively selects the most informative balancing functions from a reproducing kernel hilbert space (RKHS) to enforce sufficient distribution balancing. We derive a tractable and differentiable objective that enables efficient estimation from empirical samples and seamless integration into gradient-based training pipelines. Extensive experiments across multiple models and datasets show that KMB-DF consistently improves forecasting accuracy and achieves state-of-the-art performance. Code is available at https://anonymous.4open.science/r/KMB-DF-403C.
UniPACT: A Multimodal Framework for Prognostic Question Answering on Raw ECG and Structured EHR
Jan 25, 2026Accurate clinical prognosis requires synthesizing structured Electronic Health Records (EHRs) with real-time physiological signals like the Electrocardiogram (ECG). Large Language Models (LLMs) offer a powerful reasoning engine for this task but struggle to natively process these heterogeneous, non-textual data types. To address this, we propose UniPACT (Unified Prognostic Question Answering for Clinical Time-series), a unified framework for prognostic question answering that bridges this modality gap. UniPACT's core contribution is a structured prompting mechanism that converts numerical EHR data into semantically rich text. This textualized patient context is then fused with representations learned directly from raw ECG waveforms, enabling an LLM to reason over both modalities holistically. We evaluate UniPACT on the comprehensive MDS-ED benchmark, it achieves a state-of-the-art mean AUROC of 89.37% across a diverse set of prognostic tasks including diagnosis, deterioration, ICU admission, and mortality, outperforming specialized baselines. Further analysis demonstrates that our multimodal, multi-task approach is critical for performance and provides robustness in missing data scenarios.
TourPlanner: A Competitive Consensus Framework with Constraint-Gated Reinforcement Learning for Travel Planning
Jan 08, 2026Travel planning is a sophisticated decision-making process that requires synthesizing multifaceted information to construct itineraries. However, existing travel planning approaches face several challenges: (1) Pruning candidate points of interest (POIs) while maintaining a high recall rate; (2) A single reasoning path restricts the exploration capability within the feasible solution space for travel planning; (3) Simultaneously optimizing hard constraints and soft constraints remains a significant difficulty. To address these challenges, we propose TourPlanner, a comprehensive framework featuring multi-path reasoning and constraint-gated reinforcement learning. Specifically, we first introduce a Personalized Recall and Spatial Optimization (PReSO) workflow to construct spatially-aware candidate POIs' set. Subsequently, we propose Competitive consensus Chain-of-Thought (CCoT), a multi-path reasoning paradigm that improves the ability of exploring the feasible solution space. To further refine the plan, we integrate a sigmoid-based gating mechanism into the reinforcement learning stage, which dynamically prioritizes soft-constraint satisfaction only after hard constraints are met. Experimental results on travel planning benchmarks demonstrate that TourPlanner achieves state-of-the-art performance, significantly surpassing existing methods in both feasibility and user-preference alignment.
Agent2World: Learning to Generate Symbolic World Models via Adaptive Multi-Agent Feedback
Dec 26, 2025Symbolic world models (e.g., PDDL domains or executable simulators) are central to model-based planning, but training LLMs to generate such world models is limited by the lack of large-scale verifiable supervision. Current approaches rely primarily on static validation methods that fail to catch behavior-level errors arising from interactive execution. In this paper, we propose Agent2World, a tool-augmented multi-agent framework that achieves strong inference-time world-model generation and also serves as a data engine for supervised fine-tuning, by grounding generation in multi-agent feedback. Agent2World follows a three-stage pipeline: (i) A Deep Researcher agent performs knowledge synthesis by web searching to address specification gaps; (ii) A Model Developer agent implements executable world models; And (iii) a specialized Testing Team conducts adaptive unit testing and simulation-based validation. Agent2World demonstrates superior inference-time performance across three benchmarks spanning both Planning Domain Definition Language (PDDL) and executable code representations, achieving consistent state-of-the-art results. Beyond inference, Testing Team serves as an interactive environment for the Model Developer, providing behavior-aware adaptive feedback that yields multi-turn training trajectories. The model fine-tuned on these trajectories substantially improves world-model generation, yielding an average relative gain of 30.95% over the same model before training. Project page: https://agent2world.github.io.
LoopTool: Closing the Data-Training Loop for Robust LLM Tool Calls
Nov 18, 2025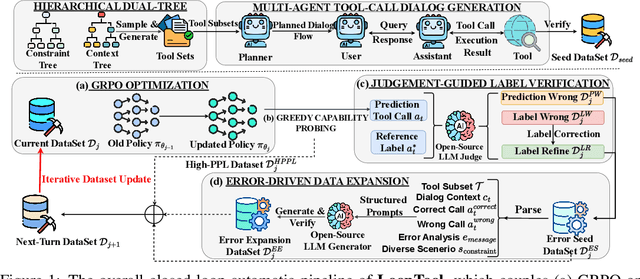
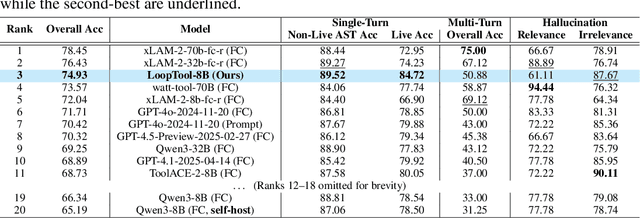
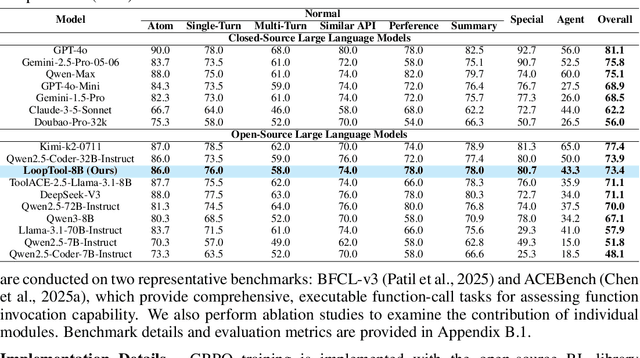
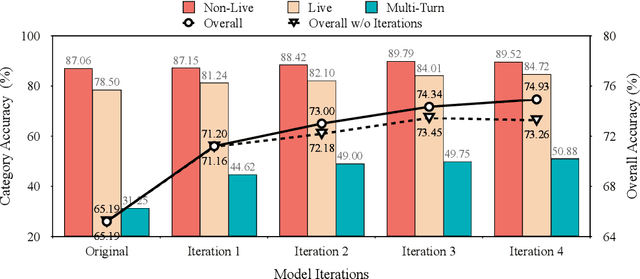
Augmenting Large Language Models (LLMs) with external tools enables them to execute complex, multi-step tasks. However, tool learning is hampered by the static synthetic data pipelines where data generation and model training are executed as two separate, non-interactive processes. This approach fails to adaptively focus on a model's specific weaknesses and allows noisy labels to persist, degrading training efficiency. We introduce LoopTool, a fully automated, model-aware data evolution framework that closes this loop by tightly integrating data synthesis and model training. LoopTool iteratively refines both the data and the model through three synergistic modules: (1) Greedy Capability Probing (GCP) diagnoses the model's mastered and failed capabilities; (2) Judgement-Guided Label Verification (JGLV) uses an open-source judge model to find and correct annotation errors, progressively purifying the dataset; and (3) Error-Driven Data Expansion (EDDE) generates new, challenging samples based on identified failures. This closed-loop process operates within a cost-effective, open-source ecosystem, eliminating dependence on expensive closed-source APIs. Experiments show that our 8B model trained with LoopTool significantly surpasses its 32B data generator and achieves new state-of-the-art results on the BFCL-v3 and ACEBench benchmarks for its scale. Our work demonstrates that closed-loop, self-refining data pipelines can dramatically enhance the tool-use capabilities of LLMs.
Fints: Efficient Inference-Time Personalization for LLMs with Fine-Grained Instance-Tailored Steering
Oct 31, 2025The rapid evolution of large language models (LLMs) has intensified the demand for effective personalization techniques that can adapt model behavior to individual user preferences. Despite the non-parametric methods utilizing the in-context learning ability of LLMs, recent parametric adaptation methods, including personalized parameter-efficient fine-tuning and reward modeling emerge. However, these methods face limitations in handling dynamic user patterns and high data sparsity scenarios, due to low adaptability and data efficiency. To address these challenges, we propose a fine-grained and instance-tailored steering framework that dynamically generates sample-level interference vectors from user data and injects them into the model's forward pass for personalized adaptation. Our approach introduces two key technical innovations: a fine-grained steering component that captures nuanced signals by hooking activations from attention and MLP layers, and an input-aware aggregation module that synthesizes these signals into contextually relevant enhancements. The method demonstrates high flexibility and data efficiency, excelling in fast-changing distribution and high data sparsity scenarios. In addition, the proposed method is orthogonal to existing methods and operates as a plug-in component compatible with different personalization techniques. Extensive experiments across diverse scenarios--including short-to-long text generation, and web function calling--validate the effectiveness and compatibility of our approach. Results show that our method significantly enhances personalization performance in fast-shifting environments while maintaining robustness across varying interaction modes and context lengths. Implementation is available at https://github.com/KounianhuaDu/Fints.
DeepAgent: A General Reasoning Agent with Scalable Toolsets
Oct 24, 2025Large reasoning models have demonstrated strong problem-solving abilities, yet real-world tasks often require external tools and long-horizon interactions. Existing agent frameworks typically follow predefined workflows, which limit autonomous and global task completion. In this paper, we introduce DeepAgent, an end-to-end deep reasoning agent that performs autonomous thinking, tool discovery, and action execution within a single, coherent reasoning process. To address the challenges of long-horizon interactions, particularly the context length explosion from multiple tool calls and the accumulation of interaction history, we introduce an autonomous memory folding mechanism that compresses past interactions into structured episodic, working, and tool memories, reducing error accumulation while preserving critical information. To teach general-purpose tool use efficiently and stably, we develop an end-to-end reinforcement learning strategy, namely ToolPO, that leverages LLM-simulated APIs and applies tool-call advantage attribution to assign fine-grained credit to the tool invocation tokens. Extensive experiments on eight benchmarks, including general tool-use tasks (ToolBench, API-Bank, TMDB, Spotify, ToolHop) and downstream applications (ALFWorld, WebShop, GAIA, HLE), demonstrate that DeepAgent consistently outperforms baselines across both labeled-tool and open-set tool retrieval scenarios. This work takes a step toward more general and capable agents for real-world applications. The code and demo are available at https://github.com/RUC-NLPIR/DeepAgent.
Interpretable Multimodal Zero-Shot ECG Diagnosis via Structured Clinical Knowledge Alignment
Oct 24, 2025



Electrocardiogram (ECG) interpretation is essential for cardiovascular disease diagnosis, but current automated systems often struggle with transparency and generalization to unseen conditions. To address this, we introduce ZETA, a zero-shot multimodal framework designed for interpretable ECG diagnosis aligned with clinical workflows. ZETA uniquely compares ECG signals against structured positive and negative clinical observations, which are curated through an LLM-assisted, expert-validated process, thereby mimicking differential diagnosis. Our approach leverages a pre-trained multimodal model to align ECG and text embeddings without disease-specific fine-tuning. Empirical evaluations demonstrate ZETA's competitive zero-shot classification performance and, importantly, provide qualitative and quantitative evidence of enhanced interpretability, grounding predictions in specific, clinically relevant positive and negative diagnostic features. ZETA underscores the potential of aligning ECG analysis with structured clinical knowledge for building more transparent, generalizable, and trustworthy AI diagnostic systems. We will release the curated observation dataset and code to facilitate future research.
Unified Multi-task Learning for Voice-Based Detection of Diverse Clinical Conditions
Aug 28, 2025Voice-based health assessment offers unprecedented opportunities for scalable, non-invasive disease screening, yet existing approaches typically focus on single conditions and fail to leverage the rich, multi-faceted information embedded in speech. We present MARVEL (Multi-task Acoustic Representations for Voice-based Health Analysis), a privacy-conscious multitask learning framework that simultaneously detects nine distinct neurological, respiratory, and voice disorders using only derived acoustic features, eliminating the need for raw audio transmission. Our dual-branch architecture employs specialized encoders with task-specific heads sharing a common acoustic backbone, enabling effective cross-condition knowledge transfer. Evaluated on the large-scale Bridge2AI-Voice v2.0 dataset, MARVEL achieves an overall AUROC of 0.78, with exceptional performance on neurological disorders (AUROC = 0.89), particularly for Alzheimer's disease/mild cognitive impairment (AUROC = 0.97). Our framework consistently outperforms single-modal baselines by 5-19% and surpasses state-of-the-art self-supervised models on 7 of 9 tasks, while correlation analysis reveals that the learned representations exhibit meaningful similarities with established acoustic features, indicating that the model's internal representations are consistent with clinically recognized acoustic patterns. By demonstrating that a single unified model can effectively screen for diverse conditions, this work establishes a foundation for deployable voice-based diagnostics in resource-constrained and remote healthcare settings.