 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Robust Counterfactual Explanations via Conditional Gaussian Network Classifiers
Feb 08, 2026Counterfactual explanation (CE) is a core technique in explainable artificial intelligence (XAI), widely used to interpret model decisions and suggest actionable alternatives. This work presents a structure-aware and robustness-oriented counterfactual search method based on the conditional Gaussian network classifier (CGNC). The CGNC has a generative structure that encodes conditional dependencies and potential causal relations among features through a directed acyclic graph (DAG). This structure naturally embeds feature relationships into the search process, eliminating the need for additional constraints to ensure consistency with the model's structural assumptions. We adopt a convergence-guaranteed cutting-set procedure as an adversarial optimization framework, which iteratively approximates solutions that satisfy global robustness conditions. To address the nonconvex quadratic structure induced by feature dependencies, we apply piecewise McCormick relaxation to reformulate the problem as a mixed-integer linear program (MILP), ensuring global optimality. Experimental results show that our method achieves strong robustness, with direct global optimization of the original formulation providing especially stable and efficient results. The proposed framework is extensible to more complex constraint settings, laying the groundwork for future advances in counterfactual reasoning under nonconvex quadratic formulations.
Towards Robust Model Evolution with Algorithmic Recourse
Mar 12, 2025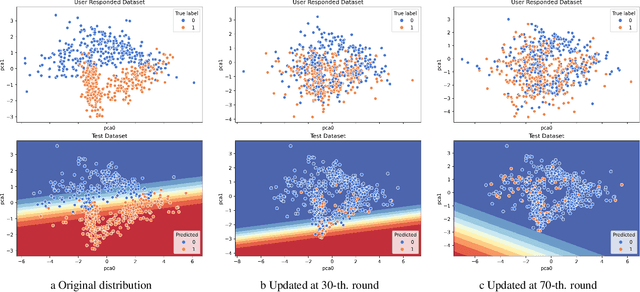
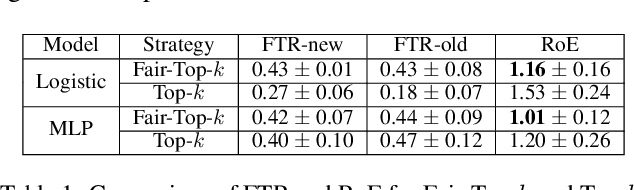
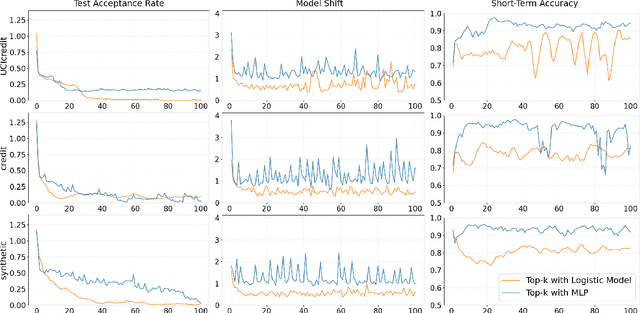
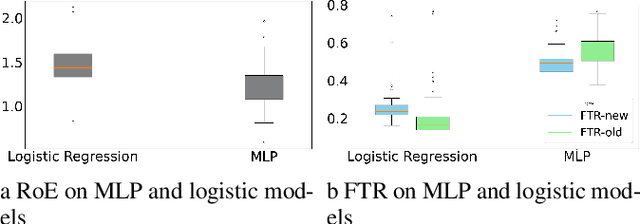
Algorithmic Recourse is a way for users to modify their attributes to align with a model's expectations, thereby improving their outcomes after receiving unfavorable decisions. In real-world scenarios, users often need to strategically adjust their attributes to compete for limited resources. However, such strategic behavior induces users to "game" algorithms, causing model collapse due to distribution shifts. These shifts arise from user competition, resource constraints, and adaptive user responses. While prior research on Algorithmic Recourse has explored its effects on both systems and users, the impact of resource constraints and competition over time remains underexplored. In this work, we develop a general framework to model user strategic behaviors and their interactions with decision-making systems under resource constraints and competitive dynamics. Through theoretical analysis and empirical evaluation, we identify three key phenomena that arise consistently in both synthetic and real-world datasets: escalating decision boundaries, non-robust model predictions, and inequitable recourse actions. Finally, we discuss the broader social implications of these findings and present two algorithmic strategies aimed at mitigating these challenges.
Pareto Optimal Algorithmic Recourse in Multi-cost Function
Feb 11, 2025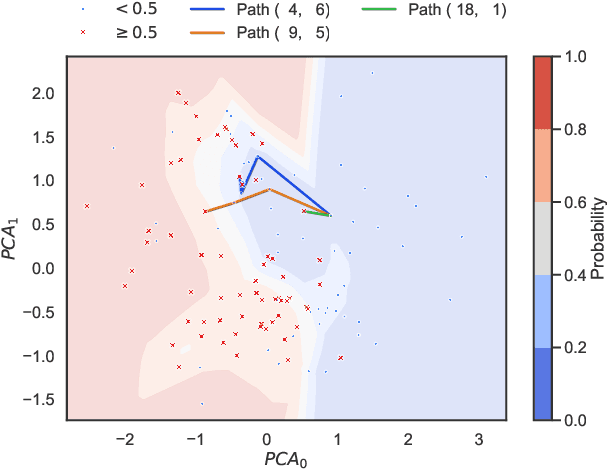

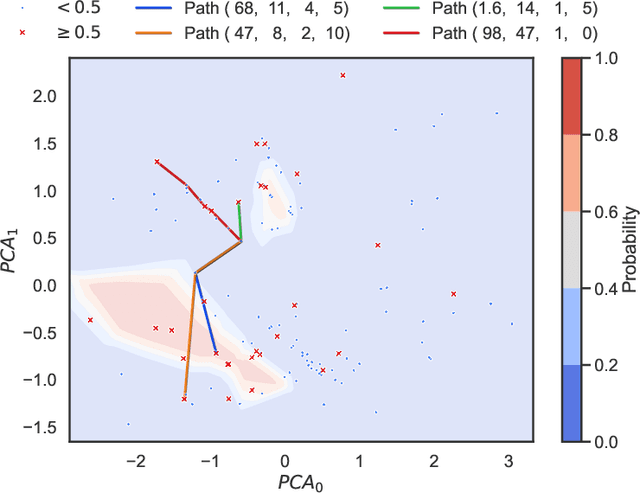
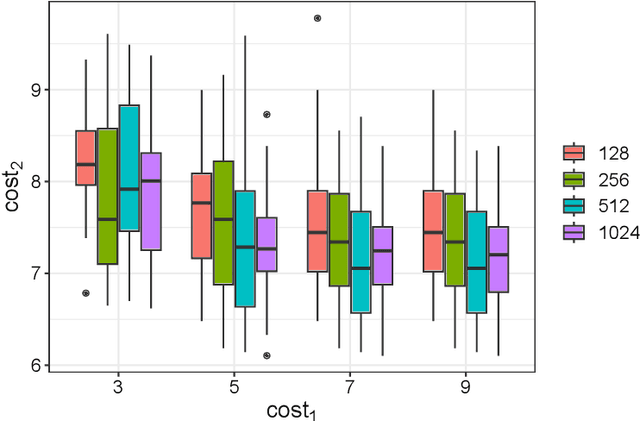
In decision-making systems, algorithmic recourse aims to identify minimal-cost actions to alter an individual features, thereby obtaining a desired outcome. This empowers individuals to understand, question, or alter decisions that negatively affect them. However, due to the variety and sensitivity of system environments and individual personalities, quantifying the cost of a single function is nearly impossible while considering multiple criteria situations. Most current recourse mechanisms use gradient-based methods that assume cost functions are differentiable, often not applicable in real-world scenarios, resulting in sub-optimal solutions that compromise various criteria. These solutions are typically intractable and lack rigorous theoretical foundations, raising concerns regarding interpretability, reliability, and transparency from the explainable AI (XAI) perspective. To address these issues, this work proposes an algorithmic recourse framework that handles non-differentiable and discrete multi-cost functions. By formulating recourse as a multi-objective optimization problem and assigning weights to different criteria based on their importance, our method identifies Pareto optimal recourse recommendations. To demonstrate scalability, we incorporate the concept of epsilon-net, proving the ability to find approximated Pareto optimal actions. Experiments show the trade-off between different criteria and the methods scalability in large graphs. Compared to current heuristic practices, our approach provides a stronger theoretical foundation and better aligns recourse suggestions with real-world requirements.
PXGen: A Post-hoc Explainable Method for Generative Models
Jan 21, 2025



With the rapid growth of generative AI in numerous applications, explainable AI (XAI) plays a crucial role in ensuring the responsible development and deployment of generative AI technologies. XAI has undergone notable advancements and widespread adoption in recent years, reflecting a concerted push to enhance the transparency, interpretability, and credibility of AI systems. Recent research emphasizes that a proficient XAI method should adhere to a set of criteria, primarily focusing on two key areas. Firstly, it should ensure the quality and fluidity of explanations, encompassing aspects like faithfulness, plausibility, completeness, and tailoring to individual needs. Secondly, the design principle of the XAI system or mechanism should cover the following factors such as reliability, resilience, the verifiability of its outputs, and the transparency of its algorithm. However, research in XAI for generative models remains relatively scarce, with little exploration into how such methods can effectively meet these criteria in that domain. In this work, we propose PXGen, a post-hoc explainable method for generative models. Given a model that needs to be explained, PXGen prepares two materials for the explanation, the Anchor set and intrinsic & extrinsic criteria. Those materials are customizable by users according to their purpose and requirements. Via the calculation of each criterion, each anchor has a set of feature values and PXGen provides examplebased explanation methods according to the feature values among all the anchors and illustrated and visualized to the users via tractable algorithms such as k-dispersion or k-center.
Patrol Security Game: Defending Against Adversary with Freedom in Attack Timing, Location, and Duration
Oct 21, 2024



We explored the Patrol Security Game (PSG), a robotic patrolling problem modeled as an extensive-form Stackelberg game, where the attacker determines the timing, location, and duration of their attack. Our objective is to devise a patrolling schedule with an infinite time horizon that minimizes the attacker's payoff. We demonstrated that PSG can be transformed into a combinatorial minimax problem with a closed-form objective function. By constraining the defender's strategy to a time-homogeneous first-order Markov chain (i.e., the patroller's next move depends solely on their current location), we proved that the optimal solution in cases of zero penalty involves either minimizing the expected hitting time or return time, depending on the attacker model, and that these solutions can be computed efficiently. Additionally, we observed that increasing the randomness in the patrol schedule reduces the attacker's expected payoff in high-penalty cases. However, the minimax problem becomes non-convex in other scenarios. To address this, we formulated a bi-criteria optimization problem incorporating two objectives: expected maximum reward and entropy. We proposed three graph-based algorithms and one deep reinforcement learning model, designed to efficiently balance the trade-off between these two objectives. Notably, the third algorithm can identify the optimal deterministic patrol schedule, though its runtime grows exponentially with the number of patrol spots. Experimental results validate the effectiveness and scalability of our solutions, demonstrating that our approaches outperform state-of-the-art baselines on both synthetic and real-world crime datasets.
Accelerated Shapley Value Approximation for Data Evaluation
Nov 09, 2023


Data valuation has found various applications in machine learning, such as data filtering, efficient learning and incentives for data sharing. The most popular current approach to data valuation is the Shapley value. While popular for its various applications, Shapley value is computationally expensive even to approximate, as it requires repeated iterations of training models on different subsets of data. In this paper we show that the Shapley value of data points can be approximated more efficiently by leveraging the structural properties of machine learning problems. We derive convergence guarantees on the accuracy of the approximate Shapley value for different learning settings including Stochastic Gradient Descent with convex and non-convex loss functions. Our analysis suggests that in fact models trained on small subsets are more important in the context of data valuation. Based on this idea, we describe $\delta$-Shapley -- a strategy of only using small subsets for the approximation. Experiments show that this approach preserves approximate value and rank of data, while achieving speedup of up to 9.9x. In pre-trained networks the approach is found to bring more efficiency in terms of accurate evaluation using small subsets.
Differentially Private Shapley Values for Data Evaluation
Jun 01, 2022
The Shapley value has been proposed as a solution to many applications in machine learning, including for equitable valuation of data. Shapley values are computationally expensive and involve the entire dataset. The query for a point's Shapley value can also compromise the statistical privacy of other data points. We observe that in machine learning problems such as empirical risk minimization, and in many learning algorithms (such as those with uniform stability), a diminishing returns property holds, where marginal benefit per data point decreases rapidly with data sample size. Based on this property, we propose a new stratified approximation method called the Layered Shapley Algorithm. We prove that this method operates on small (O(\polylog(n))) random samples of data and small sized ($O(\log n)$) coalitions to achieve the results with guaranteed probabilistic accuracy, and can be modified to incorporate differential privacy. Experimental results show that the algorithm correctly identifies high-value data points that improve validation accuracy, and that the differentially private evaluations preserve approximate ranking of data.
On Cyclic Solutions to the Min-Max Latency Multi-Robot Patrolling Problem
Mar 14, 2022
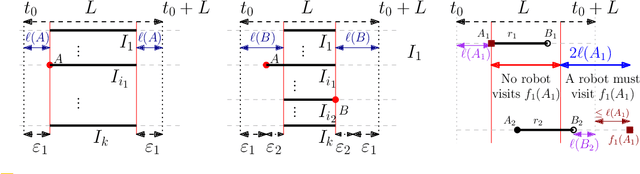
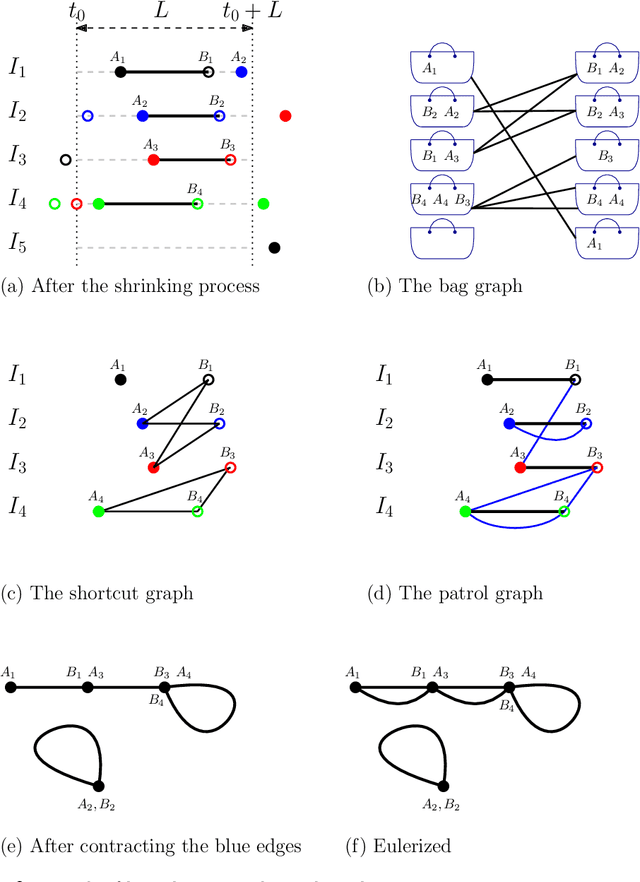
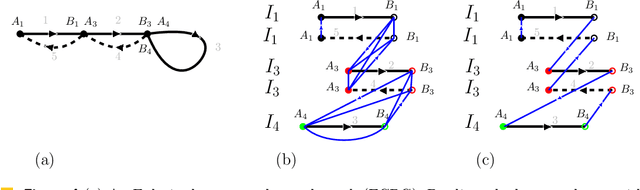
We consider the following surveillance problem: Given a set $P$ of $n$ sites in a metric space and a set of $k$ robots with the same maximum speed, compute a patrol schedule of minimum latency for the robots. Here a patrol schedule specifies for each robot an infinite sequence of sites to visit (in the given order) and the latency $L$ of a schedule is the maximum latency of any site, where the latency of a site $s$ is the supremum of the lengths of the time intervals between consecutive visits to $s$. When $k=1$ the problem is equivalent to the travelling salesman problem (TSP) and thus it is NP-hard. We have two main results. We consider cyclic solutions in which the set of sites must be partitioned into $\ell$ groups, for some~$\ell \leq k$, and each group is assigned a subset of the robots that move along the travelling salesman tour of the group at equal distance from each other. Our first main result is that approximating the optimal latency of the class of cyclic solutions can be reduced to approximating the optimal travelling salesman tour on some input, with only a $1+\varepsilon$ factor loss in the approximation factor and an $O\left(\left( k/\varepsilon \right)^k\right)$ factor loss in the runtime, for any $\varepsilon >0$. Our second main result shows that an optimal cyclic solution is a $2(1-1/k)$-approximation of the overall optimal solution. Note that for $k=2$ this implies that an optimal cyclic solution is optimal overall. The results have a number of consequences. For the Euclidean version of the problem, for instance, combining our results with known results on Euclidean TSP, yields a PTAS for approximating an optimal cyclic solution, and it yields a $(2(1-1/k)+\varepsilon)$-approximation of the optimal unrestricted solution. If the conjecture mentioned above is true, then our algorithm is actually a PTAS for the general problem in the Euclidean setting.
The Shapley Value in Machine Learning
Feb 11, 2022
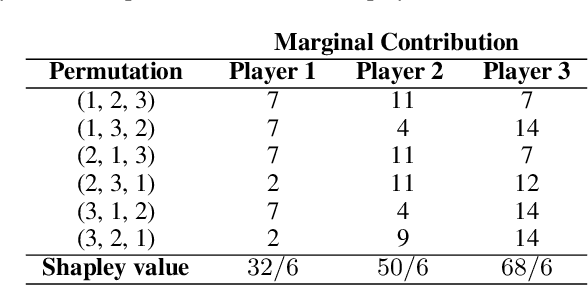
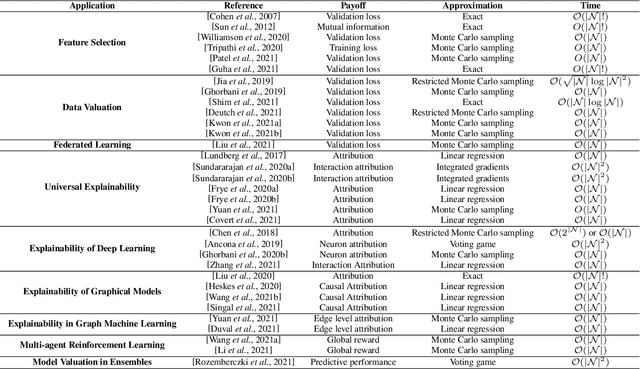
Over the last few years, the Shapley value, a solution concept from cooperative game theory, has found numerous applications in machine learning. In this paper, we first discuss fundamental concepts of cooperative game theory and axiomatic properties of the Shapley value. Then we give an overview of the most important applications of the Shapley value in machine learning: feature selection, explainability, multi-agent reinforcement learning, ensemble pruning, and data valuation. We examine the most crucial limitations of the Shapley value and point out directions for future research.
Approximation Algorithms for Multi-Robot Patrol-Scheduling with Min-Max Latency
May 23, 2020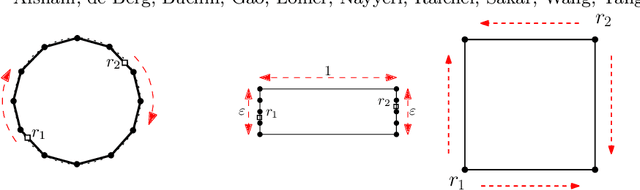
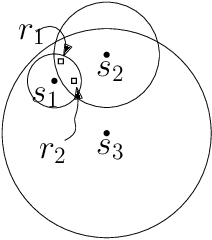
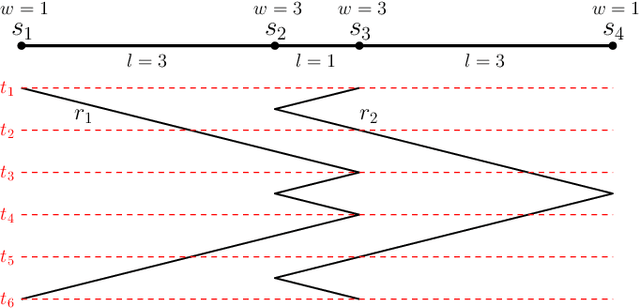
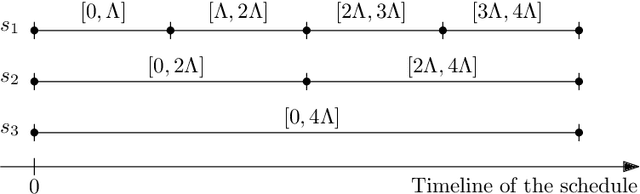
We consider the problem of finding patrol schedules for $k$ robots to visit a given set of $n$ sites in a metric space. Each robot has the same maximum speed and the goal is to minimize the weighted maximum latency of any site, where the latency of a site is defined as the maximum time duration between consecutive visits of that site. The problem is NP-hard, as it has the traveling salesman problem as a special case (when $k=1$ and all sites have the same weight). We present a polynomial-time algorithm with an approximation factor of $O(k^2 \log \frac{w_{\max}}{w_{\min}})$ to the optimal solution, where $w_{\max}$ and $w_{\min}$ are the maximum and minimum weight of the sites respectively. Further, we consider the special case where the sites are in 1D. When all sites have the same weight, we present a polynomial-time algorithm to solve the problem exactly. If the sites may have different weights, we present a $12$-approximate solution, which runs in polynomial time when the number of robots, $k$, is a constant.